
Python3下载豆瓣音乐人小站音乐
[本文出自天外归云的博客园]
下载蓝天祐的豆瓣音乐播放列表中的音乐:https://site.douban.com/RU/widget/playlist/13762211/
上代码:
# -*- coding: utf-8 -*- import requests, os from bs4 import BeautifulSoup site_domain = "https://site.douban.com" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400', 'Connection': 'keep-alive', 'Cookie': 'bid=7lwwg4Ypdzs; _pk_id.100001.917b=380808dc951fc71d.1616738808.1.1616738808.1616738808.; __utmz=30149280.1616738809.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); dbcl2="41592591:H13ejog3tB8"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.4159; __utma=30149280.1177554564.1616738809.1616738809.1616742488.2; __gads=ID=14740104f4e3bfee:T=1616743894:S=ALNI_MYwu3_3texfLgBXlMtMOZHMxmi0aA; ck=Agzc' } def download_mp3(session, download_url, mp3_name): r = session.get(url=download_url, headers=headers) if not os.path.exists('music'): os.mkdir('music') with open("music/" + mp3_name + ".mp3", "wb") as code: code.write(r.content) def download_douban_songs(playlist_url, debug=False): s = requests.Session() r = s.get(f"{site_domain}{playlist_url}", headers=headers) html = r.text soup = BeautifulSoup(html, features="html5lib") if debug: print(soup.prettify()) tables = soup.findAll(name="table", attrs={"class": "playlist"}) target_table = tables[0] if debug: print(target_table) trs = target_table.find_all("tr") for tr in trs: if "song_id" not in tr.attrs: continue song_id = tr["song_id"] song_name = tr.find_all(name="td", attrs={"class": "title"})[0].text.strip().strip("\n") download_url = f"{site_domain}{playlist_url}/download?song_id={song_id}" print(song_id, song_name, download_url) download_mp3(s, download_url, song_name) if __name__ == '__main__': download_douban_songs(playlist_url="/RU/widget/playlist/13762211")
运行结果:
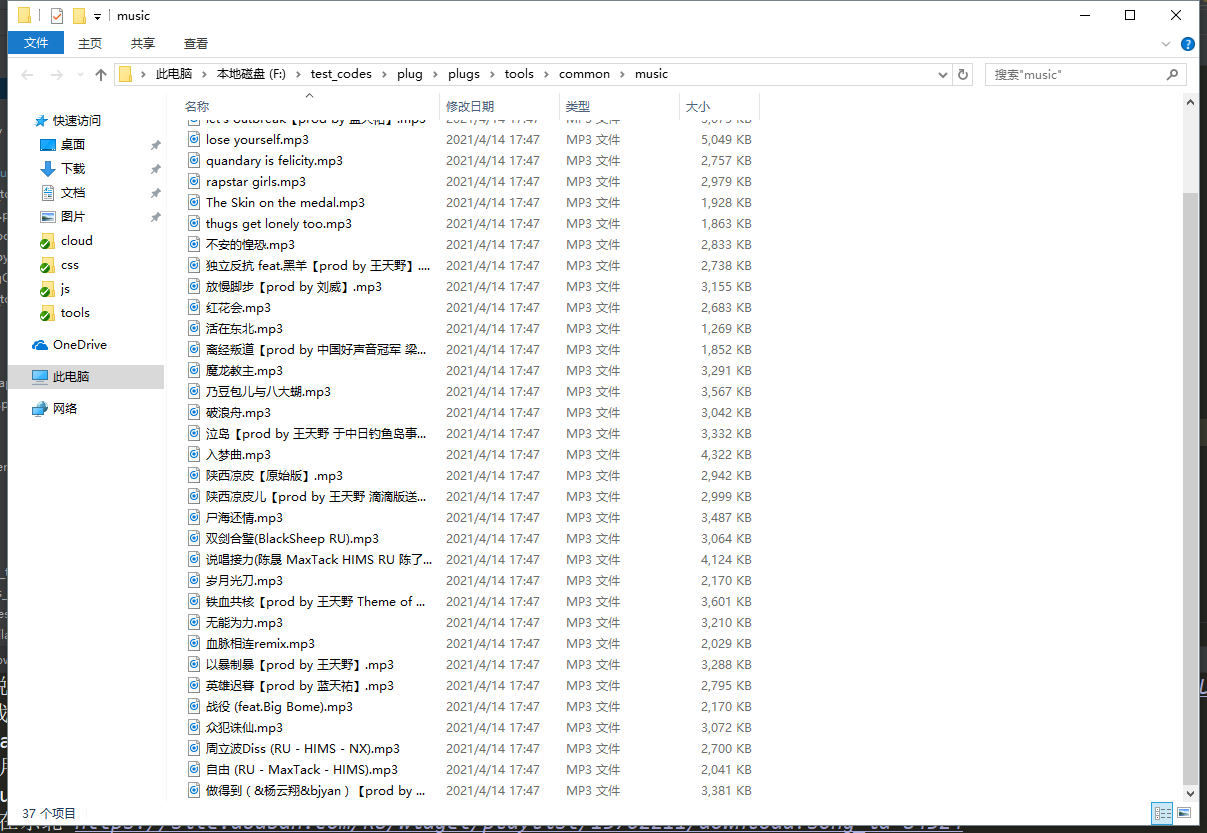
看看下载的音乐,完美!
本文来自博客园,作者:天外归云,转载请注明原文链接:https://www.cnblogs.com/LanTianYou/p/14593082.html

