Datawhale X 李宏毅苹果书 AI夏令营 Task2笔记
- **训练网络时的梯度和损失变化**:训练网络时损失可能不再下降,但梯度范数不一定小,梯度可能在山谷壁间“震荡”,多数训练未到临界点就停止。
- **不同学习率的影响**:学习率过大或过小都会影响训练效果,过大步伐大无法滑到谷底,过小则难以靠近局部最小值。
- **自适应学习率方法**:包括AdaGrad能根每个参数的梯度大小自动调整学习率;RMSProp可动态调整同一参数不同时间的学习率;Adam是RMSprop加上动量,能自适应调整学习率。
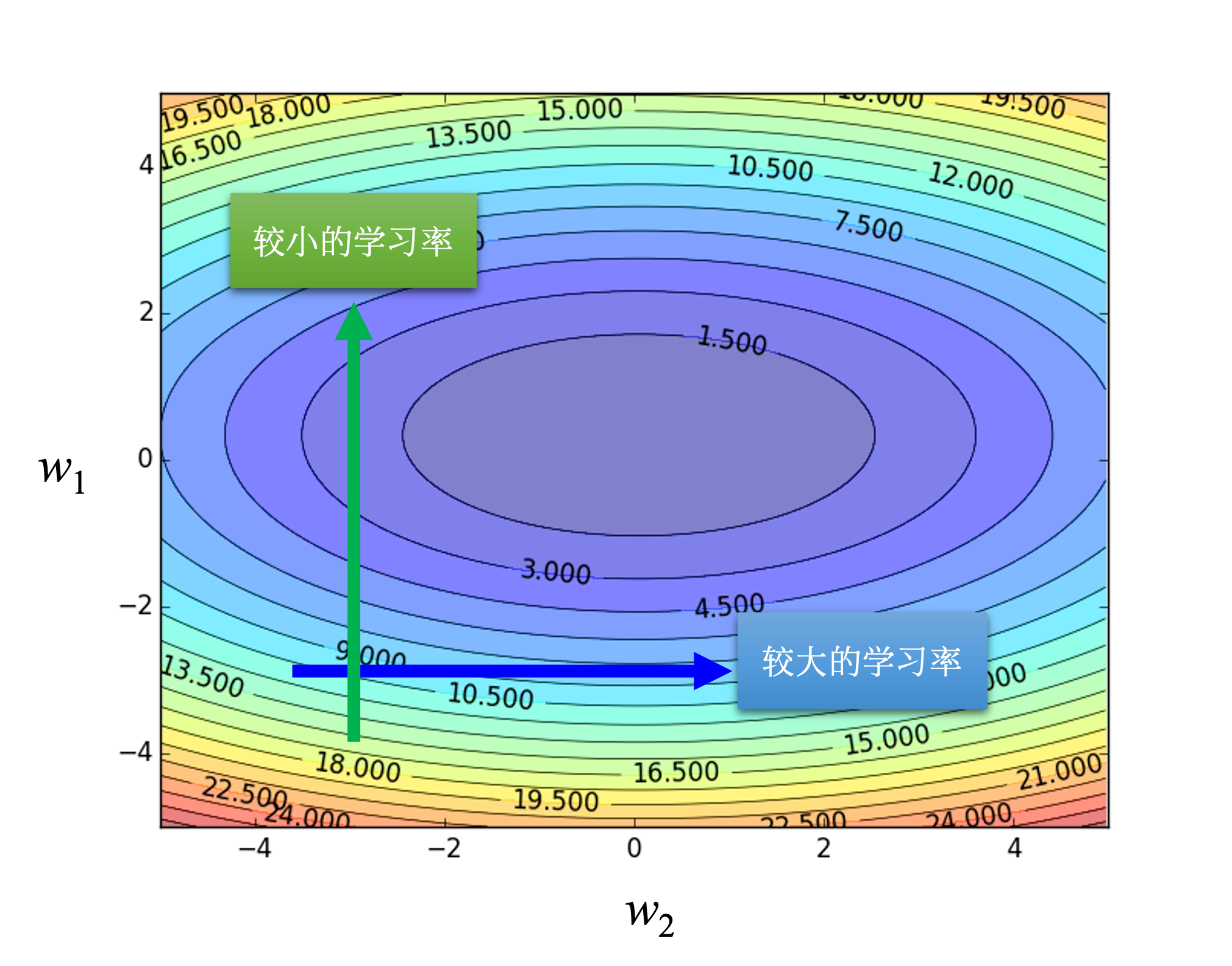
- **AdaGrad**: 根据每个参数的梯度大小自动调整学习率,使得在梯度大时学习率减小,在梯度小时学习率增大。
-
梯度大时减小学习率:当某个参数的梯度值很大时,意味着在这个方向上模型的损失下降很快。如果此时学习率还保持较高,可能会导致参数更新步长过大,从而越过最小值,造成震荡甚至发散。因此,减小学习率可以使得参数更新更加稳健,避免“超调”。
-
梯度小时增大学习率:反之,当某个参数的梯度值很小时,说明在这个方向上损失下降缓慢,可能意味着当前的学习率过小,导致学习过程过于缓慢。此时增大学习率可以加快学习过程,更快地逼近最小值。
- **RMSProp**: 同一个参数需要的学习率,也会随着时间而改变。通过引入超参数α来调整当前梯度与之前梯度的权重,实现学习率的动态调整。
- **Adam优化器**: 是RMSProp加上动量的方法,能够同时考虑参数更新的方向和大小,实现更有效的训练。
- **学习率调度**:通过让学习率与时间相关,采用学习率衰减策略,可解决训练中出现的问题,使训练更顺利地达到终点。

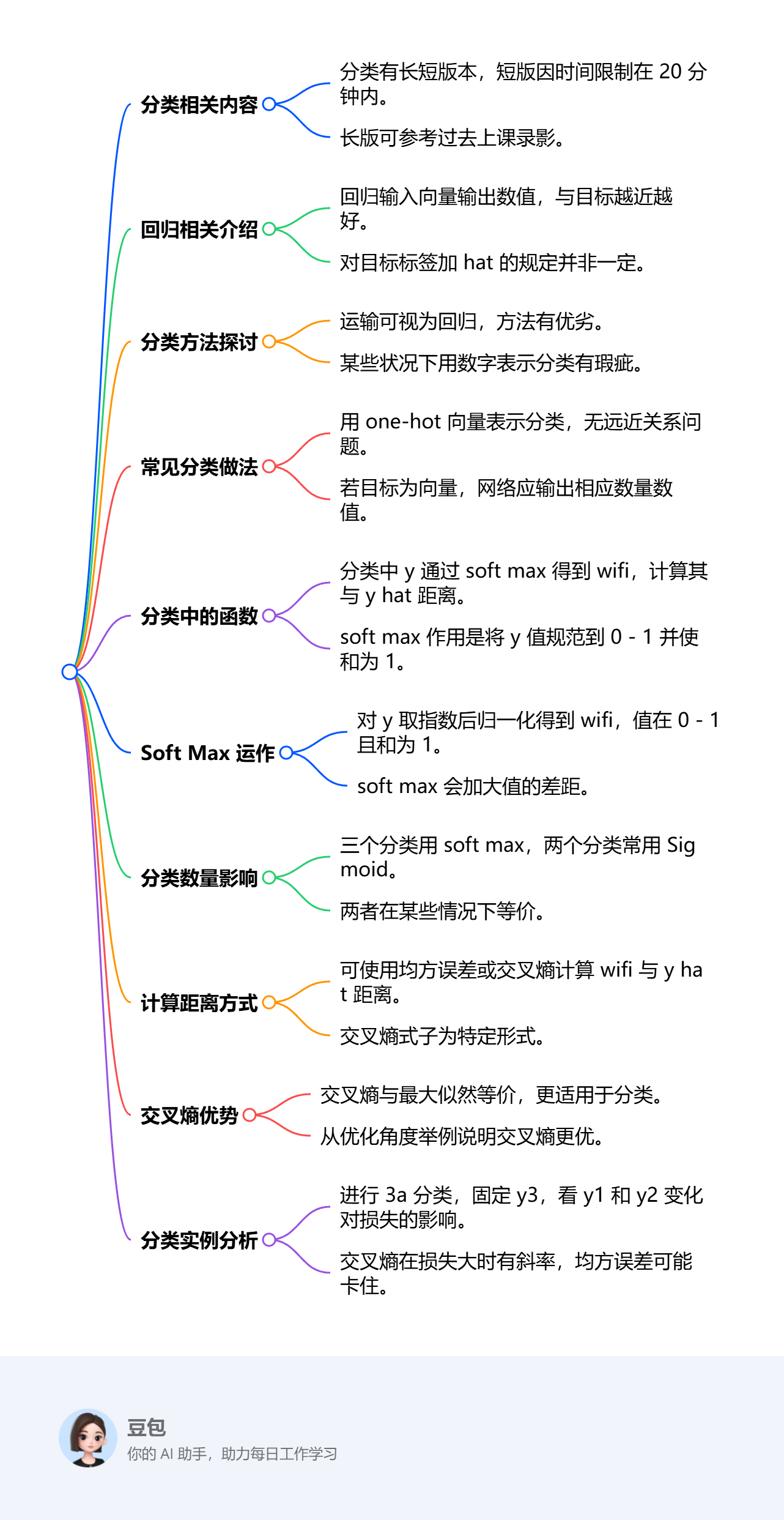
神经网络训练不起来怎么办(4):损失函数(Loss)也可能有影响_思维导图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号