数据类型内置方法与操作
目录
数据类型
一.数据类型内置方法理论
- 什么是数据类型内置
内置方法即是每个数据类型自带的功能
数据类型总类:
1.整型 2.浮点型 3.列表型 4.字典型
5.字符型 6.布尔值 7.元组 8.集合
使用数据类型的内置方法统一采用句点符(.)
'rain'.字符串内置方法
绑定字符串的变量名.字符串内置方法
str.字符串内置方法
"""
数据类型的内置方法比较多,我们如果想要掌握不需要死记硬背,更多的时候靠的是熟能生巧。
"""
二.整型int的内置方法与操作
1.类型转换
类型转换就是将其他数据转换成整型
int(其他数据内型)
注意:只有浮点型和字符串才能转换成整型,浮点型可以直接转,字符串必须满足内部是纯数字才可以
2.进制数转换
十进制转换其他进制
print(bin(100)) #bin()将十进制转换为二进制 0b 是二进制的标识 0b1100100
print(oct(100)) #oct()将十进制转换为八进制 0o 是八进制的标识 0o144
print(hex(100)) #hex()将十进制转换为十六进制 0x是十六进制的标识 0x64
#若前面没有标识符 则默认为十进制
其他进制转换成十进制
print(int(0b1100100))
print(int(0b1100100))
print(int(0b1100100))
or
print(int("0b1100100", 2))
print(int("0o144", 8))
print(int("0x64", 16))
ps:python自身对数字的敏感度较低(精确的低),如果需要精准的计算需要借助模块numpy....
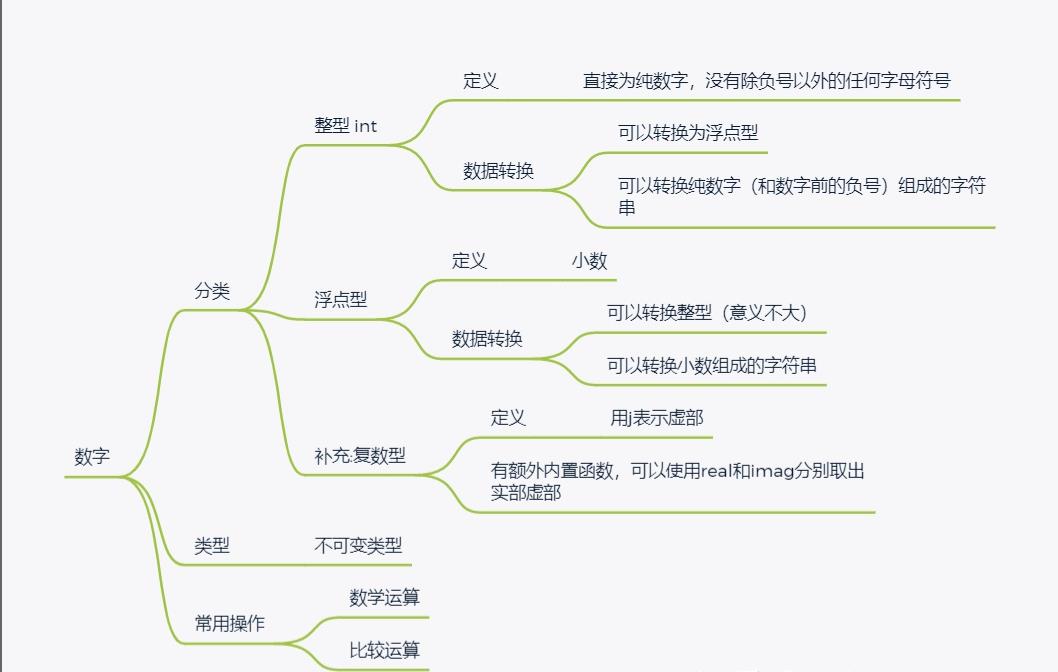
三.浮点型float内置方法与操作
1.类型转换
float(其他数据类型)
字符串里面可以允许出现一个小数点,其它都必须是纯数字(python自身对数字的敏感度较低(精确的低),如果需要精准的计算需要借助模块numpy....)
2.针对布尔值的特殊情况
print(folat(True)) # 1.0
print(folat(False)) # 0.0
print(int(True)) # 1
print(int(Flase)) # 0
当转换值为布尔值时,所转换的是该布尔值对应的数值(True:1,False:0)
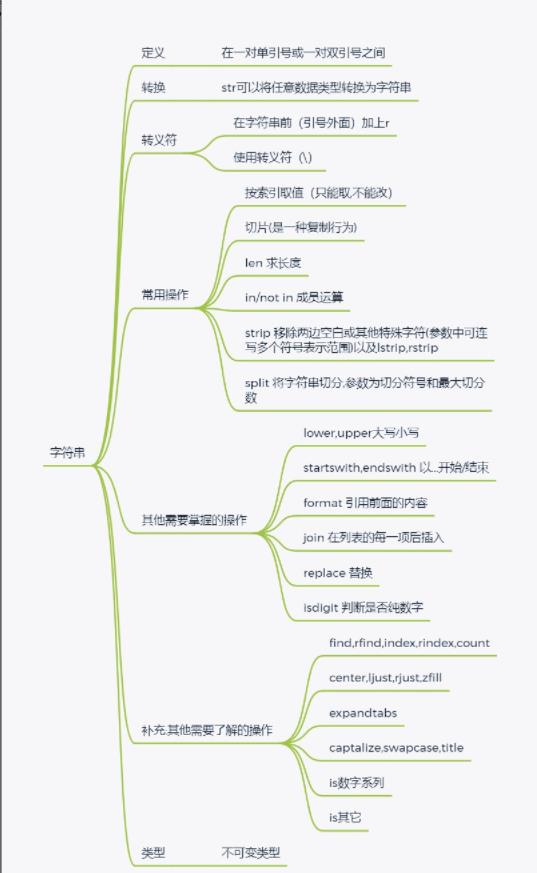
四.字符串str的内置方法与操作
1.类型转换
str(其他数据类型)
可以转换任意数据类型(只需要在前后加引号即可)
2.必须掌握的方法
1.索引取值
s1 = 'hello word'
print(s1[0]) # h
print(s1[-1]) # d
"""
1.起始位置0开始,超出范围直接报错。
2.支持负数,所打印的内容是从右往左以此读取
"""
2.切片操作
s1 = 'hello word'
print(s1[1:5]) # 骨头不顾尾 从索引1一直切取到索引4
print(s1[-1:-5]) # 由于默认的顺序是从左往右 所以打印不出所实现的值
print(s1[-5:-1]) # 默认顺序是从左往右 worl
3.修改切片方向
s1 = 'hello world'
print(s1[1:5:1]) # 默认是1 ello
print(s1[1:5:2]) # 默认是1 el
print(s1[-1:5:-1]) # 改变方向从右往左 dlrow
print(s1[:]) # 不写数字就是默认都要
print(s1[2:]) # 就是从索引2开始往后都要
print(s1[:5]) # 从索引0开始往后要到4
print(s1[::2]) # 从索引0开始每隔一个取一个
4.统计字符串的个数
len:字符串长度
s1 = 'hello world'
print(len(s1)) # 10
5.移除字符串首位指定的字符
strip:移除
username = input('username>>>:').strip()
if username == 'jason':
print('登陆成功')
res = ' jason '
print(len(res)) # 由于首尾各有两个空格 所以字符串长度为9
print(len(res.strip())) # 括号内不不写 默认移除首尾空格 字符串长度为5
res1 = '$$jason$$'
print(res1.strip('$')) # 默认移除首尾 jason
print(res1.lstrip('$')) # 移除左边(leftstrip)也就是首 jason$$
print(res1.rstrip('$')) # 移除右边也就是尾 $$jason
6.切割字符串中的指定字符
split:切割
res = 'jason|123|read'
print(res.split('|')) # ['jason', '123', 'read'] 该方法处理结果是一个列表
name, pwd, hobby = res.split('|')
print(res.split('|', maxsplit=1)) # ['jason', '123|read'] 从左往右切指定个数 maxsplit:最大切割数
print(res.rsplit('|',maxsplit=1)) # ['jason|123', 'read'] 从右往左切指定个数
7.字符串格式化输出
format玩法1:等价于占位符
res = 'my name is {} my age is {}'.format('jason',123)
print(res) # my name is jason my age is 123
format玩法2:索引取值并反复使用
res = 'my name is {0} my age is {1} {0} {0} {1}'.format('jason',123)
print(res) # my name is jason my age is 123 jason jason 123
format玩法3:占位符见名知意
res = 'my name is {name1} my age is {age1} {name1} {age1} {name1} '.format(name1='jason', age1=123)
print(res)
format玩法4:推荐使用
name = input('username>>>:')
age = input('age>>>:')
res = f'my name is {name} my age is {age}'
print(res) # my name is jason my age is 18
3.字符串需要了解的方法
1.大小写相关
'''upper:转化成大写 lower:转化成小写'''
res = 'HeLlO wOrlD 123'
print(res.upper()) # HELLO WORLD 123
print(res.lower()) # hello world 123
eg:
'''图片验证码:生成没有大小写统一的验证码 展示给用户看
获取用户输入的验证码 将用户输入的验证码和当初产生的验证码统一转大写或者小写再比对
'''
code = '8Ja6Cc'
print('展示给用户看的图片验证码', code)
confirm_code = input('请输入验证码').strip()
if confirm_code.upper() == code.upper():
print('验证码正确')
res = 'hello world'
print(res.isupper()) # 判断字符串是否是纯大写 False
print(res.islower()) # 判断字符串是否是纯小写 True
2.判断字符串中是否是纯数字
isdight:判断是否是数字
res = ''
print(res.isdight())
guess_age = input('guess_age>>>:').strip
if guess_age.isdight():
guess_age = int(guess_age)
else:
print('年龄要输数字哦!')
3.替换字符串中指定的内容
replace:替换
res = 'my name is jason jason jason'
print(res.replace('jason', 'tony')) # my name is tony tony tony
print(res.replace('jason', 'tony', 1)) # my name is tony jason jason 从左往右替换指定个数内容
4.字符串的拼接
l1 = 'hello'
l2 = 'world'
print(l1 + '$$' + l2) # hello$$world
print(l1 * 3) # hellohellohello
print('|'.join(['jason', '123', 'read', 'JDB'])) # jason|123|read|JDB
print('|'.join(['jason', 123])) # 报错 参与拼接的数据值必须是字符串
5.统计指定字符出现的次数
res = 'hello world'
print(res.count('l')) # 3
6.判断字符串的开头或者结尾
starswith:开头 endswith:结尾
res = 'jason say hello'
print(res.startswith('jason')) # True
print(res.startswith('j')) # True
print(res.startswith('jas')) # True
print(res.startswith('a')) # False
print(res.startswith('son')) # False
print(res.startswith('say')) # False
print(res.endswith('o')) # True
print(res.endswith('llo')) # True
print(res.endswith('hello')) # True
7.其他方式补充
res = 'helLO wORld hELlo worLD'
print(res.title()) # Hello World Hello World 每个单词首字母大写
print(res.capitalize()) # Hello world hello world 字符串内第一个单词首字母大写
print(res.swapcase()) # HELlo WorLD HelLO WORld 大小写转换
print(res.index('O')) # 索引的意思,缺点是它只会从左到右找到第一个符合的
print(res.find('O')) # 4
print(res.index('c')) # 找不到直接报错
print(res.find('c')) # 找不到默认返回-1
print(res.find('LO')) # 3
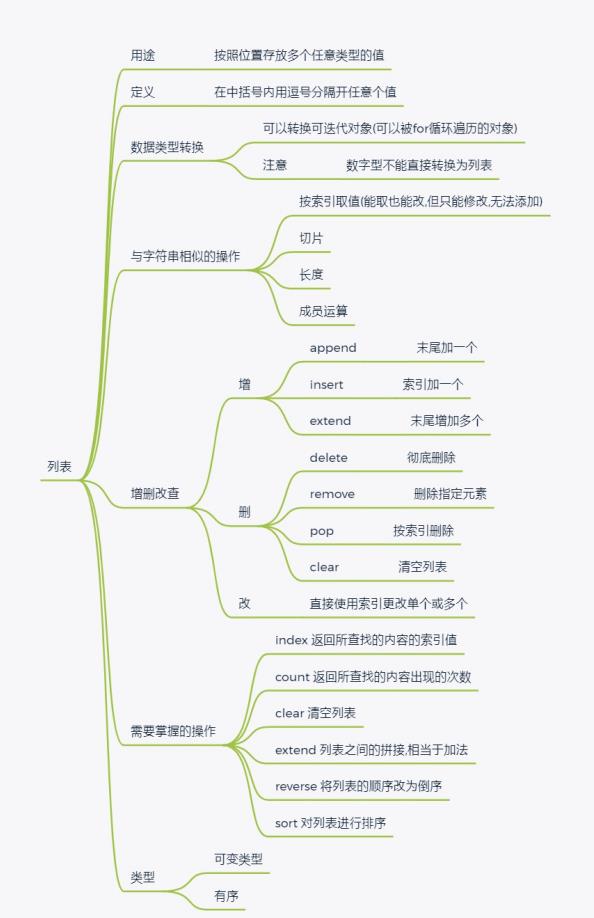
五.列表list的内置方法与操作
1.类型转换
list(其他数据类型)
ps:能够被for循环的数据类型都可以转成列表
print(list('hello'))
print(list({'name': 'jason', 'pwd': 123}))
print(list((1, 2, 3, 4)))
print(list({1, 2, 3, 4, 5}))
2.需要掌握的方法
1.索引取值
11 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1[0]) # 111
print(l1[-1]) # 888 支持负数
2.切片操作(与字符串讲解操作一致)
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1[0:5]) # [111, 222, 333, 444, 555] 骨头不顾尾 从索引1一直切取到索引4
print(l1[:]) # [111, 222, 333, 444, 555, 666, 777, 888] 不写数字就是全部使用
3.间隔数 方向(与字符串讲解操作一致)
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1[::-1]) # [888, 777, 666, 555, 444, 333, 222, 111]
4.统计列表中数据中的个数
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(len(l1)) #8
5.数据值修改
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1[0] = 123
print(l1) # [123, 222, 333, 444, 555, 666, 777, 888]
6.列表添加数据值
方式1:尾部追加数据值
l1.append('干饭')
print(l1) # [111, 222, 333, 444, 555, 666, 777, 888, '干饭']
l1.append(['jason', 'kevin', 'jerry'])
print(l1) # [111, 222, 333, 444, 555, 666, 777, 888, ['jason', 'kevin', 'jerry']]
方式2:任意位置插入数据值
l1.insert(0, 'jason')
print(l1)
l1.insert(1, [11, 22, 33, 44])
print(l1) # [111, [11, 22, 33, 44], 222, 333, 444, 555, 666, 777, 888]
方式3:扩展列表 合并列表
ll1 = [11, 22, 33]
ll2 = [44, 55, 66]
print(ll1 + ll2) # [11, 22, 33, 44, 55, 66]
ll1.extend(ll2) # for循环+append
print(ll1) # [11, 22, 33, 44, 55, 66]
for i in ll2:
ll1.append(i)
print(ll1)
7.删除列表数据
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
方式1:通用的删除关键字del
del l1[0]
print(l1)
方式2:remove
l1.remove(444) # 括号内填写数据值
print(l1)
方式3:pop
l1.pop(3) # 括号内填写索引值
print(l1)
l1.pop() # 默认尾部弹出数据值
print(l1)
res = l1.pop(3)
print(res) # 444
res1 = l1.remove(444)
print(res1) # None
8.排序
ss = [54, 99, 55, 76, 12, 43, 76, 88, 99, 100, 33]
ss.sort() # 默认是升序
print(ss) # [12, 33, 43, 54, 55, 76, 76, 88, 99, 99, 100]
ss.sort(reverse=True)
print(ss) # 改为降序 [12, 33, 43, 54, 55, 76, 76, 88, 99, 99, 100]
9.统计列表中某个值出现的次数
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1.count(111)) # 1
10.颠倒列表顺序
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1.reverse()
print(l1) # [888, 777, 666, 555, 444, 333, 222, 111]
六.可变与不可变类型
s1 = '$$jason$$'
l1 = [11, 22, 33]
s1.strip('$')
print(s1) # $$jason$$
'''字符串在调用内置方法之后并不会修改自己 而是产生了一个新的结果
如何查看调用方法之后有没有新的结果 可以在调用该方法的代码左侧添加变量名和赋值符号
res = s1.strip('$')
'''
ret = l1.append(44)
print(l1) # [11, 22, 33, 44]
print(ret) # None
'''列表在调用内置方法之后修改的就是自身 并没有产生一个新的结果'''
可变类型:值改变 内存地址不变
l1 = [11, 22, 33]
print(l1)
print(id(l1))
l1.append(44)
print(l1)
print(id(l1))
不可变类型:值改变 内存地址肯定变
res = '$$hello world$$'
print(res)
print(id(res))
res.strip('$')
print(res)
print(id(res))
七.字典dict的内置方法与操作
1.类型转换
dict()
字典的转换一般不使用关键字 而是自己动手转
2.字典必须掌握的操作
1.按k取值(不推荐使用)
user_dict = {
'username': 'kun',
'password': 1998,
'hobby': ['sing', 'dance', 'rap', 'basketball']
}
print(user_dict['username']) # kun
print(user_dict['phone']) # k不存在会直接报错
2.按内置方法get取值(推荐使用)
user_dict = {
'username': 'kun',
'password': 1998,
'hobby': ['sing', 'dance', 'rap', 'basketball']
}
print(user_dict.get('username')) # kun
print(user__dict.get('age')) # None
print(user_dict.get('username', '积泥钛酶')) # kun 键存在的情况下获取对应的值
print(user_dict.get('phone', '积泥钛酶')) # None 积泥钛酶 键不存在默认返回 None 可以通过第二个参数自定义
3.修改值数据
user_dict = {
'username': 'kun',
'password': 1998,
'hobby': ['sing', 'dance', 'rap', 'basketball']
}
print(id(user_dict))
user_dict['username'] = 'jason' # 键存在则修改对应的值
print(id(user_dict)) # 内存地址不变
print(user_dict) # {'username': 'jason', 'password': 1998, 'hobby': ['sing', 'dance', 'rap', 'basketball']}
4.新增键值对
user_dict = {
'username': 'kun',
'password': 1998,
'hobby': ['sing', 'dance', 'rap', 'basketball']
}
user_dict['age'] = 18 #键不存在则新增键值对
print(user_dict) # {'username': 'kun', 'password': 1998, 'hobby': ['sing', 'dance', 'rap', 'basketball'], 'age': 18}
5.删除数据
del user_dict['username']
print(user_dict)
res = user_dict.pop('password')
print(user_dict)
print(res) # 1998
6.统计字典中键值对的个数
print(len(user_dict)) # 3
7.字典三剑客
print(user_dict.key()) # 一次性获取字典所有的键 dict_keys(['username', 'password', 'hobby'])
print(user_dict.values()) # 一次性获取字典所有的值 dict_values(['kun', 1998, ['sing', 'dance', 'rap', 'basketball']])
print(user_dict.items()) # 一次性获取字典的键值对数据 dict_items([('username', 'jason'), ('password', 1998), ('hobby', ['sing', 'dance', 'rap', 'baskeball'])])
for i inuser_dict.items():
k, v = i
print(k, v)
8.补充说明
print(dict.formkeys(['name', 'pwd', 'hobby'], 123)) # 快速生成值相同的字典
res = dict.formkeys(['name', 'pwd', 'hobby'], [])
print(res) # {'name': [], 'pwd': [], 'hobby': []}
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
'''当第二个公共值是可变类型的时候一定要注意 通过任何一个键修改都会影响所有'''
res = user_dict.setdefault('username', 'tony')
print(user_dict, res) # 键存在则不修改 结果是键值对应的值
res = user_dict.setdefault('age', 123)
print(user_dict, res) # 存不存在则新增键值对 结果是新增的值
user_dict.popitem() # 弹出键值对后进先出
八.元组tuple的内置方法与操作
1.类型转换
tuple()
ps:支持for循环的数据类型都可以转成元组
2.元组必须掌握的方法
t1 = (11, 22, 33, 44, 55, 66)
# 1.索引取值
# 2.切片操作
# 3.间隔、方向、步长
# 4.统计元组内数据值的个数
print(len(t1)) # 6
# 5.统计元组内某个数据值出现的次数
print(ti.count(11))
# 6.统计元组内指定数据值的索引值
print(t1.index(22))
# 7.元组内如果只有一个数据值那么逗号不能少
# 8.元组内索引绑定的内存地址不能被修改(注意区分 可变与不可变)
# 9.元组不能新增或删除数据
九.集合set的内置方法与操作
1.类型转换
set()
集合内数据必须是不可变类型(整型 浮点型 字符串 元组)
集合内数据也是无序的 没有索引的概念
2.集合需要掌握的方法
1.去重
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(l1)
'''集合的去重无法保留原先的数据排列顺序'''
2.关系运算
群体之间差异化校验
eg:
f1 = {'jason', 'tony','jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2列表
# 1.求两个人的共同好友
print(f1 & f2) # {'jason', 'tony'}
# 2.求用户1独有的好友
print(f1 - f2) # {'jerry', 'oscar'}
# 3.求两个人的所有好友
print(f1 | f2) # {'jason', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
# 4.求两个人各自独有的好友
print(f1 ^ f2) # {'oscar', 'tom', 'jack', 'jerry'}
# 5.父集、子集
print(f1 > f2)
print(f1 < f2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号