python:多进程
多任务编程
意义:充分利用计算机的资源提高程序的运行效率
定义:通过应用程序利用计算机多个核心,达到同时执行多个任务的目的
实施方案: 多进程、多线程
并行:多个计算机核心并行的同时处理多个任务
并发:内核在多个任务间不断切换,达到好像内核在同时处理多个任务的运行效果
程序:是一个可执行文件,是静态的,占有磁盘,不占有计算机运行资源
进程:程序在计算机中运行一次的过程、进程是一个动态的过程描述,占有CPU内存等计算机资源的,有一定的生命周期
* 同一个程序的不同执行过程是不同的进程,因为分配的计算机资源等均不同
父子进程:系统中每一个进程(除了系统初始化进程)都有唯一的父进程,可以有0个或多个子进程。父子进程关系便于进程管理。
进程
CPU时间片:如果一个进程在某个时间点被计算机分配了内核,我们称为该进程在CPU时间片上。
PCB(进程控制块):存放进程消息的空间
进程ID(PID):进程在操作系统中的唯一编号,由系统自动分配
进程信息:进程PID,进程占有的内存位置,创建时间,创建用户. . . . . . . .
进程特征:
- 进程是操作系统分配计算机资源的最小单位
- 每一个进程都有自己单独的虚拟内存空间
- 进程间的执行相互独立,互不影响
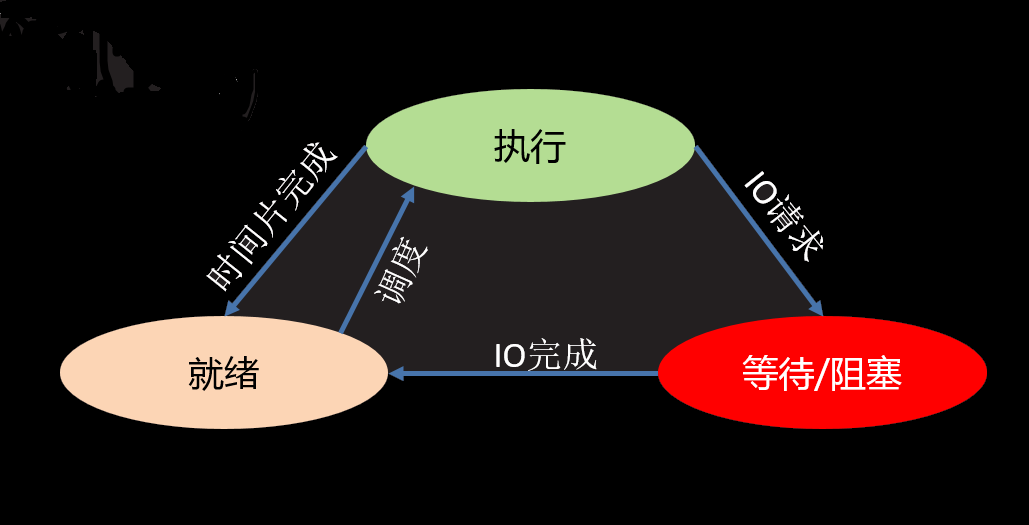
进程的状态
三态
- 就绪态:进程具备执行条件,等待系统分配CPU
- 运行态:进程占有CPU处理器,处于运行状态
- 等待态:进程暂时不具备运行条件,需要阻塞等待,让出CPU
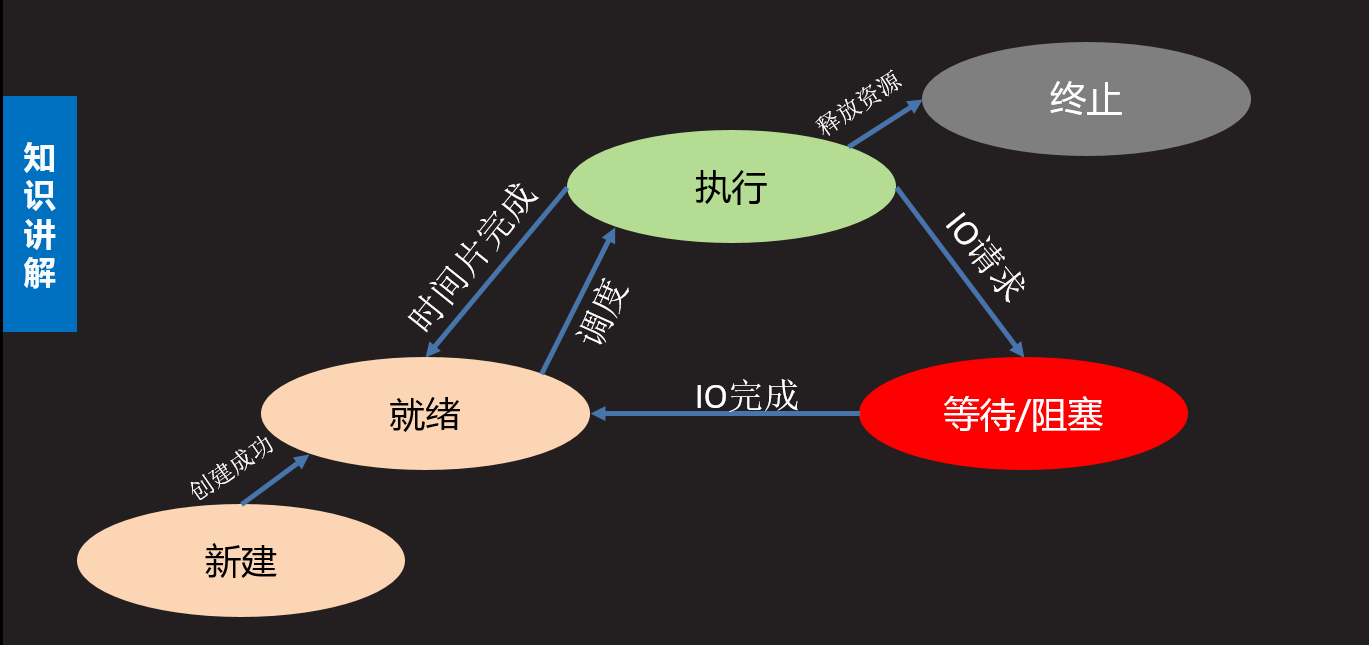
五态(增加新建态和终止态)
- 新建态:创建一个新的进程,获取资源的过程
- 终止态:进程结束释放资源的过程
查看进程树:pstree
查看父进程PID:ps -ajx
linux查看进程命令:ps -aux
fork创建进程
Unix/Linux操作系统提供了一个fork()系统用于创建子进程,
由于Windows没有fork调用,在Windows上无法运行。而Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的
pid = os.fork() # 创建一个子进程
普通的函数调用一次返回一次,但 os.fork()会把当前进程(父进程)复制了一份(子进程),然后,分别在父进程和子进程内返回。
- 在子进程中 返回0
- 在父进程中 返回子进程ID
- 创建失败 返回负数
import os from time import sleep pid = os.fork() if pid < 0: print("创建进程失败") #子进程 elif pid == 0: print("子进程") #父进程 else: sleep(1) print("父进程") print("程序执行完毕") # 子进程 # 父进程 # 程序执行完毕
进程之间相互独立,互不影响,比如:
- 子进程会复制父进程全部代码段(包括fork前的代码),但是子进程仅从fork的下一句开始执行
- 父进程不一定先执行
- 父子进程各有自己的属性特征,比如:PID号PCB内存空间
父子进程的变量域


import os from time import sleep a = 1 pid = os.fork() if pid < 0: print("创建进程失败") elif pid == 0: print("子进程") print("a = ",a) a = 10000 print("a = ",a) else: sleep(1) print("父进程") print("parent a :",a) # a = 1 # 子进程 # a = 1 # a = 10000 # 父进程 # parent a : 1
进程ID
os.getpid():获取当前进程的PID号
os.getppid():获取父类进程的进程号
import os pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("Child PID:", os.getpid()) # 26537 print("Get parent PID:", os.getppid()) # 26536 else: print("Get child PID:", pid) # 26537 print("Parent PID:", os.getpid()) # 26536
退出进程
os._exit(status) 退出进程,status为进程的退出状态,整数
sys.exit([status]) 退出进程,status 如果为 整数则表示退出状态;符串则表示退出时打印内容,可以通过捕获SystemExit异常阻止退出
import os,sys # os._exit(0) # 退出进程 try: sys.exit("退出") except SystemExit as e: print("退出原因:",e) # 退出原因: 退出
孤儿和僵尸
孤儿进程
定义:父进程先于子进程退出,此时子进程就会变成孤儿进程
孤儿进程会被系统指定的进程收养,即系统进程会成为该孤儿进程新的父进程。孤儿进程退出时该父进程会处理退出状态
僵尸进程
定义:子进程先于父进程退出(子进程先死了),父进程没有处理子进程退出状态(父进程没有替子进程收尸),此时子进程成为僵尸进程(子进程带着怨气就成为了僵尸)
僵尸进程已经结束,但是会滞留部分PCB信息在内存,大量的僵尸会消耗系统资源,应该尽量避免
如何避免僵尸进程的产生
方法一:父进程处理子进程退出状态
pid, status = os.wait()
在父进程中阻塞等待处理子进程的退出
返回:
- pid:退出的子进程的PID号
- status:子进程的退出状态
import os, sys pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("子进程 PID", os.getpid()) # 31349 sys.exit(1) else: pid, status = os.wait() # 阻塞等待子进程退出 print("父进程 PID: ", pid) # 31349 print("子进程的退出状态:", os.WEXITSTATUS(status)) # 1
方法二:创建二级子进程
步骤:
- 父进程创建子进程等待子进程退出(爸爸生出儿子)
- 子进程创建二级子进程,然后子进程马上退出(儿子生出孙子,然后儿子挂了)
- 二级子进程成为孤儿,处理具体事件(孙子就进孤儿院了,孤儿院有院长带)
import os def fun1(): print("第一件事情") def fun2(): print("第二件事情") pid = os.fork() if pid < 0: print("Create process error") elif pid == 0: # 子进程 pid0 = os.fork() # 创建二级进程 if pid0 < 0: print("创建二级进程失败") elif pid0 == 0: # 二级子进程 fun2() # 做第二件事 else: # 二级进程 os._exit(0) # 二级进程退出 else: os.wait() fun1() # 做第一件事 # 第一件事情 # 第二件事情
方法三:通过信号处理子进程退出
原理:子进程退出时会发送信号给父进程,如果父进程忽略子进程信号,则系统就会自动处理子进程退出。
方法:使用signal模块在父进程中创建子进程前写如下语句 :
import signal signal.signal(signal.SIGCHLD,signal.SIG_IGN)
特点 : 非阻塞,不会影响父进程运行。可以处理所有子进程退出
Multiprocessing创建进程
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,可以通过multiprocessing模块编写多进程程序
步骤:
- 需要将要做的事情封装成函数
- multiprocessing.Process创建进程,并绑定函数
- start启动进程
- join回收进程
创建进程对象
p = multiprocessing.Process(target, name, args, kwargs)
参数:
- target : 要绑定的函数名
- name : 给进程起的名称 (默认Process-1)
- args: 元组 用来给target函数传参
- kwargs : 字典 用来给target函数键值传参
p.start():启动进程 自动运行terget绑定函数。此时进程被创建
p.join(timeout):阻塞等待子进程退出,最后回收进程,time是超时时间
p.name:进程名称
p.pid:对应子进程的PID号
p.is_alive():查看子进程是否在生命周期
p.daemon:设置父子进程的退出关系
如果等于True则子进程会随父进程的退出而结束,就不用使用 join(),必须要求在start()前设置
multiprocessing的注意事项:
- 使用multiprocessing创建进程子进程同样复制父进程的全部内存空间,之后有自己独立的空间,执行上互不干扰
- 如果不使用join回收可能会产生僵尸进程
- 一般父进程功能就是创建子进程回收子进程,所有事件交给子进程完成
- multiprocessing创建的子进程无法使用 ptint
import multiprocessing as mp def fun(): global a a = 10000 print("子进程 a = ", a) a = 1 p = mp.Process(target=fun) # 创建进程对象 p.start() # 启动进程 p.join() # 回收进程 print("父进程 a:", a) # 子进程事件 31404 # a = 10000 # 父进程 a: 1
进程池
如果有大量的任务需要多进程完成,而任务周期又比较短且需要频繁创建。此时可能产生大量进程频繁创建销毁的情况,消耗计算机资源较大,这个时候就需要进程池技术
进程池的原理:创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件全都处理完毕统一销毁。增加进程的重复利用,降低资源消耗。
1、创建进程池,在池内放入适当数量的进程
from multiprocessing import Pool pool = Pool(processes)
参数:
- processes:最多同时运行的进程数量,超出进程数会阻塞等下进程释放才会运行
返回 : 进程池对象
2、将事件封装函数,放入到进程池
pool.apply_async(fun, args, kwds)
参数:
- fun:要执行的函数名
- args:以元组为fun传参
- kwds:以字典为fun传参
返回值 : 返回一个事件对象,通过get()属性函数可以获取fun的返回值
3、关闭进程池
pool.close()
4、回收进程
pool.join()
案例:
from multiprocessing import Pool from time import ctime # 进程池事件 def worker(msg): print(msg) return ctime() pool = Pool(3) # 创建进程池,一定要放在 事件函数之后,不然会保错 # 向进程池添加执行事件 for i in range(4): msg = "Hello %d" % i # r 代表func事件的一个对象 r = pool.apply_async(func=worker, args=(msg,)) pool.close() # 关闭进程池 pool.join() # 回收进程池 # Hello 0 # Hello 1 # Hello 2 # Hello 3
Hello 0,1,2是立即执行的,而Hello 4要等待前面某个进程结束后才能执行。如果改成Pool(4)就能同时跑4个程序
进程间通信(IPC)
因为不同进程相互独立,如果想要资源共享,就需要管理好进程之间的通信,有以下方法:
- 管道通信
- 消息队列
- 共享内存
- 信号信号量
- 套接字
方法一:管道通信(Pipe)
在内存中开辟管道空间,生成管道操作对象,多个进程使用同一个管道对象进行读写即可实现通信
创建管道
from multiprocessing import Pipe fd1, fd2 = Pipe(duplex=True)
参数:
- duplex:默认表示双向管道,如果为False 表示单向管道
返回值:表示管道两端的读写对象;如果是双向管道均可读写;如果是单向管道fd1只读 fd2只写
fd.recv():从管道获取内容,当管道为空则阻塞
fd.send(data):向管道写入内容,data为要写入的数据
注意:
- multiprocessing中管道通信只能用于父子关系进程中
- 管道对象在父进程中创建,子进程通过父进程获取
案例:
from multiprocessing import Pipe, Process fd1, fd2 = Pipe() # 创建管道,默认双向管道 def fun1(): data = fd1.recv() # 从管道获取消息 print("管道2传给管道1的数据", data) inpu = "跟你说句悄悄话" fd1.send(inpu) def fun2(): fd2.send("肥水不流外人天") data = fd2.recv() print("管道1传给管道2的数据", data) p1 = Process(target=fun1) P2 = Process(target=fun2) p1.start() P2.start() p1.join() P2.join() # 管道2传给管道1的数据 肥水不流外人天 # 管道1传给管道2的数据 跟你说句悄悄话
方法二:消息队列
从内存中开辟队列结构空间,多个进程可以向队列投放消息,在取出来的时候按照先进先出顺序取出
创建队列对象
q = Queue(maxsize = 0)
参数:
- maxsize :默认表示系统自动分配队列空间;如果传入正整数则表示最多存放多少条消息
返回值 : 队列对象
向队列中存入消息
q.put(data, block, timeout)
参数:
- data:存放消息(python数据类型)
- block:默认为True表示当前队列满的时候阻塞,设置为False则表示非阻塞
- timeout:当block为True表示超时时间
返回值:返回获取的消息
从队列取出消息
q.get([block,timeout])
参数:
- block:设置是否阻塞 False为非阻塞;timeout 超时检测
返回值:返回获取到的内容
q.full():判断队列是否为满
q.empty():判断队列是否为空
q.qsize():判断当前队列有多少消息
q.close():关闭队列
from multiprocessing import Process, Queue from time import sleep from random import randint # 创建消息队列 q = Queue(3) # 请求进程 def request(): for i in range(2): x = randint(0, 100) y = randint(0, 100) q.put((x, y)) # 处理进程 def handle(): while True: sleep(1) try: x, y = q.get(timeout=2) except: break else: print("%d + %d = %d" % (x, y, x + y)) p1 = Process(target=request) p2 = Process(target=handle) p1.start() p2.start() p1.join() p2.join() # 12 + 61 = 73 # 69 + 48 = 117
方法三:共享内存
在内存中开辟一段空间,存储数据,对多个进程可见,每次写入共享内存中的数据会覆盖之前的内容,效率高,速度快
开辟共享内存空间
from multiprocessing import Value, Array obj = Value(ctype,obj)
参数:
- ctype:要转变的c的数据类型,对比类型对照表
- obj:共享内存的初始化数据
返回:共享内存对象
from multiprocessing import Process,Value import time from random import randint # 创建共享内存 money = Value('i', 5000) # 修改共享内存 def man(): for i in range(30): time.sleep(0.2) money.value += randint(1, 1000) def girl(): for i in range(30): time.sleep(0.15) money.value -= randint(100, 800) m = Process(target=man) g = Process(target=girl) m.start() g.start() m.join() g.join() print("一月余额:", money.value) # 获取共享内存值 # 一月余额: 4264
开辟共享内存
obj = Array(ctype,obj)
参数:
- ctype:要转化的c的类型
- obj:要存入共享的数据
- 如果是列表,将列表存入共享内存,要求数据类型一致
- 如果是正整数,表示开辟几个数据空间
from multiprocessing import Process, Array # 创建共享内存 # shm = Array('i',[1,2,3]) # shm = Array('i',3) # 表示开辟三个空间的列表 shm = Array('c',b"hello") #字节串 def fun(): # 共享内存对象可迭代 for i in shm: print(i) shm[0] = b'H' p = Process(target=fun) p.start() p.join() for i in shm: # 子进程修改,父进程中也跟着修改 print(i) print(shm.value) # 打印字节串 b'Hello'
方法四:信号量(信号灯集)
通信原理:给定一个数量对多个进程可见。多个进程都可以操作该数量增减,并根据数量值决定自己的行为。
创建信号量对象
from multiprocessing import Semaphore sem = Semaphore(num)
参数:
- num:信号量的初始值
返回值 : 信号量对象
sem.acquire():将信号量减1 当信号量为0时阻塞
sem.release():将信号量加1
sem.get_value():获取信号量数量
from multiprocessing import Process, Semaphore sem = Semaphore(3) # 创建信号量,最多允许3个任务同时执行 def rnewu(): sem.acquire() # 每执行一次减少一个信号量 print("执行任务.....执行完成") sem.release() # 执行完成后增加信号量 for i in range(3): # 有3个人想要执行任务 p = Process(target=rnewu) p.start() p.join()
joblib.Parallel并行
joblib.Parallel 让Python代码更加高效地利用多核处理器和并行计算资源。joblib中默认是采用loky实现并行运行,他会自然地将任务分配到多个CPU上去运行,同时更加稳定。
from joblib import Parallel, delayed # 定义一个简单的函数 def my_function(x): return x ** 2 # 并行执行函数 results = Parallel(n_jobs=-1)(delayed(my_function)(i) for i in range(10)) print(results)
解释一下:
my_function 函数将平方输入的参数,并且我们希望并行地对一组输入进行计算。
Parallel(n_jobs=2) 指定两个CPU(默认是分配给不同的CPU),如果-1的话,就是默认所有CPU核心
delayed 函数用于延迟执行函数调用,确保在并行执行时参数传递正确。
控制并行执行
joblib.Parallel 还提供了一些参数来控制并行执行的方式。其中一些重要的参数包括:
n_jobs:指定并行执行的作业数量,设置为 -1 则使用所有可用的 CPU 核心。backend:指定并行化的后端引擎,例如multiprocessing或threading。prefer:指定首选的并行化引擎,例如processes或threads。
通过调整这些参数,你可以更好地控制并行执行的方式,以适应不同的计算需求和计算资源。
参考
【廖雪峰的Python教程】多进程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号