
【Java】类集
核心接口
Collection、List、Set、Map、Iterator、Enumeration、Queue、ListIterator
Collection接口
java.util.Collection是单值集合操作的最大的父接口,在该接口之中定义有所有的单值数据的处理操作。
核心操作方法:
| No | 方法名称 | 描述 |
|---|---|---|
| 1 | public boolean add(E e) | 向集合中添加数据 |
| 2 | public boolean addAll(Collection<?extends E> c) | 向集合中添加一组数据 |
| 3 | public void clear() | 清空集合 |
| 4 | public boolean contains(Object o); | 查找数据是否存在,需要使用equals()方法 |
| 5 | public-boolean remove(Object o); | 删除数据,需要equals()方法 |
| 6 | publicint size0(); | 取得集合长度 |
| 7 | public Obiect[] toArray(); | 将集合变为对象数组返回 |
| 8 | public lterator |
将集合变成Iterator接口 |
最常用的两个方法:add()数据添加,iterator()输出。
在实际的开发中往往考虑使用Collection的子接口:List和Set。
List接口
允许保存有重复元素。List拥有的方法比Collection中的要多。
| No | 方法名称 | 描述 |
|---|---|---|
| 1 | public E get(int index); | 获取指定索引上的数据 |
| 2 | public E set(int index,E element); | 修改指定索引数据 |
| 3 | public ListIterator |
返回ListIterator接口对象 |
由于List本身还是接口,要想取得接口的实例化对象,就必须有子类,在List接口下有三个常用子类:ArrayList(实际开发占90%)、Vector、LinkedList。
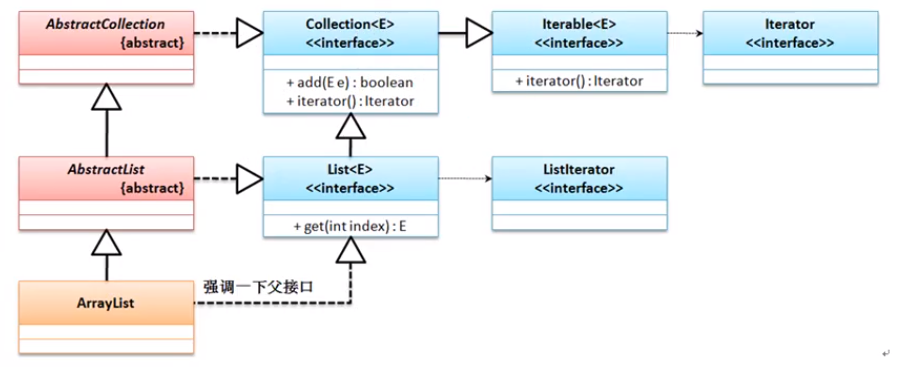
ArrayList子类
ArrayList的继承结构:
常用方法代码:
List<String> list = new ArrayList<String>();//无参构造
List<String> list2 = new ArrayList<String>(10);//有参构造,参数为容量
list.add("Hello");//添加数据
list.size();//返回list长度
list.isEmpty();//判断list是否为空
list.remove("Hello");//移除第一个“Hello”
list.contains("ABC");//判断是否存在“ABC”
list.get(2);//返回下标为2的元素
ArrayList封装了数组。如果进行数据追加的时候,如果ArrayList长度不够,就会进行新的数组开辟(以2倍扩容),并进行拷贝。
在JDK1.9之后,无参是默认的空数组,使用的时候才会开辟空间。
在JDK1.9之前,无参是开辟为10的数组。
List存储特征:
- 保存的顺序就是其存储顺序。
- List集合里面允许存在有重复数据。
在使用List操作自定义类对象的时候,如果需要使用到contains(),remove()方法进行查询与删除处理的时候一定要保证已经成功覆写equals()方法。
class Person{
private String name;
private int age;
@Override
public boolean equals(Object obj) {
if(this == obj){
return true;
}
if(obj == null){
return false;
}
if(!(obj instanceof Person)){
return false;
}
Person per = (Person)obj;
return this.name.equals(per.name) && this.age == per.age;
}
}
LinkedList子类
该子类的使用方法与ArrayList一致。
ArrayList与LinkedList区别:
- ArrayList封装的是数组;LinkedList封装的是链表。
- ArrayList时间复杂度为O(1),而LinkedList的复杂度为O(n)。
Vector子类(一般不会用)
Set接口
Set接口中不允许重复内容。Set接口并没有对Collection接口进行扩充,而List对Collection进行了扩充。因此,在Set接囗中没有get()方法。
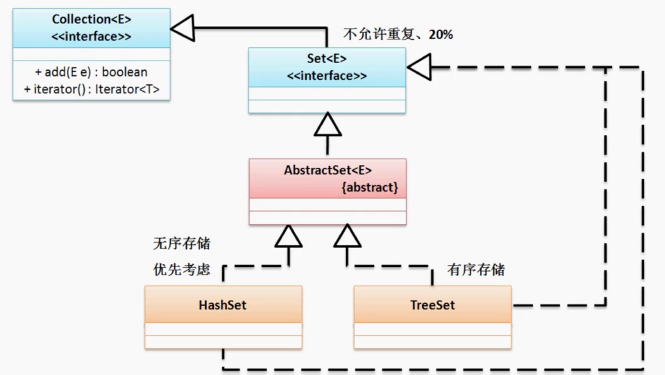
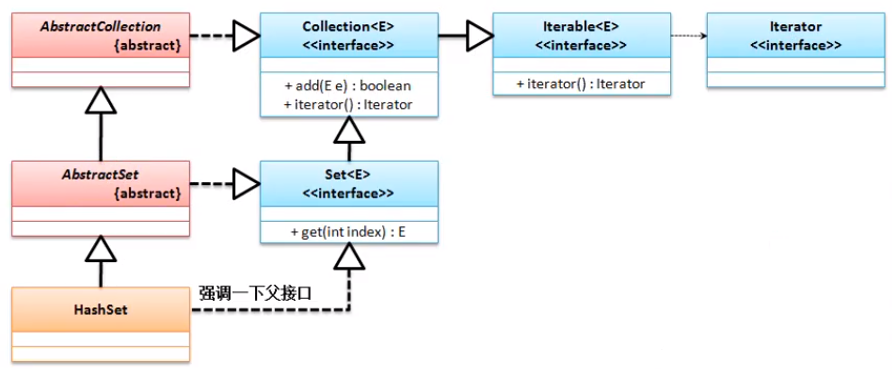
HashSet(无序存储)
保存的数据是无序的。
HashSet的继承结构:
HashSet判重的方法是依靠Object类中的两个方法:
- hash码:public native int hashCode();
- 对象比较:public boolean equals(Object obj);
在Java中进行对象比较的操作有两步:
- 先利用hashCode()进行编码的匹配。
- 再调用equals()方法进行内容的比较。
必须两个方法equals()、hashCode()返回值都相同才判断为相同。
class Person implements Comparable<Person>{
private String name;
private int age;
@Override
public int hashCode() {
return Objects.hash(name,age);
}
@Override
public boolean equals(Object obj) {
if(this == obj){
return true;
}
if(obj == null || getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return Objects.equals(name,person.name) && Objects.equals(age,person.age);
}
}
方法与上述类似。
TreeSet(有序存储)
TreeSet使用升序排列。
如果想要利用TreeSet对自定义类进行排序就需要在对象所在的类里是实现Comparable接口,并覆盖compareTo()方法。(原因:TreeSet本质是利用TreeMap子类实现存储,而TreeMap就需要Comparable来确定大小关系)
class Person implements Comparable<Person>{
private String name;
private int age;
@Override
public int compareTo(Person o) {
if(this.age > o.age){
return 1;
}else if(this.age < o.age){
return -1;
}else {
return this.name.compareTo(o.name);
}
}
}
由于如果类的属性太多,那么compareTo的比较就太多了,所以一般使用HashSet。
集合的输出
Iterator迭代输出(95%)
在Iterator接口里有如下方法:
| No | 方法名称 | 描述 |
|---|---|---|
| 1 | public boolean hasNext() | 判断是否有下一个数据 |
| 2 | public E next() | 取出当前数据 |
| 3 | public default void remove() | 删除(除非必要不要用) |
public class JavaList {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("Hello");
list.add("Java");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String str = iterator.next();
System.out.println(str);
}
}
}
对如remove()方法,如果在迭代里使用Collection集合的remove方法会导致迭代失败。只有使用Iterator里的remove才不会产生异常。
Listiterator双向迭代输出
public class JavaList {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("Hello");
list.add("Java");
System.out.println("从前向后输出");
ListIterator<String> listIterator = list.listIterator();
while(listIterator.hasNext()){
System.out.println(listIterator.next());
}
System.out.println("从后向前输出");
while(listIterator.hasPrevious()){
System.out.println(listIterator.previous());
}
}
}
并且如果要想实现由后向前的输出,那么必须先进行从前向后的输出,否则就会失败。
Enumeration枚举输出
该方式只能够依靠Vector子类。
public class JavaList {
public static void main(String[] args) {
Vector<String> vector = new Vector<>();
vector.add("Hello");
vector.add("World");
vector.add("Test");
Enumeration<String> enumeration = vector.elements();
while(enumeration.hasMoreElements()){
System.out.println(enumeration.nextElement());
}
}
}
foreach输出
public class JavaList {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("Hello");
list.add("Java");
for (String str: list) {
System.out.println(str);
}
}
}
Map集合
Map会以K-V键值对的形式来保存数据。
用户可采用自定义类作为key。但一定要记得覆写Object类的hashCode()与equals()方法。
public interface Map<K,V>;
常用方法:
| No | 方法名称 | 描述 |
|---|---|---|
| 1 | public V put(K key,V value); | 向Map中追加数据。 |
| 2 | public V get(object key); | 根据key取得对应的value,如果没有返回null |
| 3 | public Set |
取得所有key信息、key不能重复 |
| 4 | public Collection |
取得所有value信息,可以重复 |
| 5 | public Set<Map.Entry<K,V>> entrySet(); | 将Map集合变为Set集合 |
HashMap子类
public class JavaMap {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"Hello");
map.put(2,"World");
map.put(2,"Java");//由于K值相同,所以会进行覆盖保留最后一个
map.put(3,"Map");
System.out.println(map);
System.out.println(map.get(2));
System.out.println(map.get(10));//查不到返回null
Set<Integer> set = map.keySet();
Iterator<Integer> iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
Collection<String> collection = map.values();
Iterator<String> iterator1 = collection.iterator();
while(iterator1.hasNext()){
System.out.println(iterator1.next());
}
Set<Map.Entry<Integer,String>> set1 = map.entrySet();
Iterator<Map.Entry<Integer,String>> iterator2 = set1.iterator();
while(iterator2.hasNext()){
Map.Entry<Integer,String> entry = iterator2.next();//取出每一个Map.Entry对象
System.out.println(entry.getKey()+" = "+entry.getValue());
}
}
}
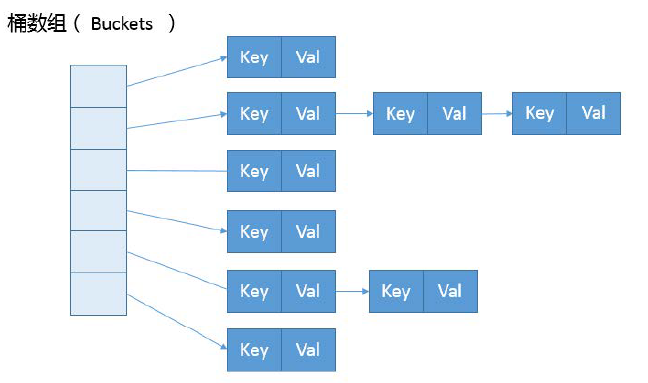
HashMap内部实现点分析:
HashMap内部结构可以看作是数组和链表的解和。数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;哈希值相同的键值对,则以链表形式存储。如果链表大小超过属值(TREEIFY_THRESHOLD,8),图中的链表就会被改造为树形结构。
Hashtable子类
使用方法与HashMap类似。
区别:
| No | 区别 | HashMap | Hashtable |
|---|---|---|---|
| 1 | 推出版本 | JDK1.2 | JDK1.0 |
| 2 | 性能 | 异步处理,性能高 | 同步处理,性能低 |
| 3 | 安全性 | 非线程安全 | 线程安全 |
| 4 | null操作 | 允许存放null | K-V都不允许出现null |
TreeMap子类
TreeMap是一个可排序的Map子类,它是按照Key的内容排序的。
栈与队列
Stack栈
先进后出
public class JavaStack {
public static void main(String[] args) {
Stack<String> stack = new Stack<>();
stack.push("A");//入栈
stack.push("B");
System.out.println(stack.push("C"));//虽然也可以打印,但是没意义
System.out.println(stack.peek());//栈顶元素
System.out.println(stack.pop());//出栈元素
}
}
Queue队列
先进先出
Queue是一个接口,所以其实现需要依靠LinkedList。
public class JavaQueue {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<>();
queue.add("A");
queue.add("B");
System.out.println(queue.peek());
System.out.println(queue.poll());
}
}
Collections工具类
public class JavaList {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
Collections.addAll(list,"L","O","V","E");//添加元素
Collections.reverse(list);//反转
Collections.sort(list);//排序
Collections.shuffle(list);//打乱顺序
Collections.binarySearch(list,"L");//二分查找
Collections.max(list);
Collections.min(list);
Collections.fill(list,"a");//用a替换list中所有元素
List<String> list1 = new ArrayList<String>();
Collections.addAll(list,"A","B","C","D");
Collections.copy(list,list1);//将集合list1中的元素全部复制到list中,并且覆盖相应索引的元素
}
}
总结:
//排序操作(主要针对List接口相关)
reverse(List list):反转指定List集合中元素的顺序
shuffle(List list):对List中的元素进行随机排序(洗牌)
sort(List list):对List里的元素根据自然升序排序
sort(List list, Comparator c):自定义比较器进行排序
swap(List list, int i, int j):将指定List集合中i处元素和j出元素进行交换
rotate(List list, int distance):将所有元素向右移位指定长度,如果distance等于size那么结果不变
//查找和替换(主要针对Collection接口相关)
binarySearch(List list, Object key):使用二分搜索法,以获得指定对象在List中的索引,前提是集合已经排序
max(Collection coll):返回最大元素
max(Collection coll, Comparator comp):根据自定义比较器,返回最大元素
min(Collection coll):返回最小元素
min(Collection coll, Comparator comp):根据自定义比较器,返回最小元素
fill(List list, Object obj):使用指定对象填充
frequency(Collection Object o):返回指定集合中指定对象出现的次数
replaceAll(List list, Object old, Object new):替换
Stream数据流
主要是针对集合里数据进行分析处理。
而在Java类集中,由于其本身的作用就可以进行大量数据的存储,所以就顺其自然的产生了MapReduce操作,而这些操作可以通过Stream数据流来完成。
针对大数据问题,暂不考虑。

