一。线程池
线程池是一个处理线程任务的集合,他是可以接受一定量的线程任务,并创建线程,处理该任务,处理结束后不会立刻关闭池子,会继续等待提交的任务,也就是他们的进程/线程号不会改变。
当线程池中的任务没有结束时是不会接受下一个任务的。
它的操作有:
pool = ThreadPoolExecutor()
创建一个线程池,其中括号中代表的是一次可以接纳的线程任务,可以不加参数,不加参数其数量就是当前cpu的个数*5。
res = pool.submit(func,args)
提交一个任务,args代表的是函数的参数。res接受的是该submit的返回值,类似于如下的类:
<Future at 0x2057e656940 state=running>
state代表的是当前该线程的状态。
res.result()
而使用result可以将提交的任务函数的返回值获取。
这里的result还有等待任务的返回值的作用。如果任务没结束,就会一直等待,可以将并行操作改成串行操作。
pool.shutdown()
可以将池子关闭,并等待池子终端 任务全部结束再执行下面代码。
例子:
import time from concurrent.futures import ThreadPoolExecutor import os from gevent import os pool = ThreadPoolExecutor(5) def task(n): print(n,os.getpid()) time.sleep(2) return n**2 list_1 = [] for i in range(20): res = pool.submit(task,i) #提交任务 print(res.result())#等待任务的返回值 list_1.append(res) pool.shutdown() #关闭池子,等待池子中的任务运行完毕 for j in list_1: print('>>>',j.result()) print('主')
进程池:
进程池的使用和线程池差不多,区别仅只有包名不同,在进程池中我们可以验证以下池中的进程/线程是否是用的同样的进程/线程,使用os。getpid()方法即可。
进程值不传值,里面的数值默认时cpu的个数。
import time from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os from gevent import os # pool = ThreadPoolExecutor(5) pool = ProcessPoolExecutor(5) def task(n): print(n,os.getpid()) time.sleep(2) return n**2 def callback(n): print(n.result()) if __name__ == '__main__': list_1 = [] for i in range(20): res = pool.submit(task,i).add_done_callback(callback) #提交任务 # print(res.result())#等待任务的返回值 list_1.append(res)
异步回调:
除了上面使用的将返回的future对象添加到列表,再调用result()方法返回其返回值以外,还可以对指派任务的返回值用
add_done_callback(callback)
方法,将该对象回调到callback(可以自定义)函数,由函数接纳处理该值,函数的参数就是任务的返回值,多个返回值要设置多个参数。
回调是在生产返回值时就运行的。
二。协程
协程就是在单线程的情况下实现并发。
一般程序的多道技术都是用 切换+保存状态 实现
在一般的cpu运算时,都是在五种状态中来回切换的,程序运行的5种状态:
1.新建。2.就绪。3.运行。4.阻塞。5.结束。
一般的,程序都是在2,3,4的状态来回切换,有2种情况。
1,程序遇到了io操作,由运行态进入到了阻塞态,直到io操作结束后再到阻塞态等待时间片。
2.程序的时间片用完,由运行态到就绪态。
协程的作用就是使得线程遇到io操作自己切换,运行的方式从1.变成2.线程持续不断的就绪,可以获得大量的cpu运算时间。
要实现这个功能需要考虑线程的保存状态问题。
这里就要用到迭代器的知识,yield,
yield可以保存上一次操作的状态,所以使用yield可以验证协程对计算密集型的线程操作后是否能加快效率。
#串行执行 0.8540799617767334 # import time # # def func1(): # for i in range(10000000): # i+1 # # def func2(): # for i in range(10000000): # i+1 # # start = time.time() # func1() # func2() # stop = time.time() # print(stop - start)
#基于yield并发执行 1.3952205181121826 # import time # def func1(): # while True: # 10000000+1 # yield # # def func2(): # g=func1() # for i in range(10000000): # time.sleep(100) # 模拟IO,yield并不会捕捉到并自动切换 # i+1 # next(g) # # start=time.time() # func2() # stop=time.time() # print(stop-start)
可以看到,在计算密集的线程中,不断切换线程是不利于程序的运行的。
而yield不能识别io操作,而进行线程之间的切换的,所以需要引入一个模块gevent。
gevent是一个可以识别io的魔块,但不能识别time.sleep,所以还要调用另外一个模块识别time.sleep。
from gevent import monkey;monkey.patch_all()
# 由于该模块经常被使用 所以建议写成一行 from gevent import spawn import time
spawn()可以检测()中的所有任务
def heng(): print("哼") time.sleep(2) print('哼') def ha(): print('哈') time.sleep(3) print('哈') def heiheihei(): print('嘿嘿嘿') time.sleep(5) print('嘿嘿嘿') start = time.time() g1 = spawn(heng) g2 = spawn(ha) # spawn会检测所有的任务 g3 = spawn(heiheihei) g1.join() g2.join() g3.join() # heng() # ha() print(time.time() - start) 哼 哈 嘿嘿嘿 哼 哈 嘿嘿嘿 5.033252716064453
原本10秒钟的程序,现在需要5秒钟就可以运行结束了。
spawn可以将所有线程添加至一个列表,轮流运行其没有io操作的部分。
spawn有一个返回值g
注意,需要在程序最后等待所有程序都运行结束才结束程序,使用g.join方法。
三。使用gevent实现tcp的并发
from gevent import monkey;monkey.patch_all() import socket from gevent import spawn server = socket.socket() server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0:break print(data.decode('utf-8')) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() def server1(): while True: conn, addr = server.accept() spawn(talk,conn) if __name__ == '__main__': g1 = spawn(server1) g1.join()
四。IO模型。
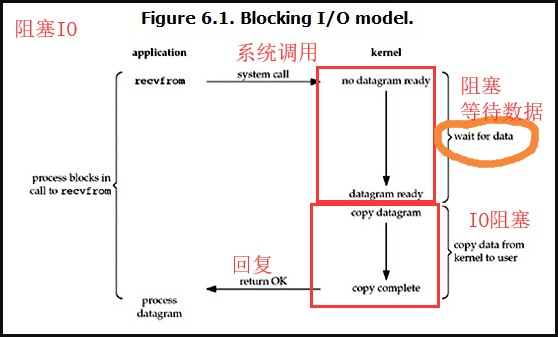
1.阻塞型IO
阻塞型io是在进行io操作时,先跳入阻塞态,然后等待数据。
数据获得后拷贝数据,
最后再进入就绪态,
其中等待数据和拷贝数据都是再阻塞状态:
2.非阻塞io
非阻塞io是在遇到io操作时,先发送接受数据请求,如果没有数据就返回一个没有的信号,之后会反复发送数据请求,直到有数据为止,这种模型很占cpu操作。

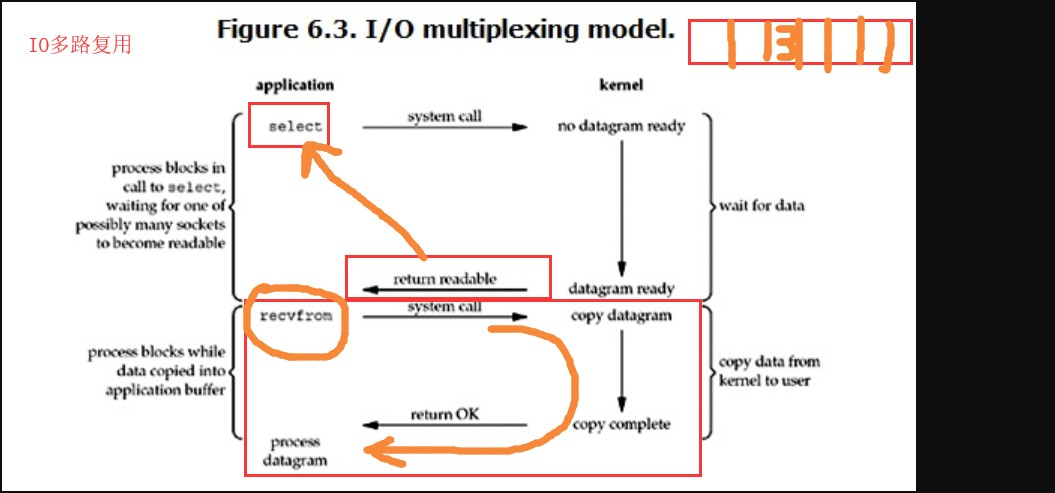
3.IO多路复用
这个模型中有一个select,是一个监测机制,类似于列表,管理io操作。
当需要进行io操作时,调用select寻找数据,如果找到数据就返回数据,
等待的操作全部交给select。
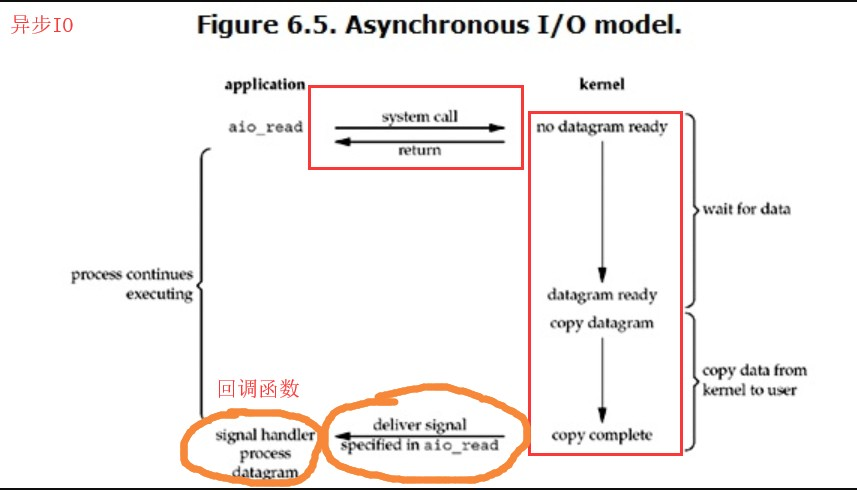
4.异步IO(asyn。。。。)
在遇到io操作时,有一个回调机制,当需要io操作时,回调机制(内存中)会去寻找数据,当寻找到数据后会返回数据