Web框架推导
web框架
web框架本质
我们可以这样理解:
我们所写的web框架就是一个socket服务端,而用户浏览器就是socket客户端。
web框架就是链接前端与数据库的中间介质,就是一个socket服务端

纯手撸web框架
1.搭建socket服务端
socket服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock , address = server.accept()
data = sock.recv(1024)
# print(data.decode('utf8'))
sock.send(b'HTTP/1.1 200 ok\r\n\r\n')
data_str = data.decode('utf8') # 先转换成字符串
target_url = data_str.split(' ')[1] # 按照空格切割,然后拿去切割后得第二个数据,拿到的就是我们输入后台网站的后缀
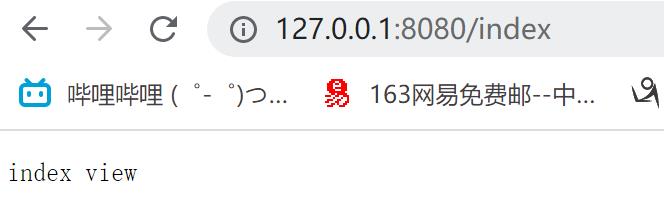
if target_url == '/index':
sock.send(b'index view')
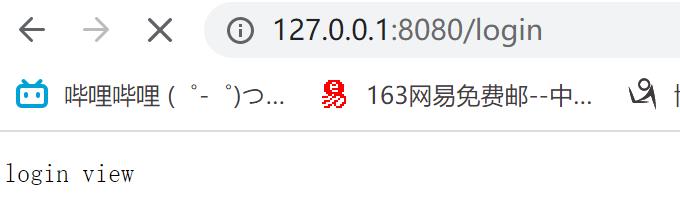
elif target_url == '/login':
sock.send(b'login view')
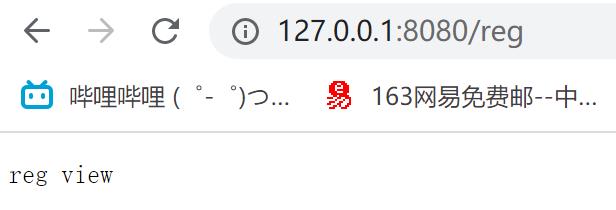
elif target_url == '/reg':
sock.send(b'reg view')
else:
sock.send(b'404 error')
2.手写web框架流程
1.编写socket服务端代码
2.浏览器访问响应无效>>>:HTTP协议
3.根据网址后缀不同获取不同的页面内容
4.想办法获取用户输入的后缀>>>:请求数据
5.请求首行
GET /lohin HTTP/1.1
GET请求
朝别人索要数据
POST请求
朝别提交数据
6.处理请求数据获取网址后缀
"""
代码缺陷:
1.socket代码过于重复(每次搭建服务端都需要反复造轮子)
2.针对请求数据处理繁琐
3.针对不同网址后缀的匹配方式过于LowB
"""
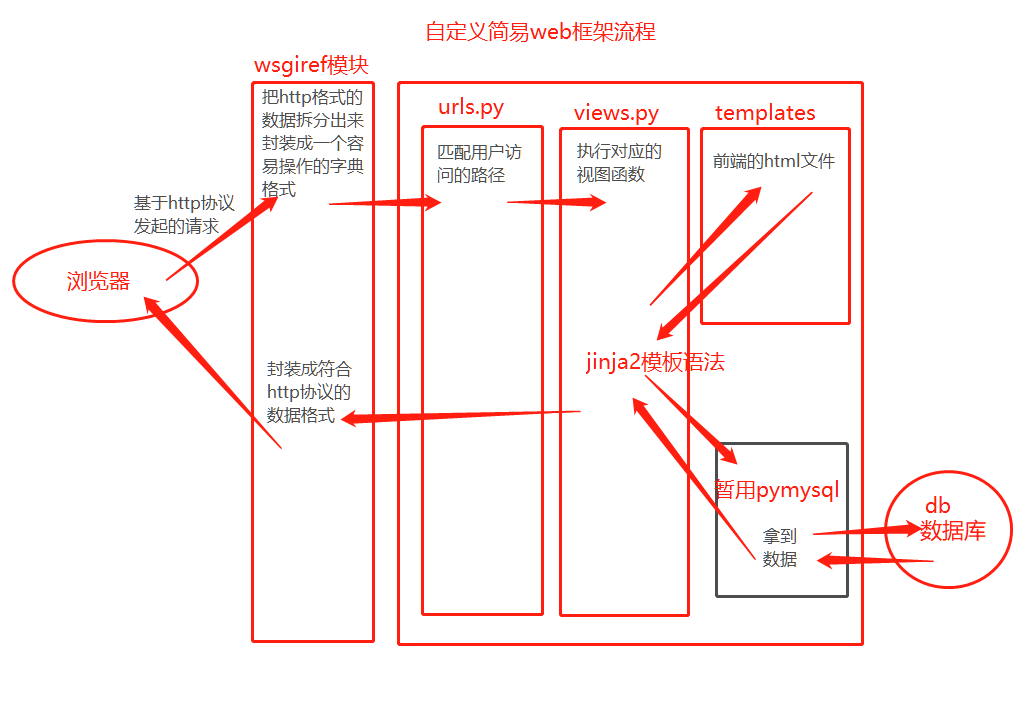
基于wsgiref模块
wsgiref内部封装了socket代码的请求数据的处理
服务端代码
import wsgiref
from wsgiref.simple_server import make_server
from urls import urls
from view import *
def run(request, response):
"""
:param request: 请求数据
:param response: 响应数据
:return: 返回给客户端的数据
"""
response('200 ok',[])
# print(request) # 自动将请求数据全部处理成字典K:V键值对形式
target_path = request.get('PATH_INFO') # /login
# if target_path == '/index':
# return [b'index']
# elif target_path == '/login':
# return [b'index']
# elif target_path == '/reg':
# return [b'reg']
# else:
# return [b'404 not found']
func_name = None
for url_tuple in urls: # ('/index',index)
if url_tuple[0] == target_path:
func_name = url_tuple[1] # 先存储匹配到的函数名
break # 一旦匹配到内容就立刻结束for循环 没有必要继续往下执行了
# for 循环结束以后,还需要判断func_name是不是为None(有可能没有匹配上)
if func_name:
res = func_name(request)
else:
res = error(request)
return [res.encode('utf8')] # 做统一编码处理,这样函数就只需要返回字符串即可,操作更简单
if __name__ == '__main__':
server = make_server('127.0.0.1',8080, run) # 任何访问127.0.0.1:8080的请求都会给第三个参数加括号进行调用
server.serve_forever()
urls代码
from view import *
urls = (
('/index', index),
('/login', login),
('/func', func)
)
view代码
def index(request):
return 'index'
def login(request):
return 'login'
def error(request):
return '404'
def func(request):
with open(r'myhtml02.html', 'r') as f:
data = f.read()
return data
代码封装优化
1.wsgiref模块解决了两个问题
1.socket代码重复编写造轮子
2.针对请求数据格式的处理复杂且重复
2.思考如何再次实现根据不同的网址后缀返回不同的内容(函数化)
先从大字典中查找出记录网址后缀的键值对
1.不推荐使用连续的多个if判断
2.针对面条版的代码首先应该考虑封装成函数,封装成函数以后的好处就是,之后如果要添加页面的时候只需要再写一个函数就可以了,如果要修改某个页面,只需要找到对应的函数修改函数就可以了
3.想在函数里再获取一些方法,想看一下前端发过来的到底是什么方法,将request作为参数传给函数run函数里面的其他函数
4.现在我们在一个py文件里写了好多功能(处理页面请求的核心逻辑、对应关系、服务端的代码),这样太乱了,根据py文件中功能的不同划分到不同的py文件中去
urls.py 存储网址后缀与函数名对应
views.py 存储核心业务逻辑(功能函数)
start.py 启动文件
templates目录 存储html页面文件
总结:拆分后好处在于要想新增一个功能,只需要在views.py中编写函数,urls.py添加对应关系即可
动静态网页
动态网页
页面上的数据不是全部写死的,有些是动态获取(后端传入)
静态网页
页面上的数据直接写死,想要改变只能修改源码
举例:
1.访问某个网址后缀,后端代码获取当前时间,并将该时间传到html文件上再返回给浏览器展示给用户看
读取html内容(字符串类型),然后利用字符串替换,最后再返回给浏览器
2.将字典传递给页面内容,并且在页面上还可以通过类似于后端的操作方式操作该数据
模板语法>>>:jinja2模块
jinja2模块
jinja2能够让我们在html文件内使用类似于后端的语法来操作各种数据类型
pip3 install jinja2
jinja2模板语法:
{{···}}
{%···%}
html代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
</head>
<body>
<h1>{{ data }}</h1>
<h1>{{ data['name'] }}</h1>
<h1>{{ data.get('pwd') }}</h1>
<h1>{{ data.hobby }}</h1>
</body>
</html>
view代码
from jinja2 import Template
def get_dict(request):
user_dict = {'name': 'jason', 'pwd': 123, 'hobby': ['read', 'run', 'music']}
with open(r'templates/myhtml04.html', 'r', encoding='utf8') as f:
data = f.read()
temp = Template(data)
res = temp.render(data=user_dict) # 将字典传递给html页面 页面上通过data即可获取(data仅仅是一个变量名)
return res
前端、后端、数据库三者联动
html代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css">
<script src="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container">
<div class="row">
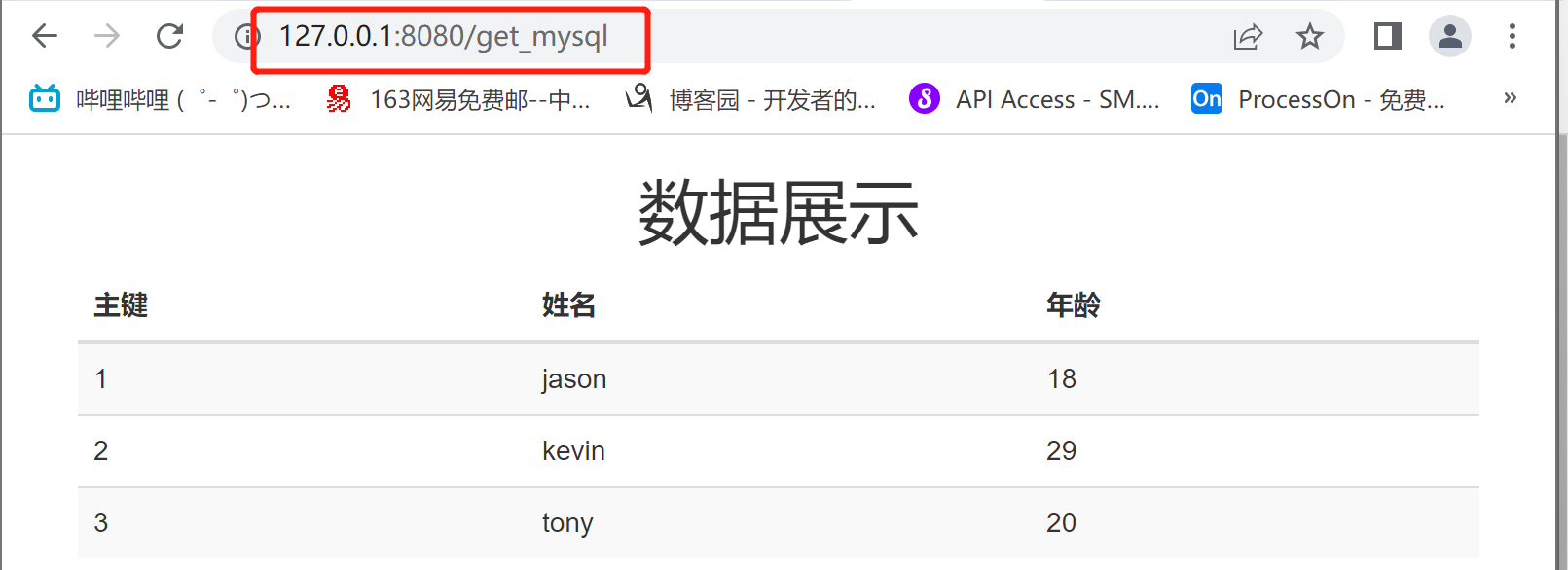
<h1 class="text-center">数据展示</h1>
<div class="col-md-6 col-md-offset-3">
<table class="table table-hover table-striped">
<thead>
<tr>
<th>主键</th>
<th>姓名</th>
<th>年龄</th>
</tr>
</thead>
<tbody>
{% for user in user_data %}
<tr>
<td>{{ user.id }}</td>
<td>{{ user.name }}</td>
<td>{{ user.age }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>
views代码
import pymysql
def get_mysql(request):
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='day55',
charset='utf8',
autocommit=True
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = 'select * from userinfo'
cursor.execute(sql)
user_data = cursor.fetchall() # [{},{},{}]
with open(r'templates/myhtml05.html','r',encoding='utf8') as f:
data = f.read()
temp = Template(data)
res = temp.render(user_data=user_data)
return res
sql代码
create database day55;
use da55
create table userinfo(id int primary key auto_increment,name varchar(32),age int);
insert into userinfo(name, age) values('jason',18),('kevin',29),('tony',20);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号