数据采集与融合技术实践第三次作业
数据采集与融合技术实践第三次作业
姓名:刘心怡 学号:031904134 班级:2019级大数据一班
作业①
1)实验内容及结果
①实验内容
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.we ather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
②实验步骤
1.图片爬取
检查网页内容便可知,网页的图片全部都在img标签下

于是,设计爬虫如下
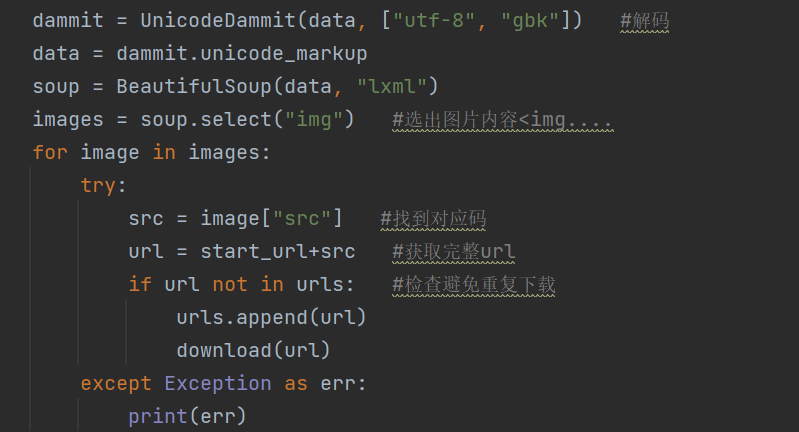
其中download是图片下载函数,下面会讲到
2.图片下载
要控制图片总数目,就必须写一个全局变量来控制具体数目,这里设为count,只有小于134的时候才可以执行下载操作。之后,就像之前的作业一样,把路径打开写入再关闭

3.翻页处理
这里的翻页处理和上次的天气爬取很相似,因此我便沿用了上次的方法,直接设置了一个url列表,让整个程序在列表的逐项选择中爬取各页,完成翻页功能,这里偷了个懒,因为页面比较少,我就直接把完整的复制了下来,要不然其实是应该找城市码然后逐一插入该固定格式的。

4.单线程改为多线程
由于我完成翻页是使用了循环,而这也大大降低了我设置多线程的难度,只要将3中的执行部分改成如下即可实现多线程爬取。
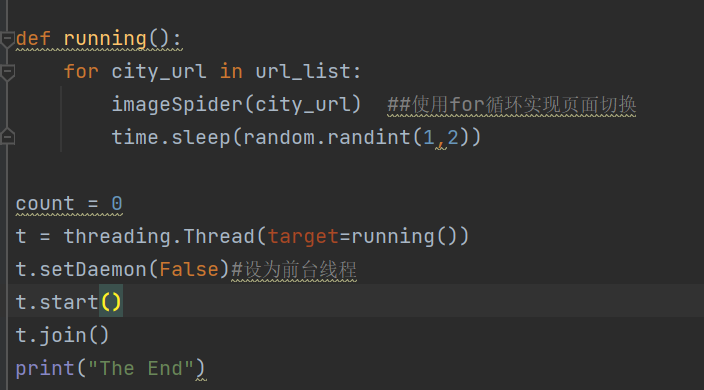
③代码链接
单线程代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/1.1.py
多线程代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/1.2.py
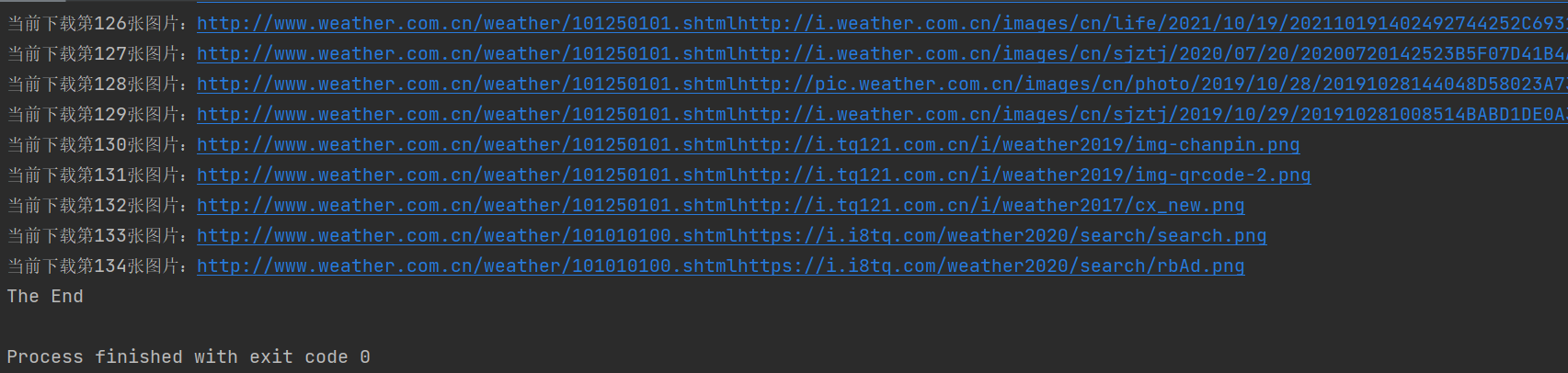
④运行结果:
1.单线程


2.多线程

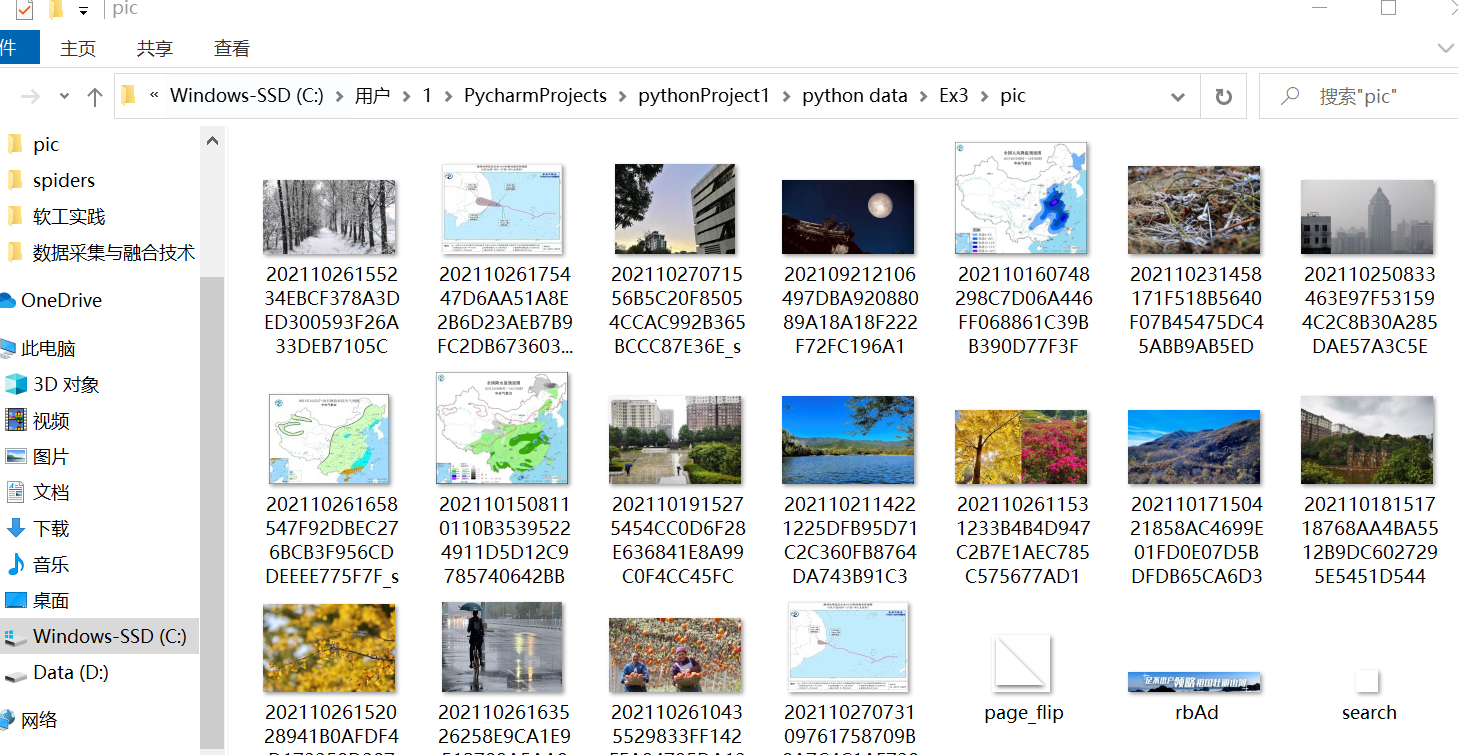
文件夹中结果:
2)心得体会
在作业①中系统的复习了基本的爬取以及翻页逻辑与图片下载逻辑,还有较为麻烦的线程处理,我在这一实验中受益颇多。
作业②
1)实验内容及结果
①实验内容
要求:使用scrapy框架复现作业①。
输出信息:同作业①
②实验步骤
首先,这次试验要求使用scrapy爬取网页图片,那么,便可设置items.py如下

之后,设置imgspider用xpath于爬取图片中图片的url,并且返回item,内部处理逻辑与作业①相似,不再赘述
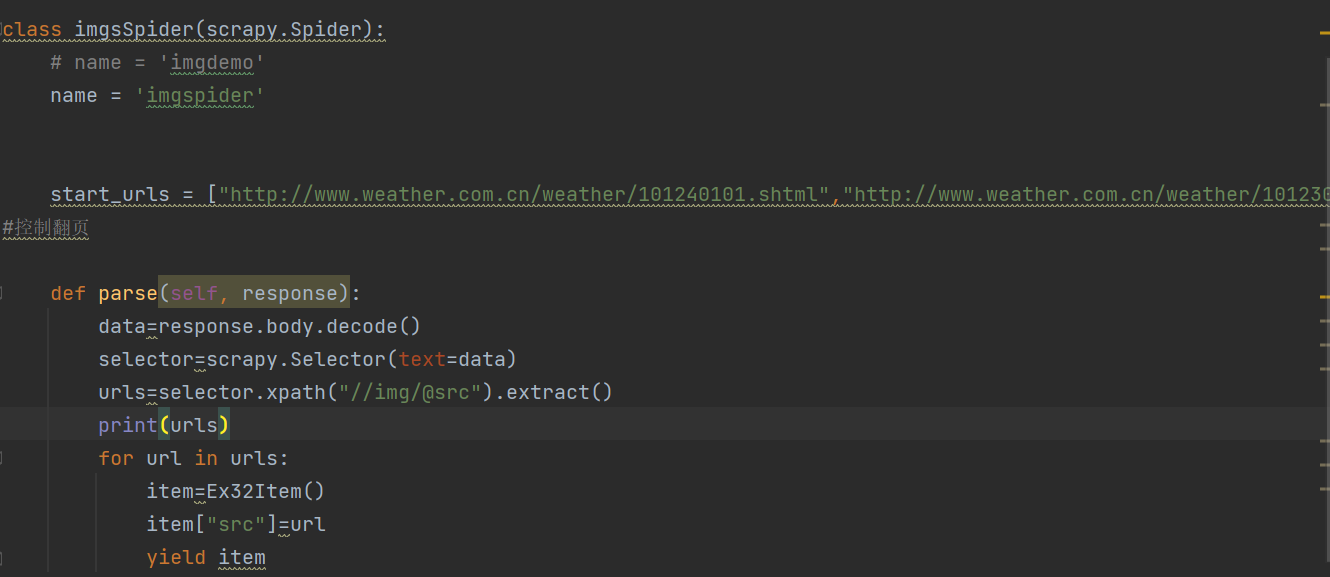
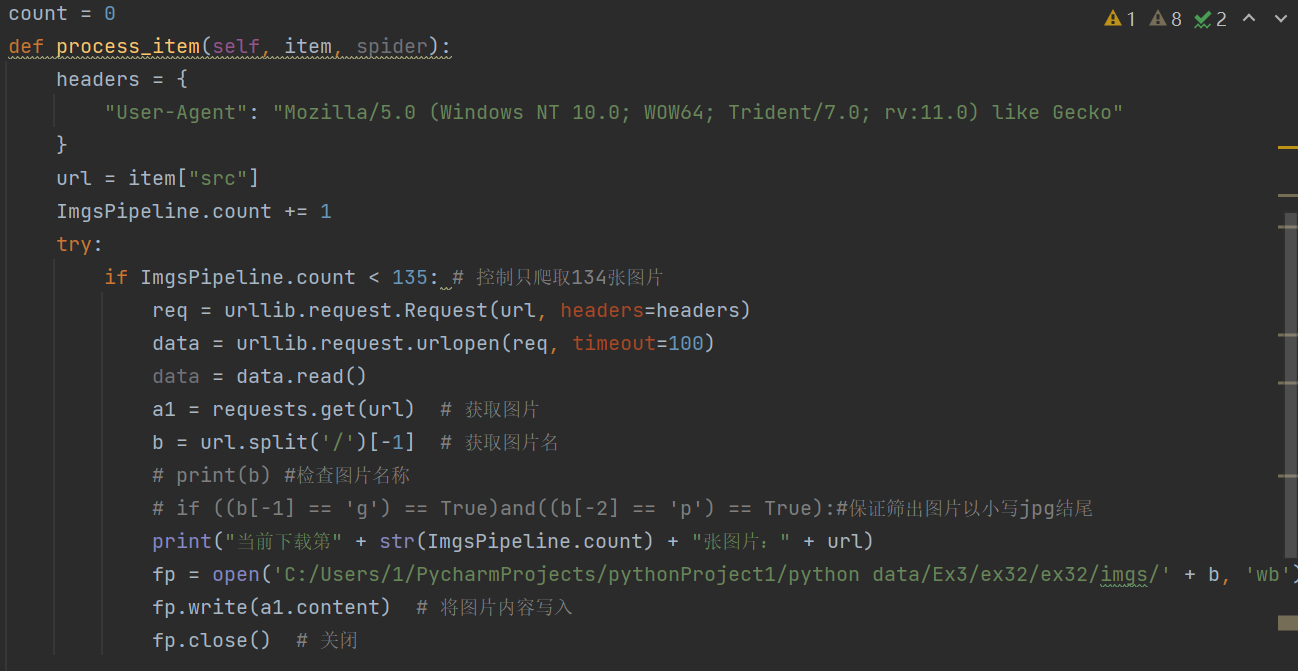
再次,设置pipelines对item进行处理,完成图片写入
最后,修改settings,保证可以执行

③代码链接
Items: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/items.py
Imgspider: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/imgspider.py
Pipelines:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/pipelines.py
Settings:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/settings.py
Run:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/run.py
④运行结果

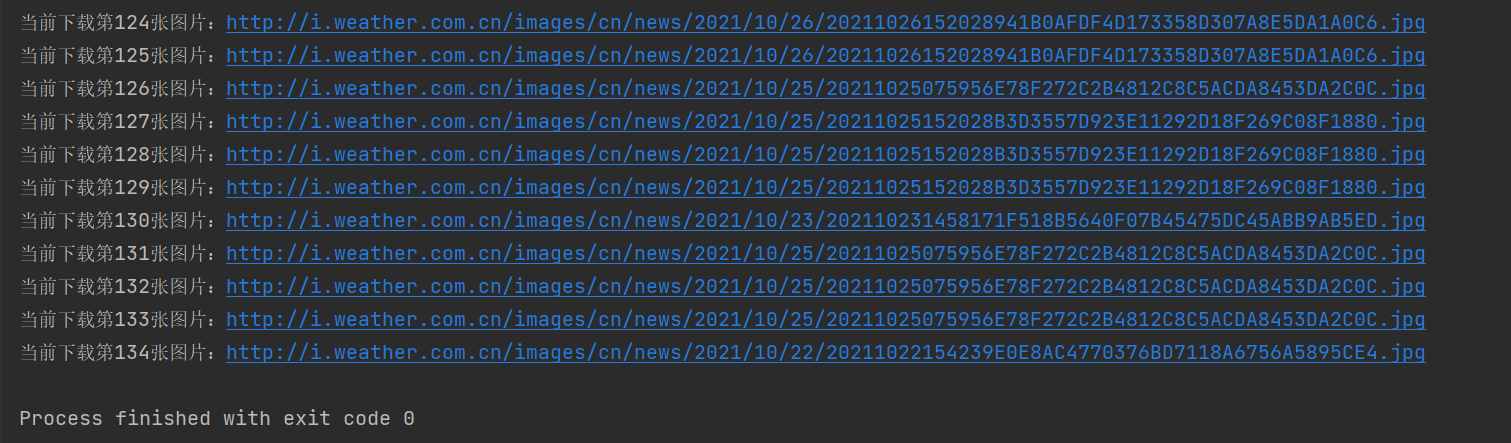

2)心得体会
在作业②中系统的学习了基本的使用scrapy框架爬取数据方法以及xpath爬取信息的方法,我在这一实验中一一体会,受益颇多。
作业③
1)实验内容及结果
①实验内容
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
候选网站: https://movie.douban.com/top250
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... |
②实验步骤
由需要爬取内容,可设置items.py如下:
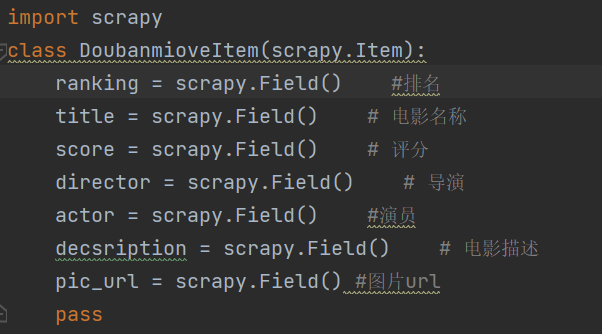
观察网页内容
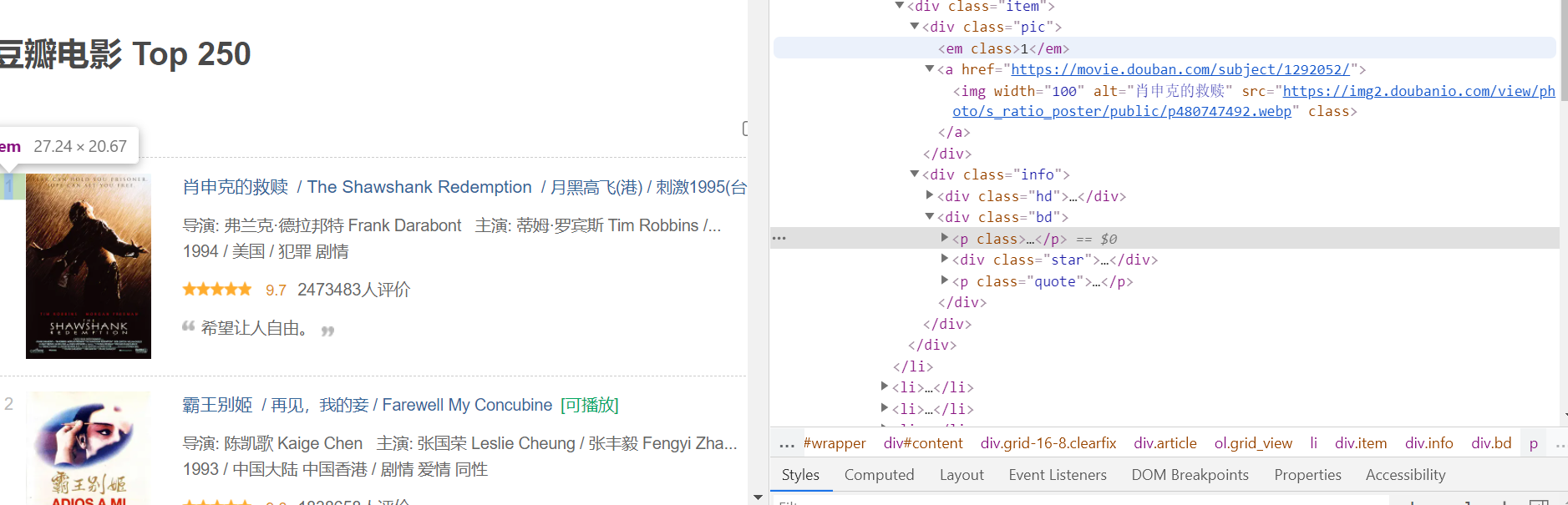
可发现各元素所处路径包含规律,因此可使用xpath如下:

其中导演主演同在一个字符串内,因此,可使用中间量bd先将其爬下来,后对该字符串进行分割,选取相应位置,即可实现导演主演内容爬取
随后,编写pipelines实现数据库插入与图片的爬取:


在navicat中创建数据库douban,表doubanmovie,并插入表头

③代码链接
Items: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/3/items.py
doubanproject: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/3/danbanproject.py
Pipelines: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/3/pipelines.py
Settings: https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/3/settings.py
Run:https://gitee.com/lyinkoy/crawl_project/blob/master/作业3/3/run.py
④运行结果


2)心得体会
在作业③中进一步学习了使用scrapy框架爬取数据方法以及使用xpath爬取信息的方法,此外还有与mysql的交互,我在这一实验中一一体会,受益颇多。

