Datawhale X 李宏毅苹果书 AI夏令营 Task3 批量归一化、卷积神经网络、自注意力机制原理 笔记
神经网络训练不起来怎么办(5):批次标准化(Batch Normalization)简介_哔哩哔哩_bilibili

Task3:《深度学习详解》- 3.7 批量归一化
- **产生不好训练的误差表面的原因**:输入特征不同维度的值范围差距大可能导致误差表面不好训练,如输入值小对损失影响小,输入值大对损失影响大。
- **特征归一化**:包括Z值归一化等方法,可使不同维度有相同数值范围,制造较好误差表面,加速损失收敛和训练。
- **深度学习中的归一化**:对深度学习中的特征进行归一化,如对z做特征归一化,要放在激活函数之前。归一化时考虑批量数据,批量大小要足够大,批量归一化时还会加上β和γ作为网络参数来调整输出分布。
- **批量归一化的实现**:实际实现时只对批量数据做归一化,批量大小较大时可近似代表数据集分布。初始训练时γ为1,β为0,训练一段时间后再加入γ和β,对训练有帮助。
卷积神经网络 (Convolutional Neural Networks, CNN)_哔哩哔哩_bilibili
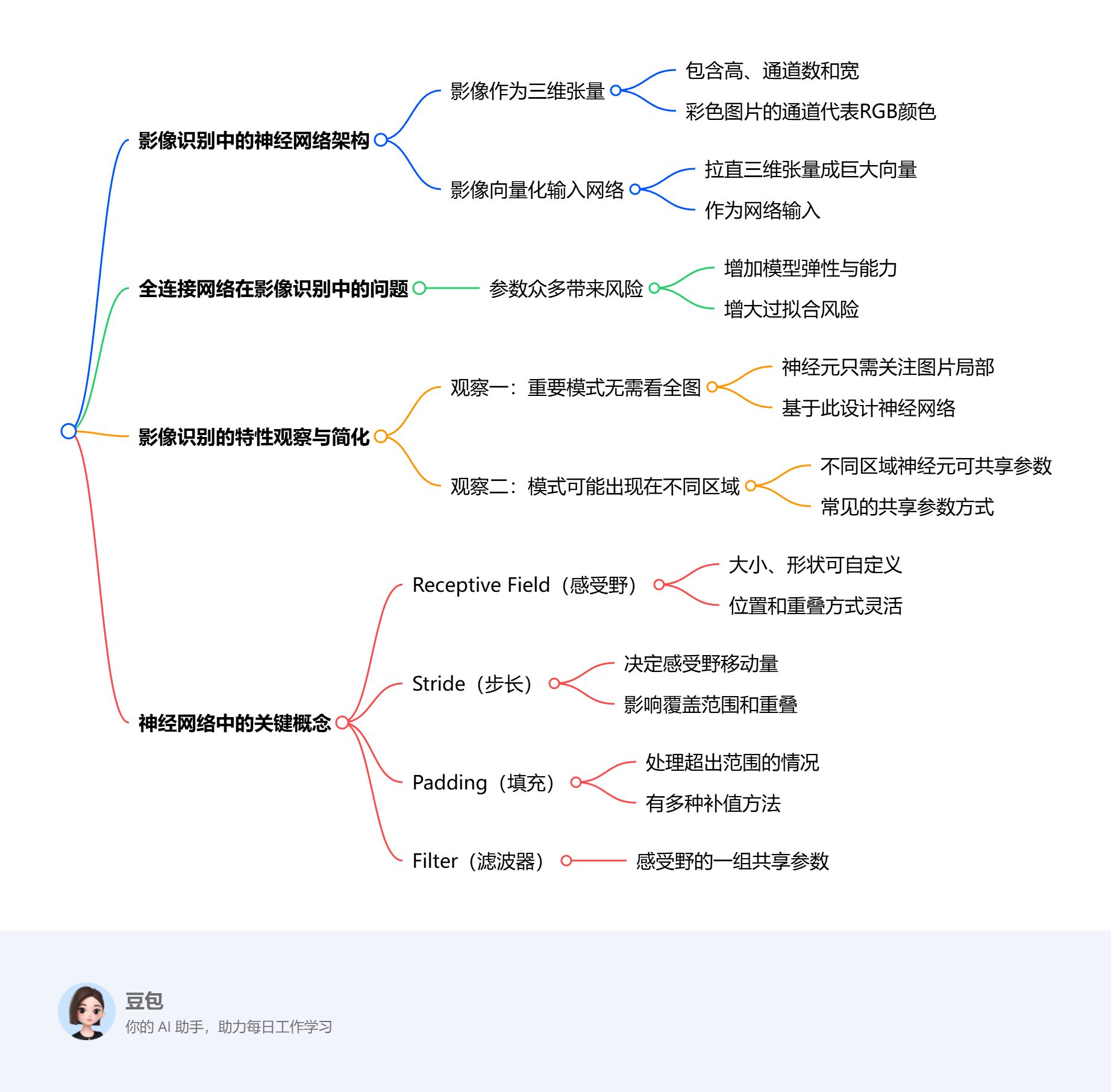
Task3.2:《深度学习详解》- 4.1&2&3&4 卷积神经网络-上
主要介绍了卷积神经网络(CNN)的核心概念和设计原则。通过观察图像识别中模式检测的局部性和重复性,提出了两个主要的简化策略:局部感受野和参数共享。通过这些策略,CNN能够有效地识别图像中的模式,同时减少计算复杂度和参数数量。
**关键段落**
- **局部感受野**: 文章首先指出,神经网络在识别图像中的物体时,并不需要观察整张图像,而只需关注图像的局部区域。这启发了卷积神经网络设计中的局部感受野概念,即每个神经元只关注图像的一个局部区域。
- **感受野的设计**: 感受野可以有不同的大小和形状,并且可以重叠。步幅(stride)和填充(padding)是设计感受野时需要考虑的两个重要参数,它们影响神经元如何覆盖整个图像。
- **参数共享**: 由于相同的模式可能出现在图像的不同区域,文章提出了参数共享的概念,即不同位置的神经元可以共享相同的权重。这种设计大大减少了模型的参数数量,同时保持了对图像特征的检测能力。
- **滤波器**: 在卷积神经网络中,每个感受野的一组神经元共享的参数被称为滤波器。通过使用滤波器,网络可以高效地在不同位置检测相同的特征。
- **简化策略的总结**: 文章最后总结了局部感受野和参数共享这两个简化策略,强调它们在提高CNN效率和减少参数数量方面的重要性。
Task3.3:《深度学习详解》- 4.5&6&7&8 卷积神经网络-下
主要介绍了卷积神经网络(CNN)的基本概念、结构和应用。文章详细解释了卷积层的工作原理,包括滤波器的作用、参数共享、下采样对模式检测的影响,以及汇聚(如最大汇聚和平均汇聚)的操作。此外,还探讨了CNN在图像识别、下围棋等任务中的应用,并讨论了其在语音和文本处理中的潜在用途。文章强调了CNN在处理图像缩放和旋转方面的局限性,并提到了数据增强技术的重要性。
**关键段落**
- **卷积神经网络基础**: 介绍了卷积层的基本概念,包括滤波器的作用和参数共享,以及如何通过多层卷积来检测更大范围的模式。
- **下采样与模式检测**: 讨论了下采样对图像识别任务中模式检测的影响,指出适当的下采样不会损害图像中重要模式的识别。
- **汇聚操作**: 描述了汇聚(pooling)操作,包括最大汇聚和平均汇聚,以及它们在图像识别中的作用。
- **CNN在图像识别中的应用**: 探讨了CNN在图像识别任务中的应用,包括如何通过卷积和汇聚操作来提取图像特征。
- **CNN在围棋中的应用**: 分析了CNN在下围棋任务中的应用,解释了如何将棋盘视为图像,并使用CNN来预测最佳落子位置。
- **CNN的局限性与数据增强**: 讨论了CNN在处理图像缩放和旋转方面的局限性,并强调了数据增强技术在提高CNN性能中的重要性。
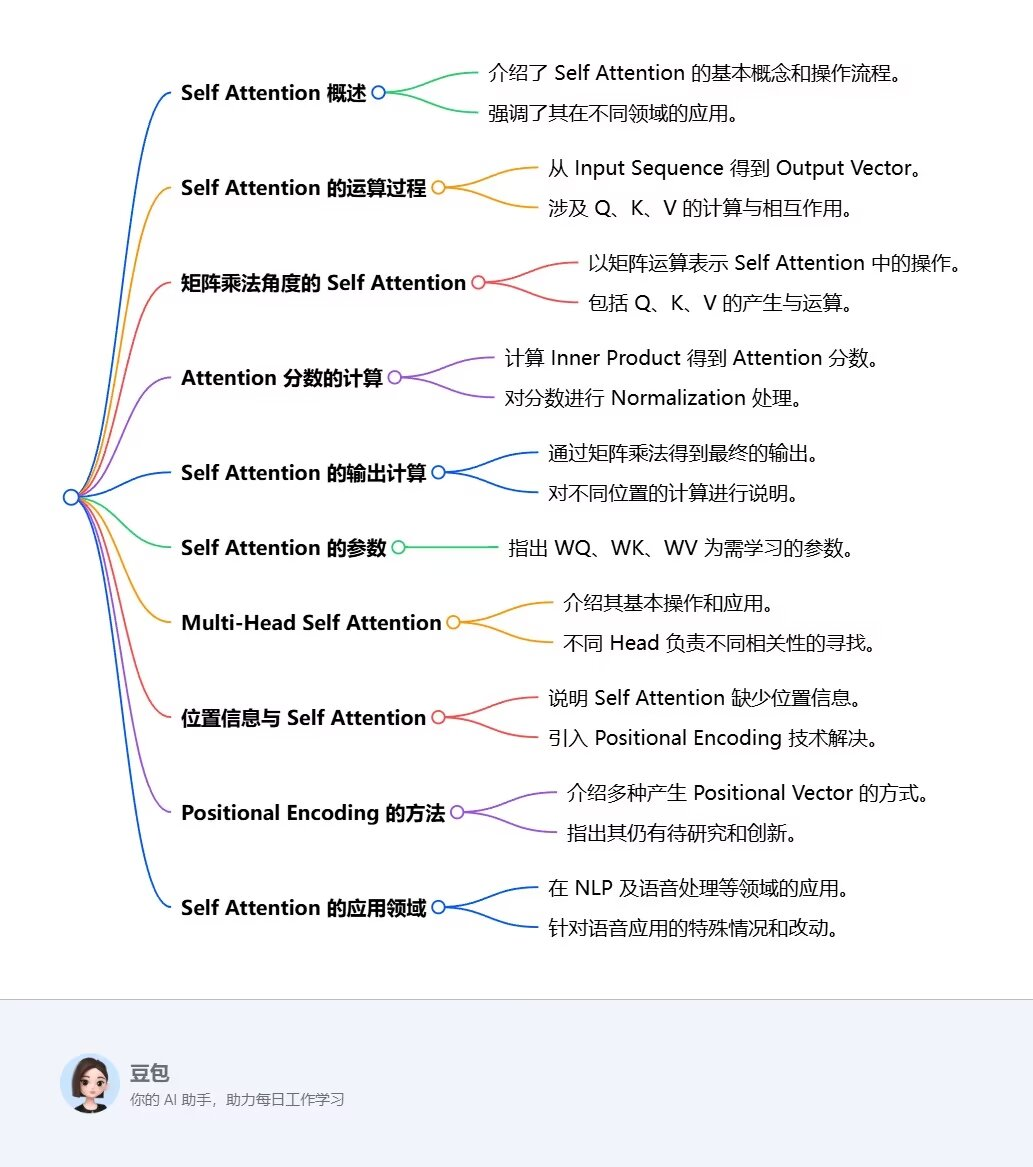
《深度学习详解》- 6.1&2 自注意力机制允许模型在处理序列数据时考虑整个序列的信息,而不仅仅是局部上下文。
**重要亮点**
- **自注意力机制的基本原理**:通过将输入向量分别乘以不同矩阵得到查询(q)、键(k)和值(v),计算q与k的内积得到关联性α,再进行softmax操作得到α′,根据α′抽取重要信息。
- **自注意力机制的矩阵乘法角度**:输入向量组成的矩阵分别乘以三个不同矩阵得到Q、K和V,通过KT乘Q得到注意力分数矩阵,对其进行归一化处理,再与V相乘得到自注意力的输出。
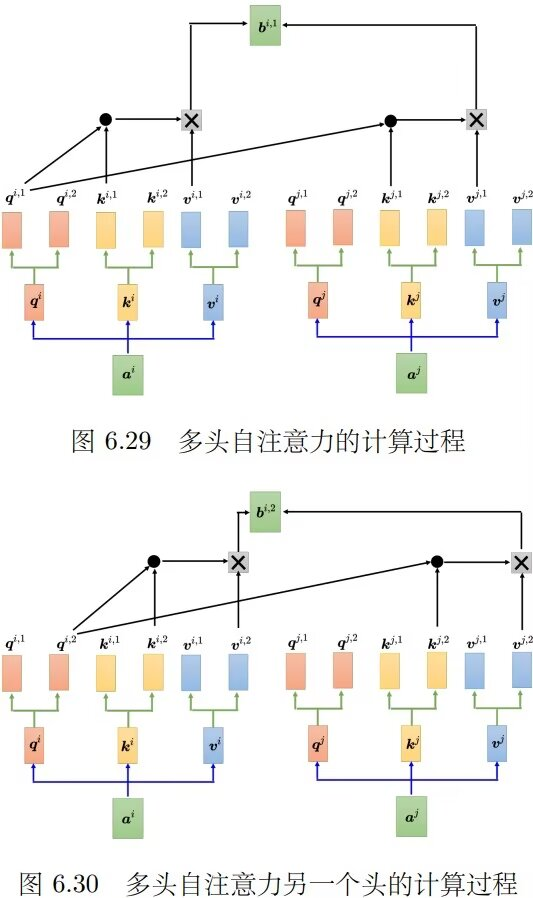
- **多头自注意力**:多头自注意力是自注意力的进阶版本,使用多个头来计算不同种类的相关性,不同位置的q、k、v分别乘以矩阵得到不同的头,每个头分别进行自注意力计算,最后可能将结果拼接并通过变换得到最终输出。
- **参数学习**:自注意力层中唯一需要学习的参数是Wq、Wk和Wv,其他操作的参数人为设定,无需通过训练数据学习。
- **应用与超参数**:多头自注意力在翻译、语音识别等任务中应用广泛,头的数量是需要调整的超参数。
李宏毅机器学习课程自注意力机制Self-Attention(下)思维导图:
多头子注意力的计算过程:
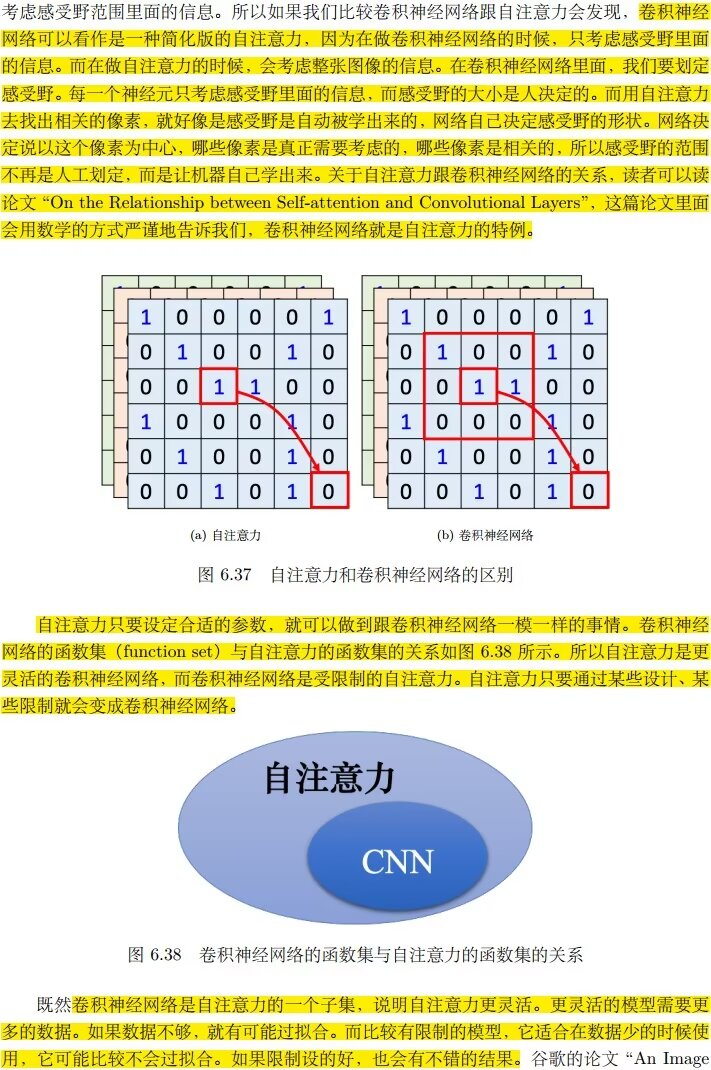
自注意力是更灵活的卷积神经网络,而卷积神经网络是受限制的自注意力:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号