

一。render内部原理。
在render中往往需要返回三个参数,request,模板和一些键值对。
键值对中存储的是需要对模板渲染的值。
如果手动实现可以如下:
from django.template import Template,Context def index(request): temp = Template('<h1>{{ user }}</h1>') con = Context({"user":{"name":'jason',"password":'123'}}) res = temp.render(con) print(res) return HttpResponse(res)
首先拿到模板,再用render对模板进行渲染,最后使用字符串的形式返回。
二。FBV和CBV
FBV(function base view)
CBV(class base view)
一个是基于函数编写的视图,一个是基于类编写的视图。
对于基于函数编写的就是运行其返回的值,也就是三个渲染模板函数产生的值。
而基于类编写的,需要运行视图函数中的一个内置类函数产生的函数,本质是一个闭包函数。
编写类函数:
from django.views import View class MyLogin(View): def get(self,request): print("from MyLogin get方法") return render(request,'login.html') def post(self,request): return HttpResponse("from MyLogin post方法")
编写url:
url(r'^login/',views.MyLogin.as_view())
可以看到其中需要调用mylogin中运行自己编写的类中的as_view函数。然而这个函数是继承的VIew中的函数。
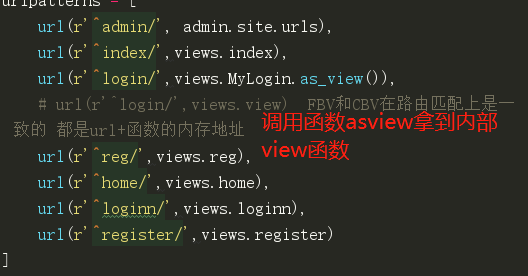
as_view
as_view是一个绑定类方法的函数。除了正常的异常处理之外,其内部有一个闭包函数,也就是说调用这个函数之后产生的结果就是这个view函数的返回值。

当url匹配成功后,会调用view方法,在view内部返回的是一个使用自定义函数产生的的对象中的dispatch方法(继承父类View的方法)。
也就说dispatch产生的值就是最终返回的值。也就是渲染的页面。dispatch中会首先判断你的请求是否是属于8个基本请求之一。如果是就通过这个字符串和自身定义的类产生的对象,getattr获取对应的函数,最后通过这个函数运行得到渲染的模板返回。
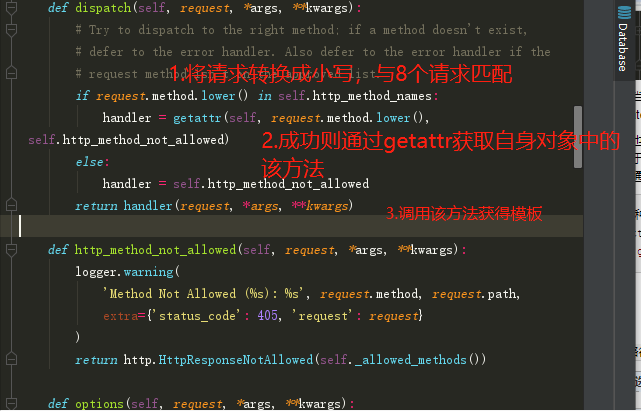
八种请求:
http_method_names =
['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
三。django中settings源码。
对于django中的settings是提供给我们配置文件用的,除了大写的变量之外,其他变量都没有效果,所以其内部会经过独特的处理。
其实,在django框架中有一个全局的配置文件,暴露给用户的settings是很小的一部分,其调用方法如下:
from django.conf import settings
首先介绍os.environ。这相当于一个全局的字典,可以支持字典取值设置值的任何方法。其次介绍dir方法,dir可以将一个模块中的所有变量名取出。
在django启动时,会直接运行manage.py文件,这个文件会先将暴露给用户的settings路径,以变量名:DJANGO_SETTINGS_MODULE为键,加入全局字典中。
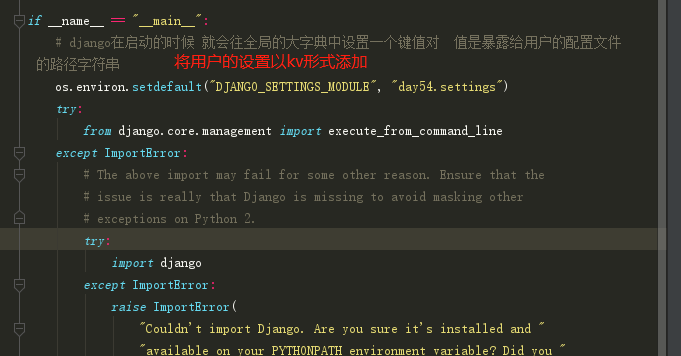
在settings方法内部就是一个单例模式,每当调用settings时,会返回一个对象LazySettings()
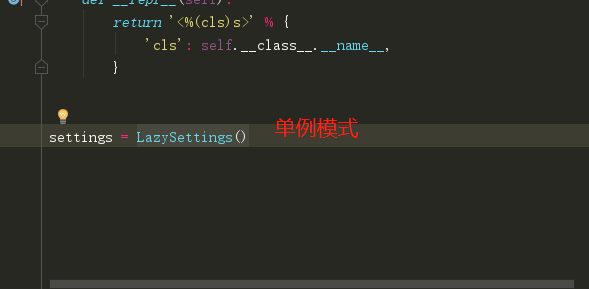
在LazySettings()内部,首先从全局字典中获取暴露给用户的settings的字符串,将其传给settings方法进行配置。

settings方法首先使用dir方法和for循环获取全局设置中的所有配置,如果是大写就添加到他产生的对象中,也就是调用模块时。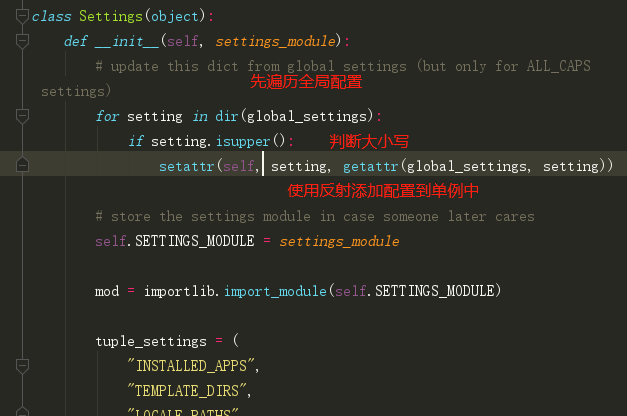
接着再调用用户配置的settings,使用字符串调用模块。同样使用for循环。如果本来的设置中存在就覆盖其值,没有则新建。

也就是说会优先使用用户的设置。
四。模板层之传递值。
当我们使用视图函数向模板传值时,一般都使用字典的方式。
def index(request): return render(requset,'html',{'名字‘:’数据‘})
然而当有多个值的时侯,单个传值显然很麻烦,通过locals()方法,可以将该函数中的所有参数传递给前端:
def index(request):
return render(request,'reg.html',locals())
虽然locals()方法可以一劳永逸,但是会浪费资源,会传递前端不要的参数。
传入的值如果数python的数据类型几乎都可以被渲染,但是也有特殊的:
1.函数。
如果传函数名,会自动加括号调用该函数,前端展示的是函数调用之后的返回值。
注意:如果函数需要参数的话 那么模板语法不支持。
2.类。
如果将类实例化对象传给前端,会将该对象的内存地址传入,前端页面可以通过该对象名点出其中的函数方法和变量。
其中的函数也不支持传参。
模板语法:
{{}} 变量相关。
{%%}语法相关。
五。模板语法过滤器。
过滤器的固定语法是:
{{ 变量名|过滤器名 }}
其内部原理是,将|前面的变量名当成过滤器的第一个参数传入。
@register.filter(is_safe=False) def length(value): """Returns the length of the value - useful for lists.""" try: return len(value) except (ValueError, TypeError): return 0
如果不支持该过滤器,会返回0
1。{{ l|length }}
统计l的长度。
2。{{ ss|default:'当|左边的变量为空就会返回|右边的值' }}
如果ss存在,则返回ss,如果为空则返回default,如果ss不存在也返回他,和get很像。
3。{{ file_size|filesizeformat }}
将file_size转换成文件大小。
4。{{ info|truncatewords:3 }}
按照空格将info文字进行截断,3是截断的个数。
5。{{ info|truncatechars:6 }}
按照字符截取info,点也算,也就是至少传入3。
6。{{ xxx|safe }}
一般的,xxx字符串传入前端后,直接以字符串的形式传入,但是加上safe之后,就会将xxx按照原来的意思进行输入,如果该字符是页面元素,会显示页面元素。
后端可以取消这个机制:
from django.utils.safestring import mark_safe zzz=make_safe('内容')
7.{{ ctime|date:'Y-m-d H-i-s' }}
如果后端传来的ctime是一个时间类型的数据,那么可以通过过滤器date进行渲染。
8.{{ n|add:100 }}
将n数字加100,如果是字符串,则拼接字符串。
9.{{ l|slice:'0:5:2' }}
将1切片,故头不顾尾,支持步长
六。模板层之标签。
标签也就是逻辑相关的操作,使用{% %}
1.forloop。
在for循环中,这个标签可以记录for循环的一些值:
{% for foo in l %}
<p>{{ forloop }}</p>
{% endfor %}
如图:

2.{%empty%}
当for 循环为空,则执行这个标签下的方法。
3.if判断:
{% if '' %}
<p>xxx条件为true</p>
{% else %}
<p>xxx条件为false</p>
{% endif %}
4.点。
django模板语法在取值的时候 统一使用句点符。如:
{ l.6.3.name }
5.{%with 数据 as 别名%}
可以通过这个标签给数据取别名,这样可以方便操作。在with中就可以使用该别名。
{% with l.6.3.name as ttt %}
{{ ttt }}
{{ l.6.3.name }}
{% endwith %}
6.for循环中字典的三个方法:
{% for foo in d.keys %}
<p>{{ foo }}</p>
{% endfor %}
{% for foo in d.values %}
<p>{{ foo }}</p>
{% endfor %}
{% for foo in d.items %}
<p>{{ foo }}</p>
{% endfor %}
七。自定义过滤器与标签。
自定义的东西需要遵循下面三个步骤:
1.必须在你的应用下新建一个名为templatetags文件夹
2.在该文件夹内新建一个任意名称的py文件
3.在该py文件中固定先写下面两句代码
from django import template
register = template.Library()
然后就可以在这个文件下面编写字节的过滤器了:
@register.filter(name='baby') def index(a,b): # 该过滤器只做一个加法运算 是|add简易版本 return a + b
定义的时候需要给它取个别名,然后要阿紫网页中调用该过滤器。
{% load mytag %}
{{ 123|baby:1}}
其中mytag是template下的文件名,baby是起的名字。
注意,自定义guolq只能指定两个形参,但是第二个参数可以是一个列表。
自定义标签
标签的定义方法和guolvq差不多:
@register.simple_tag(name='jason') def xxx(a,b,c,year): return '%s?%s|%s{%s'%(a,b,c,year)
但是标签支持传入多个参数,标签的使用:
支持传多个参数 参数与参数之间 空格隔开即可、 {% load mytag %} {% jason 1 2 3 year=2 %}
也支持关键字传参。
自定义inclusion_tag
这个工作原理是接受用户传入的参数,然后根据参数渲染出一个页面,再返回到调用inclusion_tag的地方。
定义方法:
# 自定义inclusion_tag @register.inclusion_tag('bigplus.html') def bigplus(n): l = [] for i in range(n): l.append('第%s项'%i) return {'l':l}
它需要指定一个页面,这个页面是要被调用的页面,会接受这个函数返回的值。

调用:
{% load mytag %}
{% bigplus 5 %}
应用场景:
可以定义一个多次运用的页面,可以反复调用。
八。模板的继承和导入。
继承:
当多个页面整体的样式都大差不差的情况下 可以设置一个模板文件。
在该模板文件中 使用block块划分多个预期。
之后子版在使用模板的时候 可以通过block块的名字 来选定到底需要修改哪一部分区域
也就是说,母模板中可以将需要改变的地方通过{% block css%} {% endblock%}划分页面。
{% block css %}
子页面自己的css代码
{% endblock %}
{% block content %}
子页面自己的html代码
{% endblock %}
{% block js %}
子页面自己的js代码
{% endblock %}
这个名字是自己定义的。
在其他页面可以继承这个母模板进行复用:
# 模板的继承 使用方式 {% extends 'home.html' %} {% block css %} <style> h1 { color: red; } </style> {% endblock %}
通过{{ block.super}} 也可以获得目标签该区域的元素
一般情况下 模板上的block越多 页面的可扩展性就越强。
模板的导入:
{% include 'beautiful.html' %}
将一个静态的页面,通过导入的方式加入模板。
九。模型层。
1.单表操作。
create_time = models.DateField()
创建时间的这个参数有关键性的参数。
1.auto_now:每次操作数据 都会自动刷新当前操作的时间
2.auto_now_add:在创建数据的时候 会自动将创建时间记录下来 后续的修改不会影响该字段
增:
方法1:
book_obj = models.Book.objects.\
create(title='三国',price=19.99,create_time='2019-11-11')
方法2:
方式2:对象点save()方法 from datetime import datetime ctime = datetime.now() book_obj = models.Book(title='金',price=96.66,create_time=ctime) book_obj.save()
查:
models.Book.objects.all() #查询所有的数据 models.Book.objects.get(id=1) #按照id查询 models.Book.objects.get(pk=1) #自动按照主键查询
改:
1.update models.Book.objects.filter(pk=1).update(title='三国演义') 2.对象.save() book_obj = models.Book.objects.get(pk=1) book_obj.price = 666.66 book_obj.save()
删:
删除 delete()
models.Book.objects.filter(pk=2).delete()
其他的函数方法:
(1) all():
查询所有结果
(2)filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
(3)get(**kwargs):
返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。(源码就去搂一眼~诠释为何只能是一个对象)
(4)exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
print(models.Book.objects.exclude(pk=1)) # 只要pk不是1的数据全部查询出来
(5) order_by(*field): 对查询结果排序('-id') / ('price')
print(models.Book.objects.order_by('price')) # 默认是升序 print(models.Book.objects.order_by('-price')) # 加负号就是降序
(6) reverse(): 对查询结果反向排序 >> > 前面要先有排序才能反向
print(models.Book.objects.order_by('price').reverse())
(7) count(): 返回数据库中匹配查询(QuerySet)
print(models.Book.objects.count()) # 对查询出来的结果进行一个计数的对象数量。
(8) first(): 返回第一条记录print(models.Book.objects.filter(pk=1).first())
(9) last(): 返回最后一条记录
print(models.Book.objects.all()) print(models.Book.objects.all().last())
(10) exists(): 如果QuerySet包含数据,就返回True,否则返回False
print(models.Book.objects.filter(pk=1000)) print(models.Book.objects.filter(pk=1000).exists())
补充:
1.如果一个类中的函数时绑定类方法,而使用对象调用,会获取对象的类,当成第一个参数传入。
2。通过字符串导入模块的方法:
import importlib mod = importlib.import_module(从哪个模块中,’所调用的模块的字符串‘)
3.在django中可以写一个单独的test模块进行测试。:
import os import sys if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day54.settings") import django django.setup() #下面导入模块进行测试。
