


论文查重
| 这个作业的要求在哪里 | 第一次项目作业 |
|---|---|
| 这个作业的目标 | 实现论文查重,消除警告及改进 |
| 其他 |
看完论文查重作业的相关要求之后,最开始想到的便是对比两篇文章出现关键字的字频,因此我们需要先对文章进行分词处理,处理问之后再用相似度算法进行计算
1.查重论文的读取(包括被查文件以及数据库文件)
开始第一步,对文本进行读取及分词,网上有多个分词包及数据库,但实际应用下来发现错误还是不少的,无法运行,如jiebacpp是一个再Linux系统下运行的一个分词包,然而我使用的是windows,因此便放弃了这一分词包,选择hanlp,但hanlp同样存在问题,他是一个网页分词,无法支持我对原文本进行分词文件输出的想法。最后我选择的是一个正向最大匹配算法,这个算法其实网上是存在源码的,但实际理解起来也不难,就是从文本从头到尾依次截取5个字,再对比词典,如果词典中存在,就确定这5个字是一个词,如果不存在则去掉5个字中最末尾的一个,变4个字,在比较,以此类推,最后如果只剩1个字,那它便是一个词。
然后这里存在一个问题,便是词典,这里我因为尝试过jiebacpp,所以我直接用了它的词典。
这里是相应代码,汉字占两个字节,因此while循环里面的len应-2.
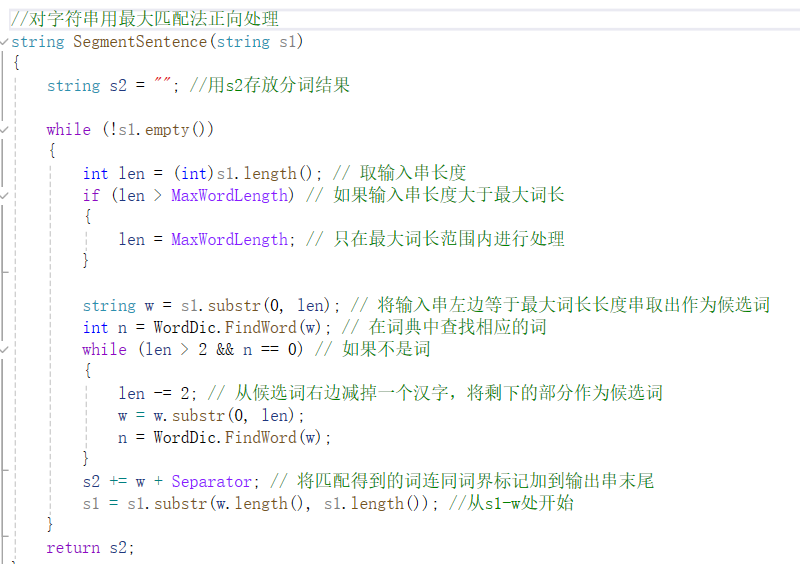
在这段核心代码之前,只需要读取文件,在代码之后,则进行写入输出文件就行了。
原文本分词结果

2.计算关键字的字频
计算词频用的主要是递归算法,通过对上面分词的读取进行统计写入。若遇到新词则输出该词以及记词频为1,所遇到已有的词,则对该词词频+1;从而得出一个词频文件。
关键代码

原文本词频统计

3.根据字频计算相似度
这一步还包含了一个合并去重的步骤,因为在使用向量法对比两个文本相似度的时候,需要将两个向量所指相同,因此在原文本中未出现但在抄袭文本中出现的词,需要在原文本词频中加入该词并且词频设为0;将两个文本合并去重后就是计算向量了,这里需要对两个文本的值暂存如vector中,并将文本进行映射转换,转换为向量后就可以利用余弦相似度算法进行计算了。
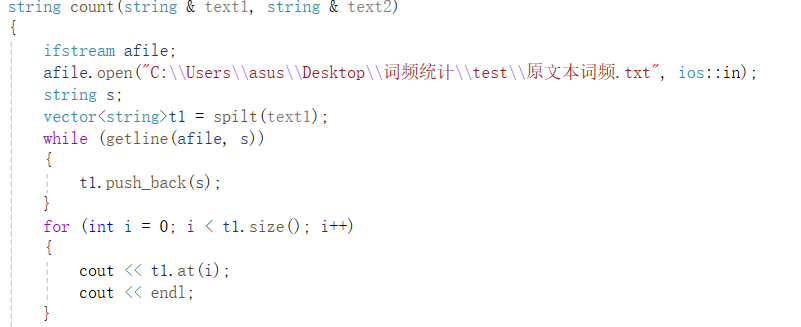
同样代码将文件改为抄袭文本词频打开即可
关键代码

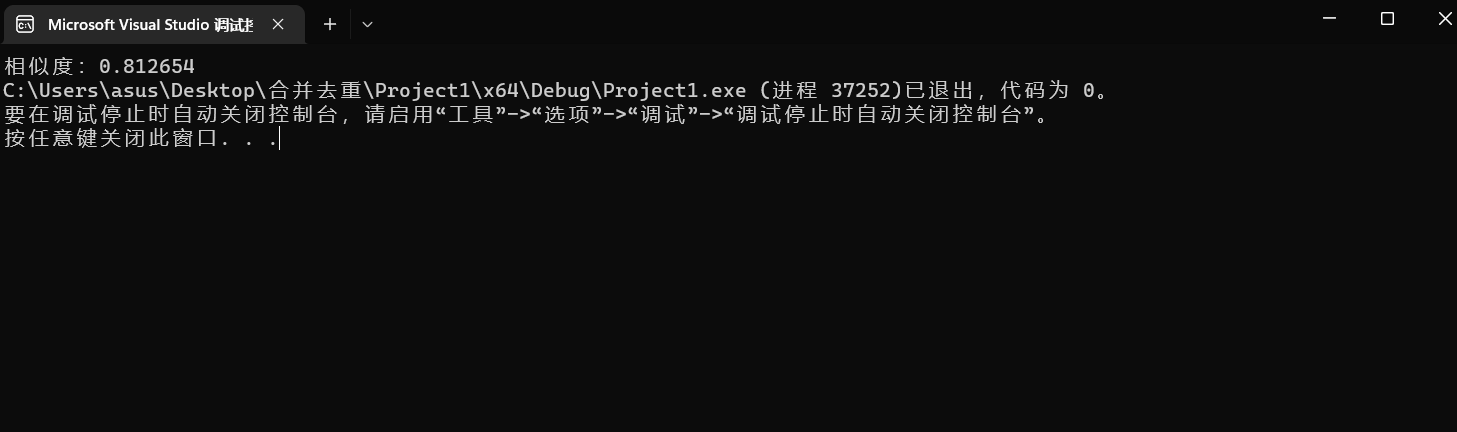
4.输出相似度结果
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 400 | 1340 |
| Development | 开发 | 100 | 600 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 300 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 10 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 30 | 120 |
| Code Review | 代码复审 | 10 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 20 | 30 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 400 | 1340 |

