
HDFS High Availability(HA)高可用配置
高可用性(英语:high availability,缩写为 HA)
IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。 高可用性系统意味着系统服务可以更长时间运行,通常通过提高系统的容错能力来实现。高可用性或者高可靠度的系统不会希望有单点故障造成整体故障的情形。 一般可以透过冗余的方式增加多个相同机能的部件,只要这些部件没有同时失效,系统(或至少部分系统)仍可运作,这会让可靠度提高。
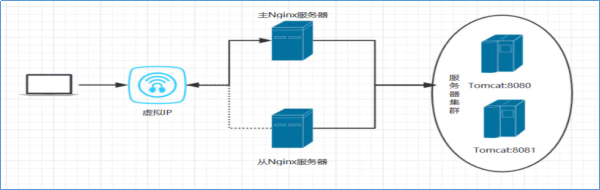
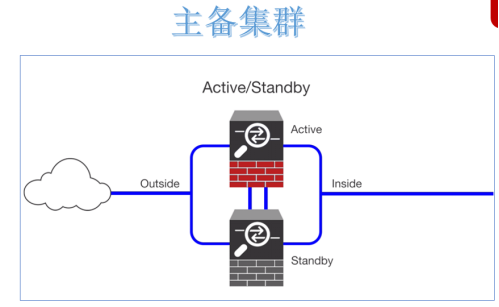
解决单点故障,实现系统服务高可用的核心并不是让故障永不发生,而是让故障的发生对业务的影响降到最小。因为软硬件故障是难以避免的问题。 当下企业中成熟的做法就是给单点故障的位置设置备份,形成主备架构。通俗描述就是当主挂掉,备份顶上,短暂的中断之后继续提供服务。 常见的是一主一备架构,当然也可以一主多备。备份越多,容错能力越强,与此同时,冗余也越大,浪费资源。
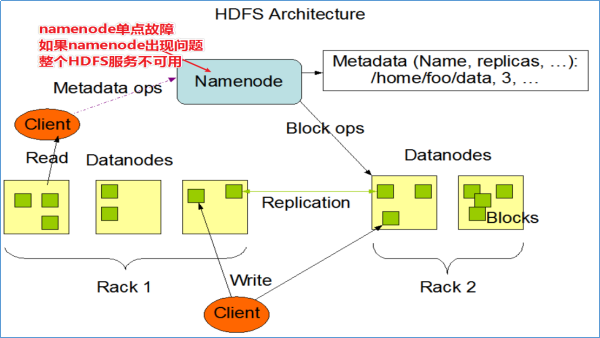
1-HDFS NAMENODE单点故障问题
在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。每个群集只有一个NameNode,如果该计算机或进程不可用,则整个群集在整个NameNode重新启动或在另一台计算机上启动之前将不可用。
NameNode的单点故障从两个方面影响了HDFS群集的总可用性:
- 如果发生意外事件(例如机器崩溃),则在重新启动NameNode之前,群集将不可用。
- 计划内的维护事件,例如NameNode计算机上的软件或硬件升级,将导致群集停机时间的延长。
HDFS高可用性解决方案:在同一群集中运行两个(从3.0.0起,超过两个)冗余NameNode。在机器崩溃的情况下快速故障转移到新的NameNode,或者出于计划维护的目的由管理员发起的正常故障转移。
2-HDFS HA解决方案—QJM
QJM全称Quorum Journal Manager,由cloudera公司提出,是Hadoop官方推荐的HDFS HA解决方案之一。
QJM中,使用zookeeper中ZKFC来实现主备切换;使用Journal Node(JN)集群实现edits log的共享以达到数据同步的目的。
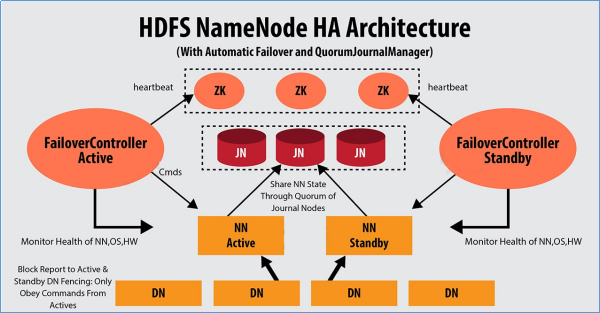
2.1-QJM—主备数据同步问题解决
Journal Node(JN)集群是轻量级分布式系统,主要用于高速读写数据、存储数据。通常使用2N+1台JournalNode存储共享Edits Log(编辑日志)。

任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录edits log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取JN里面的edits log,然后重演操作记录同步到自己的目录镜像树里面,
当发生故障Active NN挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
3-集群基础环境准备
配置三台主机
1.修改Linux主机名 /etc/hostname,修改和服务器名称对应,如node1配置。
vim /etc/hostname
node12.修改IP /etc/sysconfig/network-scripts/ifcfg-ens33
3.修改主机名和IP的映射关系 /etc/hosts
vim /etc/hosts
4.关闭防火墙参考文章(https://www.cnblogs.com/LaoPaoEr/p/16273501.html)
5.SSH免密登录/集群时间同步参考文章(https://www.cnblogs.com/LaoPaoEr/p/16273456.html)
6.安装java的JDK,配置环境变量等 /etc/profile(请自行百度)。
7.Zookeeper的集群环境搭建(自行百度)。
3.1-Ha集群规划

在三台主机上分别创建目录:
mkdir -p /opt/export/server/
mkdir -p /opt/export/data/
mkdir -p /opt/export/software/
3.2-上传解压Hadoop安装包
自行复制链接下载:http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/hadoop-3.1.4.tar.gz
解压命令:
cd /opt/export/software
tar -zxvf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /opt/export/server/3.3-在三台主机配置Hadoop环境变量
vim /etc/profile
#adoop高可用的节点配置文件
export HADOOP_HOME=/opt/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 
node1配置profile完成后分发配置给node2,node3
cd /etc
scp -r /etc/profile root@node2:$PWD
scp -r /etc/profile root@node3:$PWD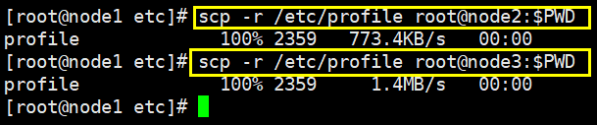
三台配置完之后一定要:
source /etc/profile3.4-修改Hadoop配置文件
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim hadoop-env.sh增加配置:
JAVA_HOME=/export/server/jdk1.8.0_60 这里配置自己服务器java的JDK的版本
export JAVA_HOME=/export/server/jdk1.8.0_60
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root在node1上创建数据存放目录,JournalNode数据的存放目录:
mkdir -p /opt/export/server/hadoop-3.1.4/data
mkdir -p /opt/export/server/hadoop-3.1.4/qj_data编辑core-site.xml
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim core-site.xml在<configuration></configuration>之间添加配置
<!-- HA集群名称,该值要和hdfs-site.xml中的配置保持一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- hadoop本地磁盘存放数据的公共目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/export/server/hadoop-3.1.4/data</value>
</property>
<!-- ZooKeeper集群的地址和端口-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
编辑hdfs-site.xml
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim hdfs-site.xml在<configuration></configuration>之间添加配置
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/export/server/hadoop-3.1.4/qj_data</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>编辑workers
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim workers
#配置工作主机
node1
node2
node33.5-集群同步安装包
在node2和node3服务器上创建目录 /opt/export/server
ssh node2
mkdir -p /opt/export/server
ssh node3
mkdir -p /opt/export/server分发到node2和node3,使用scp前需要提前配好免密登录。
cd /opt/export/server
scp -r hadoop-3.1.4 root@node2:$PWD
scp -r hadoop-3.1.4 root@node3:$PWD4-HA集群初始化
4.1-启动zk集群
这一步需要存在ZK集群。配置好ZK集群的环境变量。
zkServer.sh start
zkServer.sh status4.2-手动启动JN集群
在三台主机(node1\node2\node3)上都要执行:
hdfs --daemon start journalnode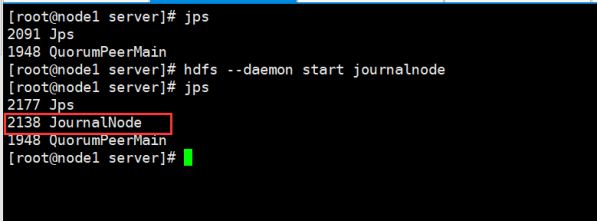
4.3-格式化Format namenode
在node1执行格式化namenode:
在node1启动namenode进程:
hdfs namenode -format
hdfs --daemon start namenode在node2上进行namenode元数据同步
hdfs namenode -bootstrapStandby4.4-格式化zkfc
注意:在哪台机器上执行,哪台机器就将成为第一次的Active NN
hdfs zkfc -formatZK5- HA集群启动
在node1上启动HDFS集群
start-dfs.sh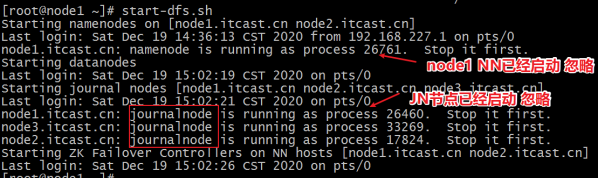
网页访问
node1:9870
node2:9870
选择菜单Overview ,可以看到Node1已经启动成功。
Overview 'node1:8020' (active)代表是主节点

Overview 'node2:8020' (standby)代表从节点

通过kill杀死node1的NameNode。重新刷新node1和node2网页 可以查看node2以切换为主节点。
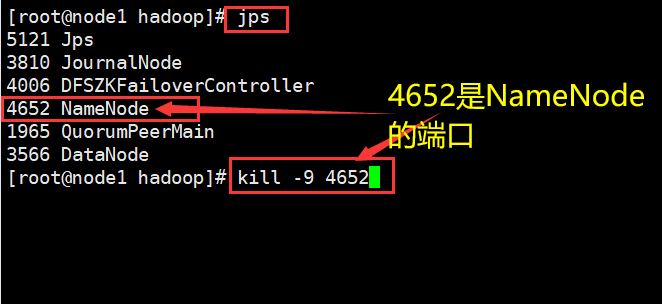
本篇遗憾是还未搭建Yarn调度集群。只是简单搭建了HDFS的集群,具体Yarn搭建后,后期更新进入文章内。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号