



一。操作系统相关
1.手工操作
1946年第一台计算机诞生--20世纪50年代中期,计算机工作还在采用手工操作方式。此时还没有操作系统的概念。
这时候的计算机是由人为将穿孔的纸带装入输入机,控制台获取到数据和操作后进行计算,计算完后打印结果,最后用户取走纸带放入下一个用户的纸带。
手工操作方式两个特点:

2.批处理
手工搬运纸带输入操作,这一方式中人为干预的时间远远超过了计算机计算的时间,在搬运纸带的过程中,cpu处于高度空闲状态,为了解决这种人机矛盾,第一代类似于操作系统的批处理系统出现了。
将成批的指令输入输入机,输入机由卫星机获取数据转交给高速磁带,高速磁带再将数据交给主机,输出也是通过卫星机。
卫星机是一种不与主机直接相连的专门用于与输入输出设备打交道的。
其功能是:
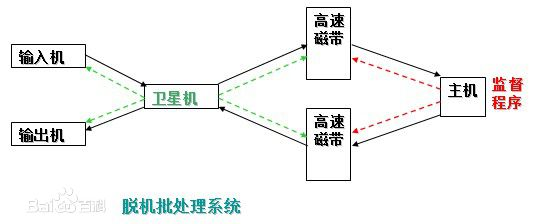
不足:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
3.多道程序设计。
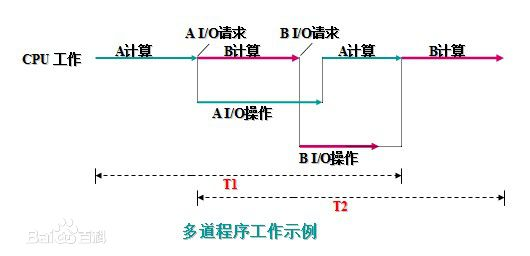
因为初始批处理系统只能同时操作一个程序,当程序进入i/o操作时,cpu会出现大量空闲时间。cpu利用率大大降低。为了解决这个问题,躲到程序系统产生了。

多道程序系统就是在程序进入io操作时,切换另一个程序的cpu运算工作,然后循环切换程序进行cpu操作,这样的方式称为统筹,这样的cpu利用率才是最大的。
4.分时系统。
为了使得在电脑上可以同时运行两个程序,比如边用qq聊天边听音乐,操作系统将cpu对程序的计算分成很小的时间片,这些时间片轮流执行各个程序,看起来就像时同时计算一样,但是强行结束程序会大大减少运算效率,但是这样时为了实现看起来共同执行的效果。

总结
总之,为了充分利用cpu,操作系统会想办法让cpu不断地进行计算。、
二。进程
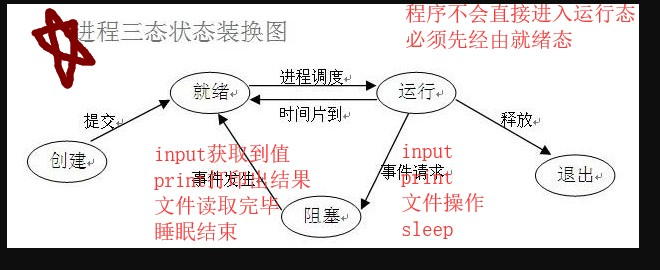
进程就是一个正在执行的程序,是操作系统提供的最古老的抽象概念之一。
1.多道技术。
(1)空间上的复用
多个程序共用一套计算机硬件。
(2)时间上的复用
实现时间复用就是用切换+保存状态实现。
当一个程序遇到IO操作 操作系统会剥夺该程序的cpu执行权限(提高了cpu的利用率 并且也不影响程序的执行效率)
import time from multiprocessing import Process def run(): print('进程开始') time.sleep(3) print('进程结束') if __name__ == '__main__': p=Process(target=run) p.start() print('主进程结束')
在创建进程的时候使用process关键字,其中target参数传入的是你要运行的进程的函数,而当这个函数是有参函数时,需要用args对其参数进行赋值。
注意:在这个py文件下创建进程,需要在main函数中创建,
就进程创建的原理来看,当执行process时,会将该py文件当作模块导入,如果不写在main中,会出现循环导入情况。
process创建进程时会新开辟一个内存空间。
当然,创建进程的方式也可以将函数放入一个类中,这个类继承自process。
其中当创建子进程时,需要一小短时间,但即使这样主进程也不会等待这个是时间,会立即执行下面的代码,当创建空间完成才会执行,所以这是一个异步的情况。
class Myprocess(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s开始运行'%self.name) time.sleep(3) print('%s运行结束'%self.name) if __name__ == '__main__': p = Myprocess('子进程') p.start() print('主进程结束')
以上是使用类创建一个子进程的方法,将一个继承自process的类中,改写其中的run方法,当创建一个对象后,调用其中的start方法就会自动调用这个方法。
join方法
join方法其作用就是等待子进程运行结束才会继续执行主进程。在start方法之后使用。
class Myprocess(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s开始运行'%self.name) time.sleep(3) print('%s运行结束'%self.name) if __name__ == '__main__': p = Myprocess('子进程') p.start() p.join() print('主进程结束') #子进程开始运行 #子进程运行结束 #主进程结束
多个join重复调用时,最后长的那个子进程结束后才会继续执行主程序。
进程的数据隔离
在进程中,使用的是新开辟的内存空间,与主进程中的数据不会重叠。
from multiprocessing import Process money = 100 def test(): global money money = 100000 if __name__ == '__main__': p = Process(target=test) p.start() print(money) #100
即使在子进程中的函数,调用global改变全局变量,也只是改变子进程中的money,主进程没有影响。
terminate()与is_alive()
这两个方法都是有关进程的方法。
terminate是将一个进程杀手,而is_alive是判断这个进程是否还活着
import time from multiprocessing import Process money = 100 def test(): global money money = 100000 if __name__ == '__main__': p = Process(target=test) p.start() p.terminate() time.sleep(1) a=p.is_alive() print(a) #False
daemon
daemon是当该值被赋予True时,将主进程设置为守护进程,
守护进程就是当主进程死亡后,无论子进程有没有运行结束,都会立即死亡。
from multiprocessing import Process import time def test(name): print('%s总管正常活着'%name) time.sleep(3) print('%s总管正常死亡'%name) if __name__ == '__main__': p = Process(target=test,args=('egon',)) p.daemon = True # 将该进程设置为守护进程 这一句话必须放在start语句之前 否则报错 p.start() time.sleep(0.1) print('皇帝jason寿正终寝') #皇帝jason寿正终寝
如果没有这个守护进程的设定,就会等主进程正常结束后,子进程再正常结束。
互斥锁
当多个进程操作同一份数据的时候 会造成数据的错乱,这个时候必须加锁处理,将并发变成串行,虽然降低了效率但是提高了数据的安全
注意:
1.锁不要轻易使用 容易造成死锁现象
2.只在处理数据的部分加锁 不要在全局加锁
锁必须在主进程中产生 交给子进程去使用。
已抢票为例
from multiprocessing import Process,Lock import time import json # 查票 def search(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) print('用户%s查询余票为:%s'%(i,t_d.get('ticket'))) # 买票 def buy(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) time.sleep(1) if t_d.get('ticket') > 0: # 票数减一 t_d['ticket'] -= 1 # 更新票数 with open('data','w',encoding='utf-8') as f: json.dump(t_d,f) print('用户%s抢票成功'%i) else: print('没票了') def run(i,mudex): search(i) mudex.acquire() buy(i) mudex.release() if __name__ == '__main__': mudex = Lock() for i in range(10): p = Process(target=run,args=(i,mudex)) p.start() #用户0查询余票为:5 #用户1查询余票为:5 #用户2查询余票为:5 #用户3查询余票为:5 #用户4查询余票为:5 #用户0抢票成功 #用户5查询余票为:4 #用户6查询余票为:4 #用户7查询余票为:4 #用户8查询余票为:4 #用户9查询余票为:4 #用户1抢票成功 #用户2抢票成功 #用户3抢票成功 #用户4抢票成功 #没票了 #没票了 #没票了 #没票了 #没票了

