

Redis_九大数据类型
1.String 2.Hash 3.Set 4.Zset 5.BitMaps 6.Hyperlogloss 7.Streams 8.Bloom FIlter数据类型
1.String-键值对类型
- Redis存储的时候主动加序列化
- 使用场景:1.Session ,自增和自减
- string底层数据结构:在功能中,除了上面场景,否则别使用string 因为string会浪费大量内存空间,(只针对数值类型,int不包括,只有整型才是int类型)
- 为什么会浪费内存空间:
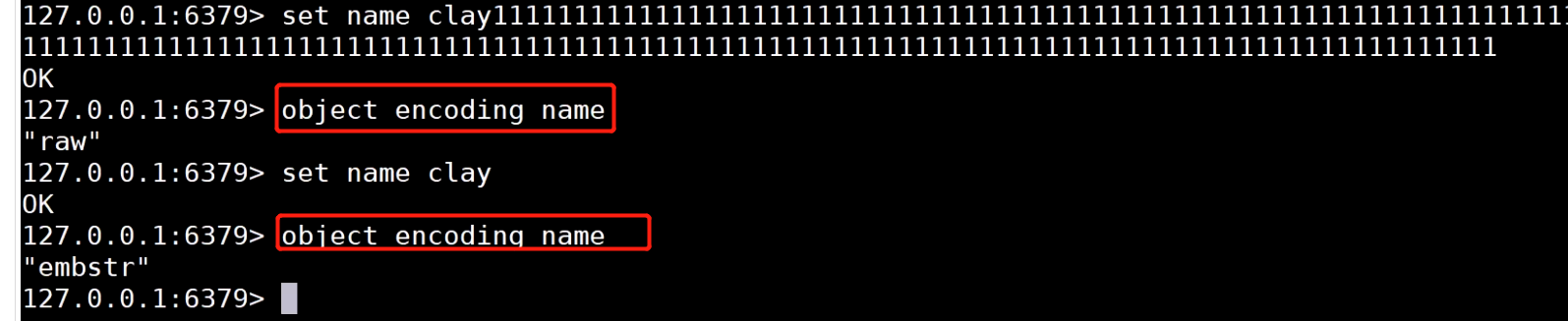
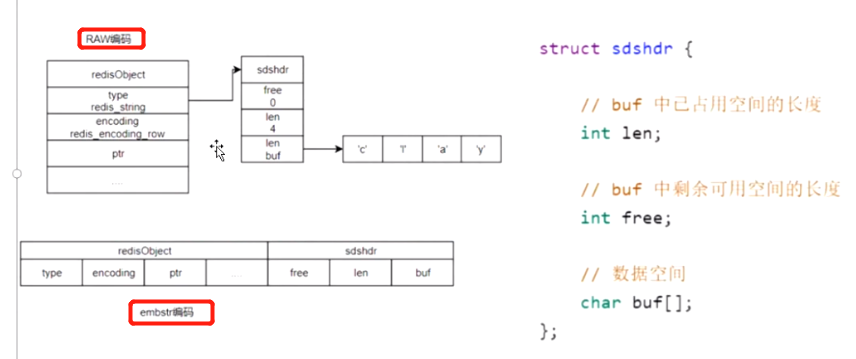
- RAW编码:编码表示用什么方式去开辟内存,而String的Raw编码 当你存>44个字节的时候 可能给你开辟100个字节的空间 所以会浪费大量数据空间
- embstr编码:如果操作Redis的时候,内容长度小于<=44字节(其他20给字节存放其他标识)。会自动选择embstr编码开辟空间,如果大于44字节 会使用RAW编码浪费空间
- 验证:
2.Hash
- 官网推荐使用的数据类型,1个大key,然后就是key value 下面是redis里面hash类型的,数据结构


- 使用场景:用户信息(有name,address,iphone等)
- Hash类型底层两种数据结构:
- zipList:(正常的List,每个元素的内存空间一样,假如每个内存空间都是100字节,第1个元素10字节,第二个100字节,第三个20字节,浪费大量空间),而zipList是自动适应内存空间的, 第1个元素10字节,那么存储的内存空间就是10字节,都是在内存空间开辟一连串的空间,只不过zip会自动适应内存空间,但也有问题:每次要插入值的时候,要开辟新的大空间把原先的迁移过来,把新值插入进去,所以每次新值内容,就要开辟一次新的空间,并且没有下标,因为不知道每个值的长度,普通的List有下标。查询的时候,要重头来计算前面的空间大小,所以查询速度变慢了。
- 所以就存在两个问题:1.每次插入都需要开辟新的空间,2.每次查询的时候都需要重头计算,所以查询速度变慢了
-
什么时候会使用HashTable: zip里面对象键值数量大于521个,或者里面任意1个键值长度大于64个字节会转成字典,而字典的结构是两个HashTable
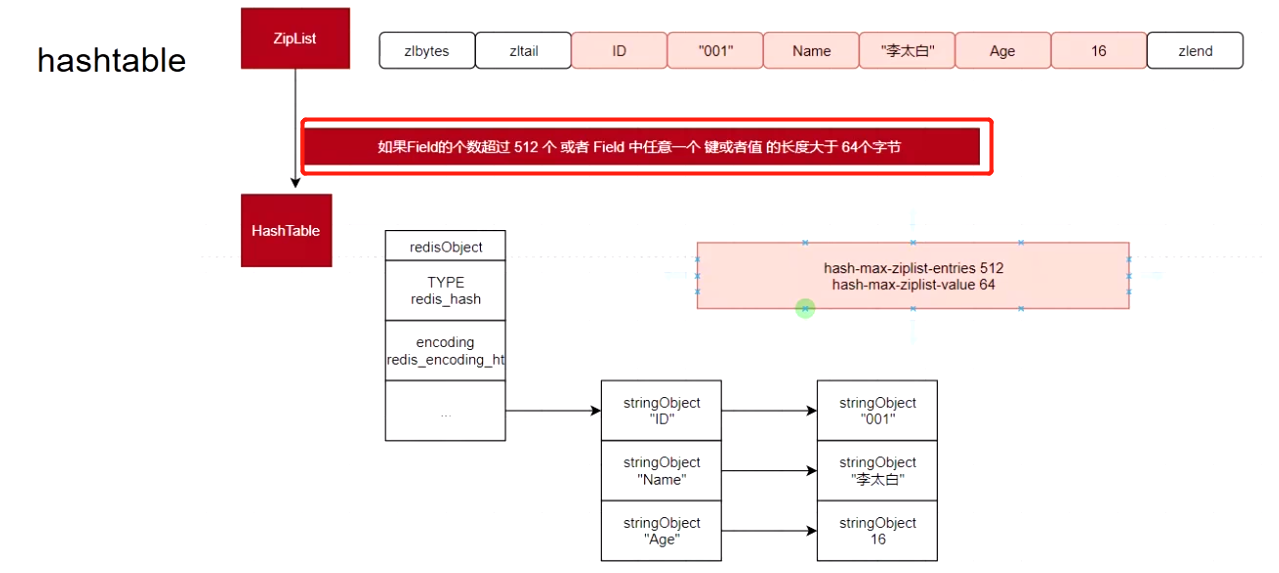
- hash Redis会在全局存两个哈希表:时间复杂度O(1),数组+链表形式,快速查询结果而且节省空间,
- 问题:因为Redis是通过哈希函数计算Key,Value的指针放入哈希桶的,而哈希桶的数量有限,当Key数量过多就会存在哈希冲突,多个Key存在同一个桶中就形成了链表,而每个链表指向下一个元素,如果链表过长,这样查询的速度就变得慢了起来,
- 那么Redis怎么解决:建立两个哈希表,并且进行reHash(当表1的元素个数等于数组长度的时候,就往表2存数据,表2扩容成表1的两倍), 但是Redis是单线程的不可能直接全量搬迁,于是每次客户端访问Redis的hash的都会搬迁一点到新的哈希表-渐进式reHash, 再搬迁过程中,查询优先找表1然后是表2 ,删除只能对表1操作,插入只能对表2操作。最后表1快搬迁完了元素个数小于数组长度的10%就进行缩容,如此反复。
3.List
- 队列先进后出,栈先进先出集合
- 使用场景:排队,插队, 分页,消息队列,错误日志。设置过期时间只能给整个集合设置过期时间
- .net里面的泛型List代表的是一种数据结构:安全类型的动态数组。而Redis里面的List是一种数据类型,这个数据类型的底层结构,老版本是双向链表,新版本是QuiltiList(链表+ZipList)
4.Set
- 也是1个集合,不过是1个去重的集合,相同的元素只会存在1个
- 使用场景:投票,取交集,并集,好友推荐等
5.Zset
- 也是去重集合具有Set的功能,多了1个自动排序,默认是顺序查询,相当于权重
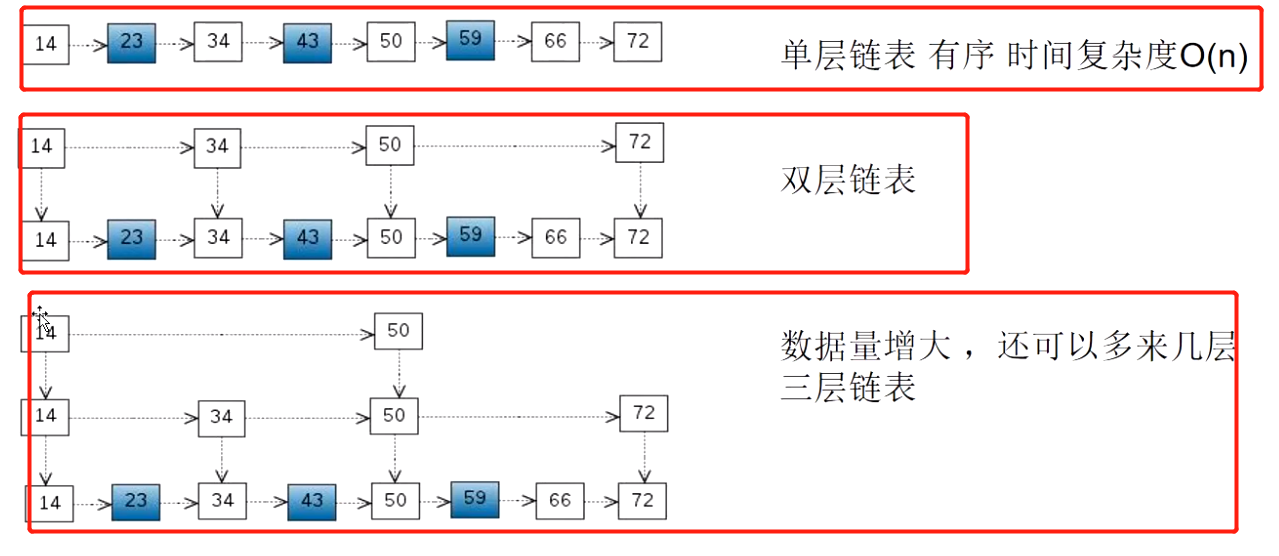
- 使用场景:服务注册发现,抽奖,限流,排行榜。所以业务尽量使用整型来查询
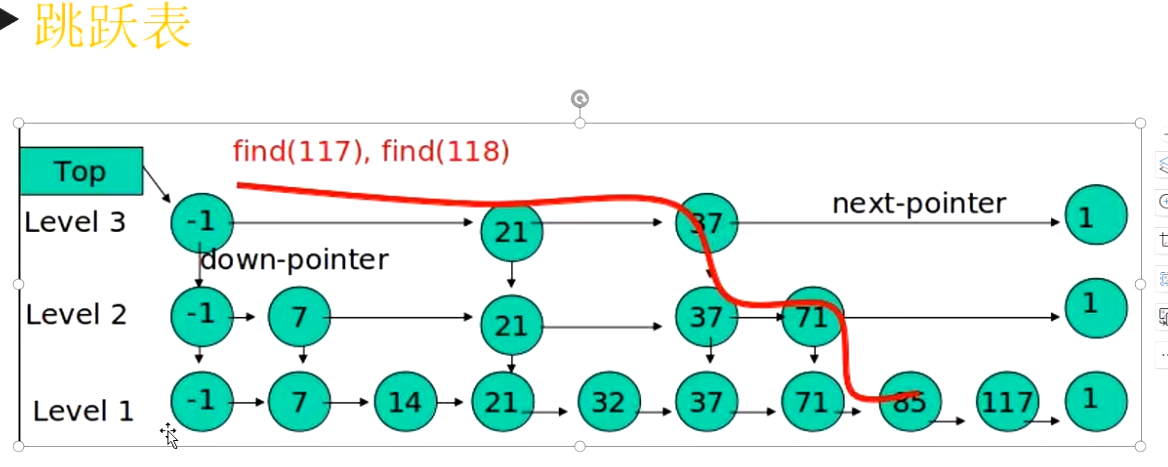
- 数据结构底层:跳跃表,利用跳跃表解决排序问题,把内容存放在Hash里面,,把数据存放在跳跃表里面,跳跃表顺序存放的,然后排序就根据存放的哈希里面的值来排序。查找顺序是,根据数据查找跳跃表,跳跃表里面的指针,指向hash。跳跃存放数据的时候就排序好了,所以是损失写的性能,提升查询的性能
- 查找的顺序是,从最顶层往下找,插入数据的时候通过随机数,是否决定上升,redis跳跃表最多32给级别
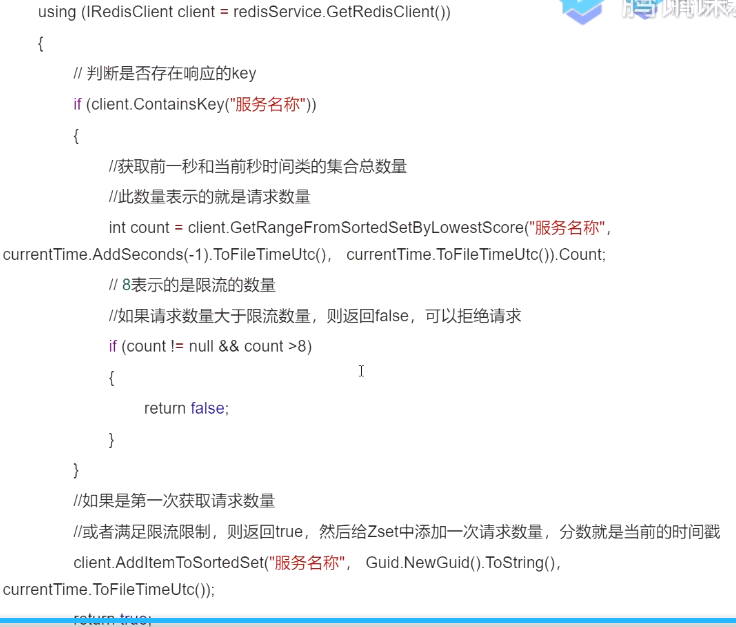
限制流量的Lua脚本
6.BitMaps
- 是1个节省内存的数据结构 只存0和1,
-
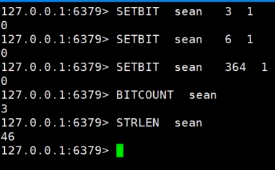
1.特征: 一串连续的二进制数字,底层时机是基于string,按bit位进行指令操作
2.场景:大数据下的用户登录
需求用户:十几个亿统计365天窗口的用户登录情况redis setbit 设置bit位移 1年365天都登录 最大存储量1个用户也就是46个字节
为什么要做大数据用户统计,因为要做决策,而决策影响营销和成本
7.Hyperlogloss
-
1.特征:海量数据统计 统计过程中不记录独立元素
2.使用场景:统计每日、每月的 UV 即独立访客数,或者统计海量用户搜索的独立词条数
- NewLife.Redis有封装相关接口 :下载地址 新生命团队 (newlifex.com)
8.Streams
- 发布订阅,kafak的生产和消费就是仿照这个做的
- 提示:Redis 的内存分配是使用
jemalloc进行分配。jemalloc将内存空间划分为小、大、巨大三个范围,并在范围中划分了小的内存块,当存储数据时,选择大小最合适的内存块进行分配,有利于减小内存碎片。
9.Bloom FIlter-布隆过滤器
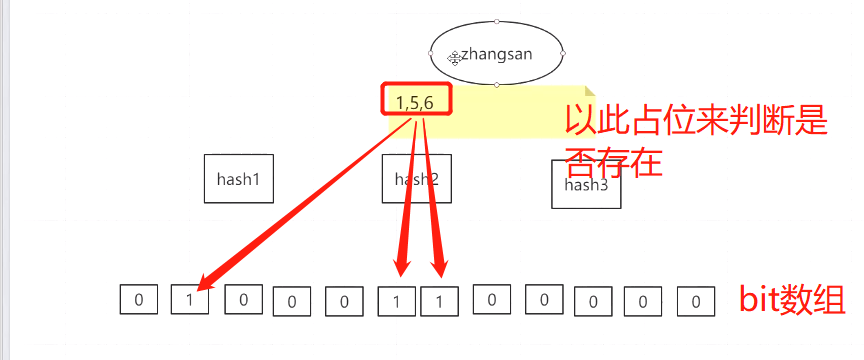
1.布隆过滤器厉害在于用更少的内存,存入更多的数据,并且查询效率高,但是判断数据会有误判情况
2.相当于redis的插件, hash+字节占位
3.bit数组越长,hash方法越多,占用内存越多,误判越少 .bit数组越短,hash方法越少,占用内存越少,误判越多
本文来自博客园,作者:12不懂3,转载请注明原文链接:https://www.cnblogs.com/LZXX/p/16321674.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY