

一。一对多
在数据库使用数据中经常遇到一对多的情况,以公司员工为例。
一张完整的员工表有以下字段:
id name gender dep_name dep_desc .
以此建表得:
id name gender dep_name dep_desc 1 jason male 教学部 教书育人 2 egon male 外交部 漂泊游荡 3 tank male 教学部 教书育人 4 kevin male 教学部 教书育人 5 owen female 技术部 技术能力有限部门
少数的数据看不出有多大的不合理,但是如果一个公司中频繁有教学部的出现,它和它的描述就要反复写一遍,这种感觉就像一个py文件写下了所有的代码,这本身就是不合理的,为了像模块一样封装代码,我们先将其分成2个表,再使用一对多的关系关联两表:
emp: id name gender dep_id 1 jason male 1 2 egon male 2 3 tank male 2 4 kevin male 2 5 owen female 3
dep id dep_name dep_desc 1 教学部 教书育人 2 外交部 漂泊游荡 3 教学部 教书育人 4 教学部 教书育人 5 技术部 技术能力有限部门
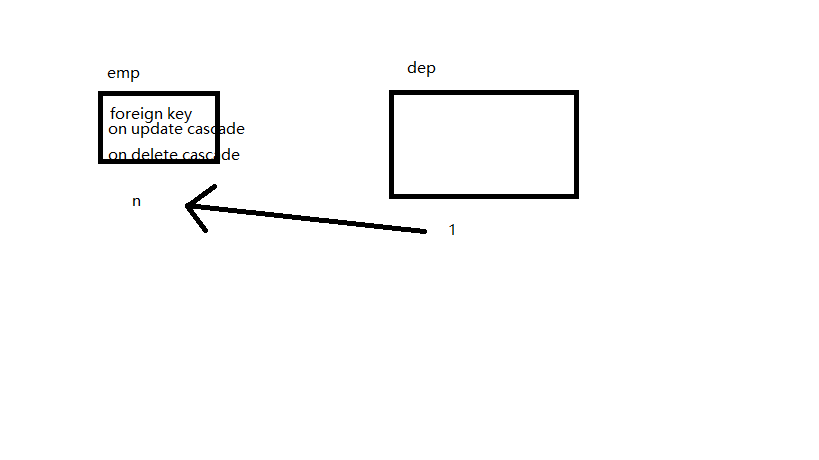
两张表唯一有关系的是dep_id,所以要将dep_id设置成外键。
设置外键是在表的创建阶段就完成的工作,一般的,我们把外键设置在一对多的多那个表中:
create table dep( id int primary key auto_increment, dep_name char(10), dep_comment char(60) ); create table emp( id int primary key auto_increment, name char(16), gender enum('male','female') not null default 'male', dep_id int, foreign key(dep_id) references dep(id) );
在插入记录时,必须先插入被关联的表,也就是dep,在插入emp的数据。
这样的表当dep中 的数据emp使用时,它的数据是不能被删除的,为了使得两者具有同步性,使用on delete cascade 修饰外键:
create table dep( id int primary key auto_increment, dep_name char(10), dep_comment char(60) ); create table emp( id int primary key auto_increment, name char(16), gender enum('male','female') not null default 'male', dep_id int, foreign key(dep_id) references dep(id) on update cascade on delete cascade );
如图:
二。多对多
除了一对多的概念以外,还有多对多,如图书和作者的关系。
一个作者可以发布多个书。
一个书可以有多个作者。
于是根据上述的1对多推理出可以这样建立:
create table book( id int primary key auto_increment, title varchar(32), price int, author_id int, foreign key(author_id) references author(id) on update cascade # 同步更新 on delete cascade # 同步删除 ); create table author( id int primary key auto_increment, name varchar(32), age int, book_id int, foreign key(book_id) references book(id) on update cascade # 同步更新 on delete cascade # 同步删除 );
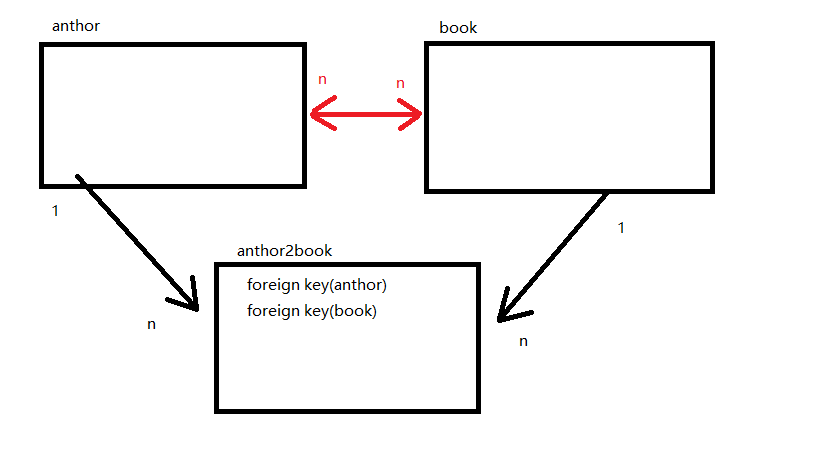
结果肯定是错的,建表book是让关联author,建表author时让关联book,两个谁都不能先建立肯定时不行的。
所以需要第三张表,来记录它们之间的关系。
create table book( id int primary key auto_increment, title varchar(32), price int ); create table author( id int primary key auto_increment, name varchar(32), age int ); create table book2author( id int primary key auto_increment, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, author_id int, foreign key(author_id) references author(id) on update cascade on delete cascade );
如图:
三。一对一
一对一的使用场景是当数据库特别庞大时,可以考虑分表。
分表后使用一对一的关系将其连接起来。
首先先建立被关联的表,再建立关联表,外键可以设置再任何地方,但一般设置在访问比较的的那个表。
create table authordetail1( id int primary key auto_increment, phone int, addr char(255) );
create table author1( id int primary key auto_increment, name char(4), age int, authordetail_id int unique, foreign key(authordetail_id) references authordetail1(id) on update cascade on delete cascade );
四,表修改
# mysql对大小写不敏感!!! 语法: 1. 修改表名 ALTER TABLE 表名 RENAME 新表名; 2. 增加字段 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; 3. 删除字段 ALTER TABLE 表名 DROP 字段名; 4. 修改字段 # modify只能改字段数据类型完整约束,不能改字段名,但是change可以! ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
五。表复制
# 查询语句执行的结果也是一张表,可以看成虚拟表 # 复制表结构+记录 (key不会复制: 主键、外键和索引) create table new_service select * from service; # 只复制表结构 select * from service where 1=2; //条件为假,查不到任何记录 create table new1_service select * from service where 1=2; create table t4 like employees;
