


问题:
1、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。 在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决: 1.缓存空结果、并且设置短的过期时间。
2.使用布隆过滤器(待看)
2、缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决: 原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
stringRedisTemplate.opsForValue().set("catalogJson", valueJson, 1, TimeUnit.DAYS);
像设置了随机时间但是数据量大的时候,每一个时间点也有很多key时,其面对的问题和缓存击穿是一样的问题。
3、缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决: 加锁
4.分布式锁的演变
首先我们容易想到的是为程序添加一个synchronized,通过判断缓存中是否已经有数据来判断是否需要查询数据库。
而加上synchronized后,所有线程会百分百抢占锁,从而使得效率变低,所以,当有线程判断到缓存中没有数据时,会对其进行更新,其他的线程就不必要加入抢占的行列,我们对其进行双重检测dcl(doublechecklock)

if(!StringUtil.isEmpty(redisData)){ synchronized(this){ if(!StringUtil.isEmpty(redisData)){ // 数据存在直接返回 return redisData; } // 数据不存在查询 数据库数据 // 将其写入redis并且返回数据。 } }
然而这是本地锁,在分布式项目中,该锁只能保证本服务的数据安全,在有多个服务时,并且所更新数据读和写需要强一致性的时候,就需要分布式锁。
redis文档: http://www.redis.cn/commands.html
在redis中有命令setnx,是可以用来做分布式锁,在redistemplate中是setifabsent,与set不同的是,当输入的key不存在的时候,才会去占用,否则就不会占用。
set lock 1 nx
然而这个锁是非阻塞的,所以需要自旋,这种会导致方法栈溢出。
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() { //1、占分布式锁。去redis占坑 设置过期时间必须和加锁是同步的,保证原子性(避免死锁) String uuid = UUID.randomUUID().toString(); Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid,300, TimeUnit.SECONDS);
// 将占锁与设置时间变成原子操作 if (lock) { System.out.println("获取分布式锁成功...");
String lockvalue = redis.get("lock");
if(uuid.equals(lockvalue)){
redisTemplate.delete("lock");
return dataFromDb;
} else { System.out.println("获取分布式锁失败...等待重试..."); //加锁失败...重试机制 //休眠一百毫秒 try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } return getCatalogJsonFromDbWithRedisLock(); //自旋的方式 } }
这种情况在执行业务代码时突然宕机,则锁会一直被占用,导致所有线程阻塞。这个时候需要手动删除锁。
假设场景1:当线程1占用了锁,但是业务时间为30s而锁的时间为10s,当锁过期后线程2,占用了锁,10s后线程3占用了锁这时线程1运行完毕,删除了所有的锁。(使用uuid)
假设场景2:如上,当有线程1判断自己的锁是否为自己的uuid时,传输过程中,key过期了,这时,线程2抢占了锁,并且线程1判断通过又删除了锁,此时线程2的锁就会被线程1 删除。
解决方法:在redis官方文档中已经说明,这时,判断和删除的操作可以做成原子操作,使用lua脚本(分布式锁篇):
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
则在java中对应的执行如下:
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() { //1、占分布式锁。去redis占坑 设置过期时间必须和加锁是同步的,保证原子性(避免死锁) String uuid = UUID.randomUUID().toString(); Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid,300, TimeUnit.SECONDS); if (lock) { System.out.println("获取分布式锁成功..."); Map<String, List<Catelog2Vo>> dataFromDb = null; try { //加锁成功...执行业务 dataFromDb = getDataFromDb(); } finally { String script = "if redis.call('get',
KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; //删除锁 stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),
Arrays.asList("lock"), uuid); } //先去redis查询下保证当前的锁是自己的 //获取值对比,对比成功删除=原子性 lua脚本解锁 // String lockValue = stringRedisTemplate.opsForValue().get("lock"); // if (uuid.equals(lockValue)) { // //删除我自己的锁 // stringRedisTemplate.delete("lock"); // } return dataFromDb; } else { System.out.println("获取分布式锁失败...等待重试..."); //加锁失败...重试机制 //休眠一百毫秒 try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } return getCatalogJsonFromDbWithRedisLock(); //自旋的方式 } }
5.redisson
在redis官方文档中有关于分布式锁的具体实现,可以布通过原始的lua语法来控制锁
文档:https://github.com/redisson/redisson/wiki/8.-%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%92%8C%E5%90%8C%E6%AD%A5%E5%99%A8
在分布式锁中,所有的锁默认时间为30秒,30秒之后自动解锁,所有的锁在生成后都会启动一个定时任务,当业务时间超过30秒时,该定时任务会每10秒钟刷新一次过期时间,保证业务的执行和锁的安全。(lockWatchdogTimeout = 30 * 1000)
public String hello() { //1、获取一把锁,只要锁的名字一样,就是同一把锁 RLock myLock = redisson.getLock("my-lock"); //2、加锁 myLock.lock(); try { System.out.println("加锁成功,执行业务..." +
Thread.currentThread().getId()); try { TimeUnit.SECONDS.sleep(20); }
catch (InterruptedException e) { e.printStackTrace(); } } catch (Exception ex) { ex.printStackTrace(); } finally { //3、解锁 假设解锁代码没有运行,Redisson会不会出现死锁 System.out.println("释放锁..." + Thread.currentThread().getId()); myLock.unlock(); } return "hello"; }
在分布式系统中,保存数据的一致性有两种模式
1。双写模式
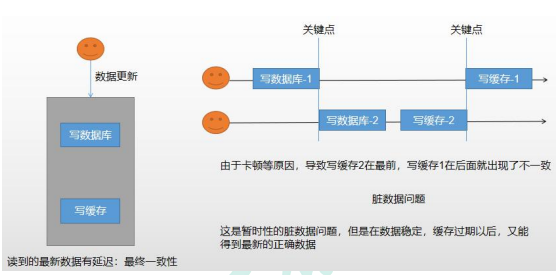
2.失效模式
每次更新数据的时候,删除redis中的数据,直到下一次访问时更新数据。
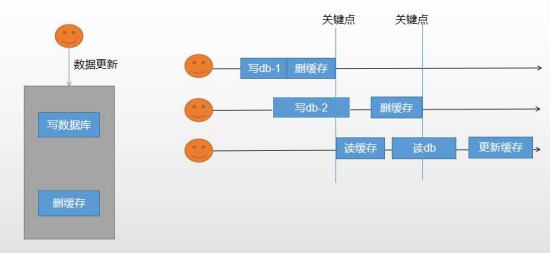
3。分布式读写锁。
在读和写的整个操作时间都对其加上读写锁,保证写操作不会影响到读的数据。
public String writeValue() { String s = ""; RReadWriteLock readWriteLock = redisson.getReadWriteLock("rw-lock"); RLock rLock = readWriteLock.writeLock(); try { //1、改数据加写锁,读数据加读锁 rLock.lock(); s = UUID.randomUUID().toString(); ValueOperations<String, String> ops = stringRedisTemplate.opsForValue(); ops.set("writeValue",s); TimeUnit.SECONDS.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } finally { rLock.unlock(); } return s; } public String readValue() { String s = ""; RReadWriteLock readWriteLock = redisson.getReadWriteLock("rw-lock"); //加读锁 RLock rLock = readWriteLock.readLock(); try { rLock.lock(); ValueOperations<String, String> ops = stringRedisTemplate.opsForValue(); s = ops.get("writeValue"); try { TimeUnit.SECONDS.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } } catch (Exception e) { e.printStackTrace(); } finally { rLock.unlock(); } return s; }
其他redisson模型:
信号量:
当所指定的信号量数就为可同时访问的线程数,该模型可以用来做服务熔断。
public String park() throws InterruptedException { RSemaphore park = redisson.getSemaphore("park"); park.acquire(); //获取一个信号、获取一个值,占一个车位 boolean flag = park.tryAcquire(); if (flag) { //执行业务 } else { return "error"; } return "ok=>" + flag; }
public String go() {
RSemaphore park = redisson.getSemaphore("park");
park.release(); //释放一个车位
return "ok";
}
闭锁:
当指定的闭锁个数后,只有对应的线程数占用了锁,才会释放锁,wait会一直阻塞,知道闭锁完成
public String lockDoor() throws InterruptedException { RCountDownLatch door = redisson.getCountDownLatch("door"); door.trySetCount(5); door.await(); //等待闭锁完成 return "放假了..."; } public String gogogo(@PathVariable("id") Long id) { RCountDownLatch door = redisson.getCountDownLatch("door"); door.countDown(); //计数-1 return id + "班的人都走了..."; } }
额外补充:
springcache:
/** * 级联更新所有关联的数据 * * @CacheEvict:失效模式 * @CachePut:双写模式,需要有返回值 * 1、同时进行多种缓存操作:@Caching * 2、指定删除某个分区下的所有数据 @CacheEvict(value = "category",allEntries = true) * 3、存储同一类型的数据,都可以指定为同一分区 * @param category */ /** * 每一个需要缓存的数据我们都来指定要放到那个名字的缓存。【缓存的分区(按照业务类型分)】 * 代表当前方法的结果需要缓存,如果缓存中有,方法都不用调用,如果缓存中没有,会调用方法。最后将方法的结果放入缓存 * 默认行为 * 如果缓存中有,方法不再调用 * key是默认生成的:缓存的名字::SimpleKey::[](自动生成key值) * 缓存的value值,默认使用jdk序列化机制,将序列化的数据存到redis中 * 默认时间是 -1: * * 自定义操作:key的生成 * 指定生成缓存的key:key属性指定,接收一个Spel * 指定缓存的数据的存活时间:配置文档中修改存活时间 * 将数据保存为json格式 * * * 4、Spring-Cache的不足之处: * 1)、读模式 * 缓存穿透:查询一个null数据。解决方案:缓存空数据 * 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的;使用sync = true来解决击穿问题 * 缓存雪崩:大量的key同时过期。解决:加随机时间。加上过期时间 * 2)、写模式:(缓存与数据库一致) * 1)、读写加锁。 * 2)、引入Canal,感知到MySQL的更新去更新Redis * 3)、读多写多,直接去数据库查询就行 * * 总结: * 常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache):写模式(只要缓存的数据有过期时间就足够了) * 特殊数据:特殊设计 * * 原理: * CacheManager(RedisCacheManager)->Cache(RedisCache)->Cache负责缓存的读写 * @return */


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix