ABP
1.ABP框架源的理论依据:DDD,领域驱动设计 有以下几点: DTO, DomainService, LocalEvent, Respository
2.领域>高内聚低耦合,领域的拆分不只是类,而是领域=根据业务来确定多个紧密联系的实体来组成同一个领域,+领域里面的验证+逻辑
3.所以,后续访问只能通过领域访问,而不是直接实体接口
4例子:用户 角色 菜单可合成一个领域也可拆分成三个,再加上日志 三个都需要,所以具体的领域划分还得看自身,不过通常由有大规则
5.领域拆分2个原则:1.大部分的聚合根是没有子集合的,如果子集合超过200就要继续拆 2.保持聚合根要小 如用户劫色菜单领域,查个角色,发现用户查出来几十万,这是不行的
6.Domian有以下: 1.实体Entity有主键。2.值对象无主键 如火警多人报警同一个地方,是以地址为自身只需要出警一次的
7.要访问Entity,也只能通过聚合根。
因为领域包含多个规则,直接访问会破坏指定的规则,而在c#里面领域又是一个虚拟的概念,所在领域在c#代码里面的表现就是 通过增加接口表示+泛型约束进行领域划分保护 限制增删改查,来保护业务规则
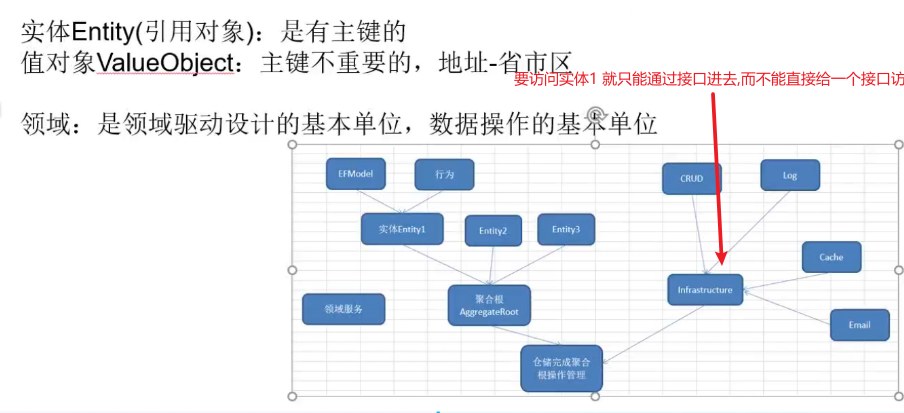
8.领域的具体分析
如一个名字:名字不能为空的规则写在Doain,名字不能重复,卸载DomainService
所以用户发起一个请求,返回的时候 从Domain返回的是Entity 返回给Appliocation 也是Entity 返回给用户的就是DTO

举例:一个资金转账的动作 应用层:相当于控制器,组装数据,不写业务逻辑, 领域层:业务逻辑,各种验证, 基础设施:就是公用的如发邮件

9.领域事件
一个操作可能要做额外的动作,或者出发一系列的后续动作--观察者模式 用来解耦
程序内部的事件总线

分布式事件总线:通过RabbitMQ
10.仓储模式:建立规则,

11.单元作业UnitOrWork
保证十五-本地事务,分布式事务


12.拓扑排序:ABP依赖太多,所以加载依赖需要一种算法:拓扑排序
拓扑排序的前提是有向无环(意思就是依赖里面没有互相依赖的否则会死循环) 算法两种选择:广度优先Or深度优先
-依次找到没有任何依赖的类,然后除掉,直至最后
ABP把所有的依赖都找出来,放在栈里面,然后进行拓扑排序,再依次加载依赖

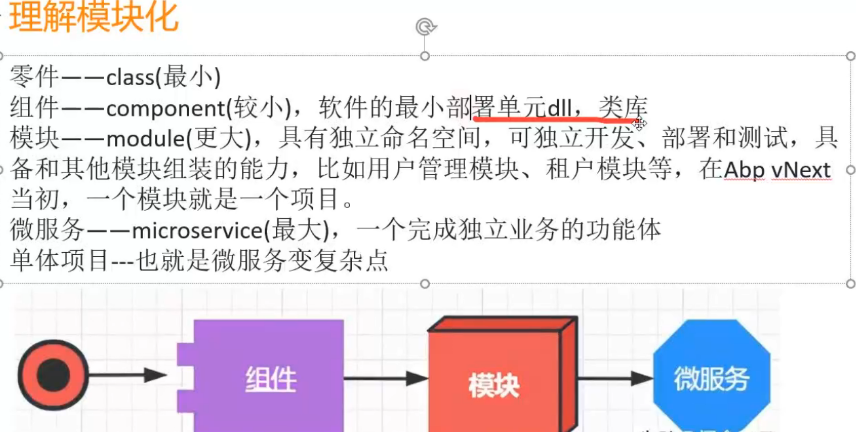
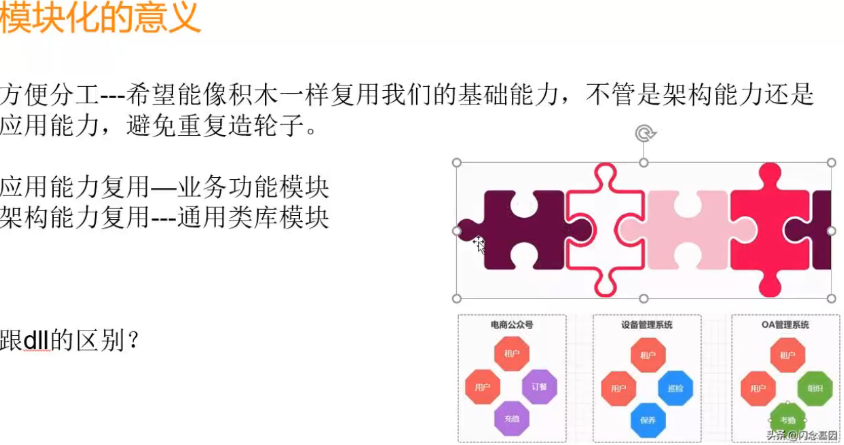
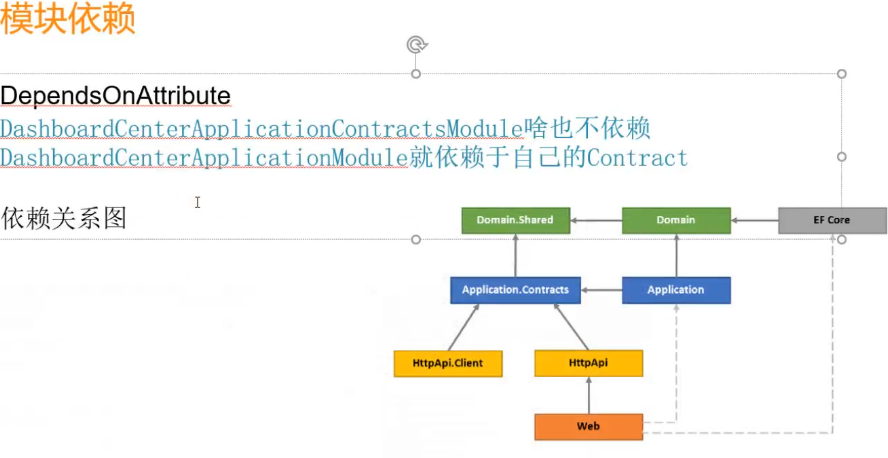
13.ABP模块化架构




本文来自博客园,作者:12不懂3,转载请注明原文链接:https://www.cnblogs.com/LZXX/p/16590945.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号