分布式缓存之redis核心理解
redis核心理解 组件选择:https://redis.io/docs/clients/ ServiceStack.Redis因为用的最多
为什么选择redis (redis性能为什么高)?
1.基于内存9种形式存储 本地方法,计算向数据移动(io优化)
2.work是单线程,io是多线程
3.redis之所以选择单线程是因为,它是事件驱动模型,redis发起调用之后,不等待结果,继续执行下一个命令,只要有一个命令执行完成-触发事件,就把结果写回来-高性能
1.redis9中类型, 还有5种本地方法,计算向数据移动
拿memcached和redis对比 一个是取全量之后还要本地计算list 而redis直接计算好之后返回结果-性能快

2.redis单线程原理和为什么性能高?
1.文件事件处理器的设计模型:组成分为4个部分(多个套接字,io多路复用器epoll,文件事件分派器(单线程),事件处理器) 因为文件事件分派器是的消费是单线程所以redis才叫单线程模型-事件驱动模型
传统观念中,单线程慢 是因为 浏览器发起请求-服务器解析-调用接口,数据库-发送命令-请求需要得到结果-这里就需要等待,性能损失在这
而redis之所以选择单线程是因为,它是事件驱动模型,redis发起调用之后,不等待结果,继续执行下一个命令,只要有一个命令执行完成-触发事件,就把结果写回来-高性能
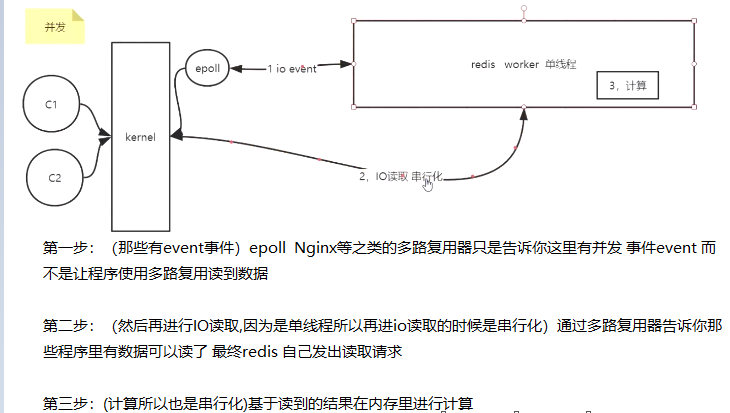
3.既然是redis单线程 那么速度快吗?
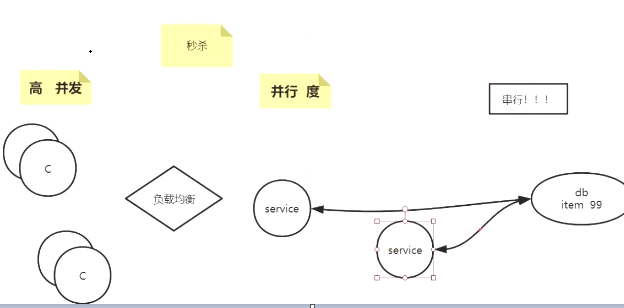
拿秒杀举例 选择DB数据库
1.一个服务器解决不了高并发 可以通过负载均衡分发给多个服务器
2.但是如果有10万个并发 服务器只有两台 那么只能有两个并行度,并行度决定了性能的快慢3.虽然上面可以解决高并发,但是在秒杀扣减库存的这种交易都是需要串行的 为什么?
在需要item 99 扣减的情况下两个并发请求得到99 -1 然后计算好 update回去98这就不对了
所以请求进来要么是加锁 要么是加事务 这里也决定了性能的快慢
所以前面所谓的并行到了数据库依然是串行
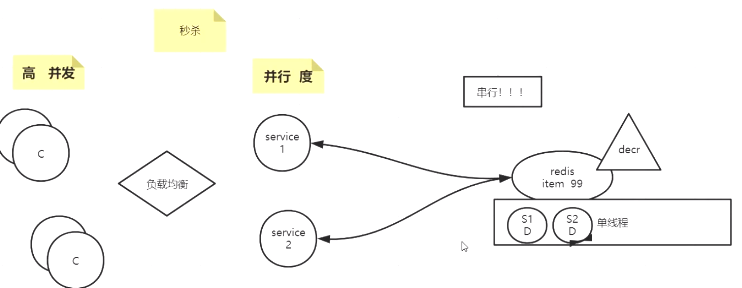
选择redis做数据存储
redis 有个decr本地方法 如果调用了他就会减1另外它是单线程的, 不管前面多少io进来都是遍历循环,1个个处理的
1.所以高并发走到DB,要加锁加事务
2.而redis有本地decr,还是单线程的,并发请求过来也是直接1个个循环遍历 比db速度快
3.也得出另一个结论多线程不一定好,有了多线程就需要加锁,加事务,还会造成脏读之类的
4. redis单线程速度快 但也有弊端?
因为redis是单线程 所以就一个work线程 假如服务器配置很好cpu核心多,跑一个redis 把内存什么都给redis 单位时间的qps上去了但总归来说cpu利用率不高
那么怎么能把cpu利用起来,而不破坏redis的单线程串行化的特征?
而且还不能开启多线程(开了多个work线程就是,锁,事务啊问题一大堆反而影响性能了)
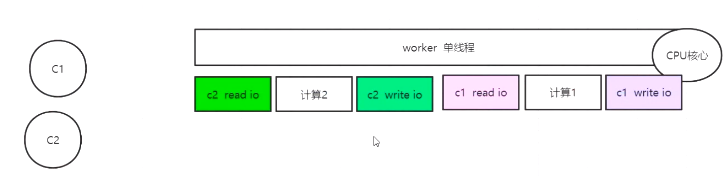
5.redis避免单线程的弊端?
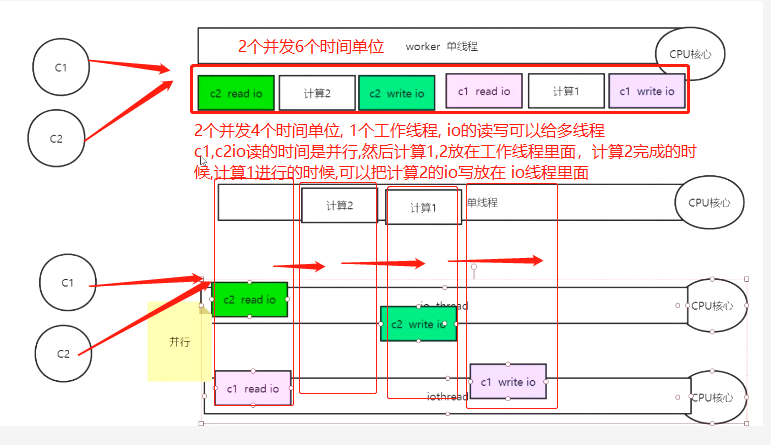
如下:上图的是6.x以前的纯净单线程模式
下图的是6.x以后的模式 所以把cpu核心提高,下面的redis比上面的能提高一半
不过这种不是默认行为,需要在配置里面开启(开启了,那么就是多线程了,所以计算1,2的顺序就不能保证,)
6. 9种数据类型
1.string 场景使用
数据结构:key,value
场景:session kv缓存,数值计算,gs文件系统,内存
2.List场景使用:
理解redis的list数据放入顺序
同向:lpush lpop 先进后出
异向:队列先进先出
index()数组
ltrim:删除数据 优化redis的内存量
使用场景: 评论列表,消息队列,
3.hashtable场景使用:
为什么有hashtable 因为使用的是分治法
1.聚集数据
2.表单(商品)详情页-因为里面有很多数据,且来自多个数据库,不怎么变化,被频繁访问
3.用户详情
4.set集合场景使用但是可以多个实例,每台服务器的redis存放不同的数据类型
1.特征.放入的数据无序,且会去除重复的数据
2.集合交并差, sunion(并),sinter(交),sdiff(差)-
3.随机事件 srandmember, spop 放入的数据 (随机给你返回)
场景:好友推荐(并集,共同好友.....),随机事件
5.zset集合场景使用
1.特征:有序集合 去重复,
2.场景:排行榜6
数据结构:跳表

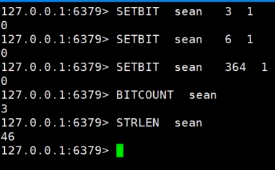
6.bitmap位图
1.特征: 一串连续的二进制数字,底层时机是基于string,按bit位进行指令操作
2.场景:大数据下的用户登录
需求用户:十几个亿统计365天窗口的用户登录情况redis setbit 设置bit位移 1年365天都登录 最大存储量1个用户也就是46个字节
为什么要做大数据用户统计,因为要做决策,而决策影响营销和成本
7.geo 地理位置类型
1.特征:利用geohash算法将经纬度转一维的整数值
2.查附近的人,餐厅,电影院
8.HyperLogLog 基数统计类型。
1.特征:海量数据统计 统计过程中不记录独立元素
2.场景:统计每日、每月的 UV 即独立访客数,或者统计海量用户搜索的独立词条数
9.Streams 内存版kafka 发布订阅
提示:Redis 的内存分配是使用 jemalloc 进行分配。jemalloc 将内存空间划分为小、大、巨大三个范围,并在范围中划分了小的内存块,当存储数据时,选择大小最合适的内存块进行分配,有利于减小内存碎片。
Redis内部编码
Redis这样设计有两个好处:
- 可以偷偷的改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动对外数据结构和命令。
- 多种内部编码实现可以在不同场景下发挥各自的优势。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降。这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。

7.单个redis
1.持久化 异地备份也叫持久化 mysql
持久化形式:rdb,image,bak(拍快照) AOF(日志)
redis 默认开启rdb>手工开启AOF ,4.x以前的redis 重启之后只会读取AOF内容,
4.x之后, aof+rdb模式
但是redis看场景使用持久化,做缓存就不建议使用持久化,因为持久化必然要开启aof记录操作日志(影响性能)
但是假如重启服务器缓存没了呢?可以使用主从模式
2.单机存在单点故障,压力/性能
单点故障:多台解决单点故障(全量主备高可用服务,读写分离)
压力/性能:10个G的数据拆分10个1G放在不同服务器(分片数据)-但不是全量数据了(然后要对分片的数据做1个全量的主备)
最后上面的解决方案变成集群模式(高可用-搞性能)
redis解决高可用-用主从复制 redis解决高性能-分片数据
1.C>主>备 需要同步数据
c给主发请求 主和备都写入数据成功才返回给C(强一致性)
问题:如果备挂了, c就一直等待 所以在分布式场景下强一致性,会造成不可用性
上述就是:CAP理论 三者不可兼得 一致,可用,分区容错性
例如ca(强一致性)=mysql
reids=默认弱一致性,可以配置强一致性(不建议,都用了redis,开启性能就很低,单线程,不如多线程计算高)
对于Redis来说,如果是单机的话,是CP,而如果要使用(主从模式)的话就变为了AP。
金融 no>redis (一致性),但互联网>reidis(速度)
问题:为什么 journalnode多台就能有最终一致性 最终一致性:黑盒(集群-journalnode)
而redis多台就会造成会对外造成不可用(redis只有强,弱一致性)
paxos论文 (分布式一致性算法raft协议和zab协议建立在paxos上面)
分布式下 1个数据给3台服务器发起请求返回结果
约束条件是 请求来了3台都返回ok> 但1台挂掉就不行(强一致性造成不可用性)
约束条件是 1台返回ok> 容易脑裂,只有1台返回ok,其他两台容易造成数据不一致
约束条件是 2台返回ok> 会造成数据不一致,
解决 服务器需要互相通信,如果有新的服务器来了,就需要先通信同步数据再介入
8.redis分布式
1.代理中间件,分布式算法给中间件 客户端>算法中间件(proxy,多台可做负载均衡)>redis,使用代理层来计算数据的访问读取
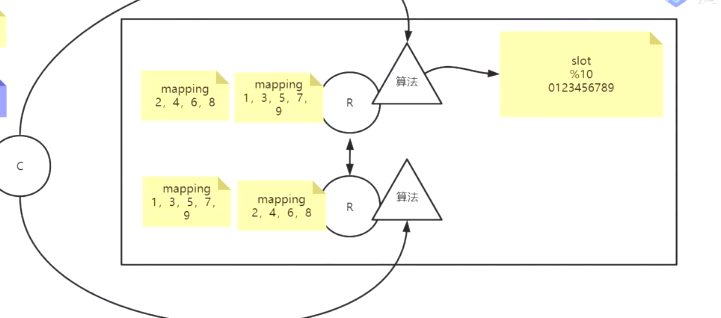
2.分布式算法放在redis里面,redis再互相通信,增加映射数据分为10个槽位,这就是分布式redis集群,还需要加备机
3.如果要加redis,只需要把其中123放在新的redis,就可以小量数据迁出,不需要全量数据伪哈希
4.10个槽位就固定了,可以增加10台redis集群
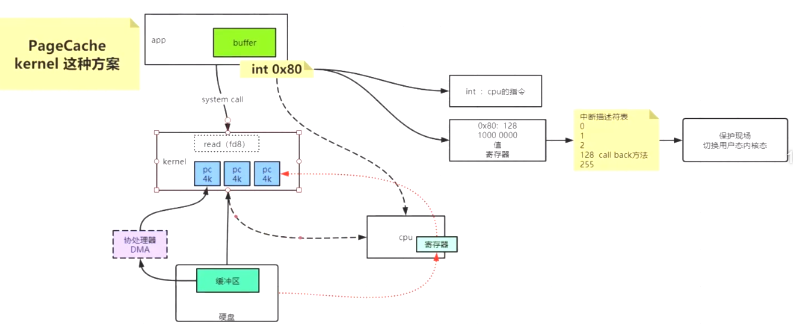
1.缓存穿透(请求过来的时候-缓存和数据库都没有):虽然数据都没有但是大量并发的时候 请求还是要进到数据库并且还要返回结果给人家。这样人家恶意攻击就难受了
怎么解决:如果数据没有,缓存就存一个null,下一次来的时候返回null,这样请求就到不了数据库
2.缓存击穿(请求过来的时候-缓存没有数据库有):大量并发请求还是直接到数据库,
怎么解决:这个问题不大,下一次进来给他缓存就好,或者进行缓存提前预热
3.缓存雪崩(请求过来的时候-数据缓存同时过期):请求还是到数据库来了,
怎么解决:数据设置随机过期时间,别都设置为30分钟过期,这样就降低缓存雪崩出现
4.缓存预热(请求过来的时候-缓存重启):服务重启之后,提前把热点数据放到缓存里面
缓存的使用:客户端缓存 CDN缓存 反向代理缓存 本地缓存 分布式缓存
为什么Redis中限制了String类型的最大长度不能超过512MB?
- 我们程序一般不会有那么大的数据量存入缓存,如果有大数据量的 一般也不会存在512因为越大取的越慢,而真正需要的数据也就哪一点,所以一般也会对数据进行分割
- 大的数据量对网络和性能有一定影响;
- SDS的len是int类型的,有长度限制;
String类型:一个String类型的value最大可以存储512M List类型:
list的元素个数最多为2^32-1个,也就是4294967295个。Set类型:元素个数最多为2^32-1个,也就是4294967295个。
Hash类型:键值对个数最多为2^32-1个,也就是4294967295个。
Sorted set类型:跟Set类型相似。
windows-下载redis
地址:百度云链接:https://pan.baidu.com/s/1Kk24Ch-a_NvRIxdNfipUew#list/path=%2F 提取码: d8t9
1.redis-server.exe ---启动Redis服务器 -----SqlServer服务实例 2.redis-cli.exe ---测试Redis的一个工具 -----SQL Server Management Studio 18 3. redis-desktop-manager-0.8.8.384 ----Redis的可视化工具 通过桌面展示
.net操作redis
1.nuget引用程序集:ServiceStack.Server
2.操作5大数据类型 ,Hash,List Set String Zset
 Redis 链接Redis配置文件Redis操作基类HashListSetStringZset
Redis 链接Redis配置文件Redis操作基类HashListSetStringZset
.net5 Startup中间件使用redis
startupRedisConfigInfoCustomResourceFilterAttribute
本文来自博客园,作者:12不懂3,转载请注明原文链接:https://www.cnblogs.com/LZXX/p/15919132.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号