论文翻译:2019_TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain
论文代码:https://github.com/LXP-Never/TCNN(非官方复现)
引用格式:Pandey A, Wang D L. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 6875-6879.
摘要
本文提出了一种用于实时语音增强的全卷积神经网络(CNN)。所提出的CNN是一种基于编解码器的结构,在编码器和解码器之间插入的时间卷积模块(TCM)。我们称这种结构为时间卷积神经网络(TCNN)。TCNN中的编码器创建输入噪声帧的低维表示。TCM使用因果卷积层和膨胀卷积层来利用当前帧和前一帧的编码器输出。解码器使用TCM输出来重构增强帧。提出的模型以与说话人和噪声无关的方式进行训练。实验结果表明,该模型比目前最先进的实时卷积递归模型具有更好的增强效果,而且由于该模型是完全卷积的,其可训练参数比以前的模型少得多。
关键词:噪声无关和说话人无关的语音增强,时域,二维卷积神经网络,TCNN
1 引言
语音增强是指从语音信号中去除或衰减附加噪声的任务。它被用作鲁棒语音识别、电话会议和助听器等应用的预处理器。传统的语音增强方法包括谱减法[1]、维纳滤波[2]、基于统计模型的方法[3]和非负矩阵分解[4]。
在过去的几年中,基于深度学习的有监督语音增强方法已经成为语音增强的主流。通常,在监督方法中,给定的语音信号被转换为时频(T-F)表示,并由T-F表示构造一个目标信号作为训练目标。最常用的训练目标有理想比率掩模(IRM)[6]、相位敏感掩模(PSM)[7]和短时傅里叶变换(STFT)幅度。
尽管使用T-F表示是最流行的方法,但它也有一些缺点。首先,这些方法通常忽略纯净的相位信息,利用带噪声的相位进行时域信号重构。过去的一些研究表明,相位是提高语音质量的必要条件,特别是在低信噪比(SNR)[8]的情况下。其次,一些训练目标,如IRM,即使使用一个理想的目标,也不能导致完美的信号重建。最后,对于快速语音增强,T-F表示的计算是一个额外的开销。
上述因素以及深度神经网络强大的表达能力,使得研究者们开始在时域中探索深度神经网络的语音增强功能。在[9]中,作者证明了全卷积神经网络对时域语音增强的有效性。最近在[10]中,作者训练了一种在时域中使用频域丢失的模型来提高增强语音的感知质量。尽管[10]中的工作可以获得最先进的性能,但它并没有解决实时增强的问题。提出的模型在每个时间步使用128 ms帧,使得模型不适合实际应用。
由于TCNN序列建模[11]的成功实现,以及基于编码器-解码器的体系结构对时域语音增强的有效性[10,12],我们提出将两者结合,以获得一个实时增强系统。该模型具有基于编码器-解码器的体系结构,由因果卷积层组成。在编码器和解码器之间插入TCM,学习过去的长期依赖关系。在我们的工作中使用的TCM与[13]中使用的TCM类似,在[13]中,作者使用TCM在时域中以最先进的性能执行实时说话人分离。
本文的组织如下:我们首先在下一节中描述TCNN。第3节描述了提议的框架。实验细节、结果和比较在第4节给出。第五部分对全文进行总结。
2 时间卷积神经网络
TCNNs是为具有因果约束的序列建模任务而提出的通用卷积网络[11]。给定输入序列$x_0,...,x_t$和对应的输出序列$y_0,...,y_t$,序列建模网络通过训练网络关于估计序列和输出序列之间的一些损失函数来学习以估计输出序列$\hat{y}_0,...,\hat{y}_t$。对网络的因果约束意味着预测$\hat{y}_t$仅依赖于$x_0,...,x_t$,而不依赖于未来的输入$x_{t+1},...,x_T$。在时域频谱增强的情况下,输入序列是带噪帧序列,输出序列是纯净帧序列。
在施加因果约束的情况下,TCNNs由因果层和膨胀卷积层组成。确保了信息不会从未来泄露到过去。扩张卷积有助于增加感受野。接受范围越大,网络就越能回顾过去。图1说明了kernal size=2的扩张的因果卷积的例子。
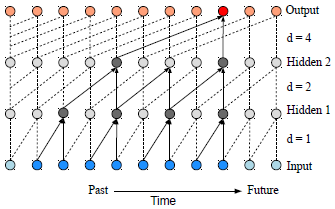
图1 滤波器数=2的扩张因果卷积的例子
此外,TCNN由残差块组成,因此可以使用残差学习[14]对深度网络进行充分的训练。图2显示了本工作中使用的残差块。在[13]中也使用了类似的残差块。残差块由3个卷积组成:输入1x1卷积、depthwise卷积和输出1x1卷积。输入卷积用于将输入通道的数量增加一倍。输出卷积被用来返回到原始的通道数,这使得输入和输出的加法兼容。depthwise卷积用于进一步减少参数的数量。在depthwise卷积中,通道的数量保持不变,每个输入通道只有一个滤波器用于输出计算[15]。在正常的卷积中,每个输出通道使用的滤波器数量与输入通道的数量相同。输入卷积和中间卷积之后是PReLU非线性[16]和批量归一化[17]。
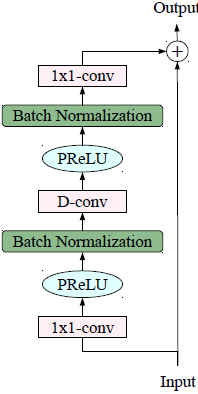
图2 残差和块使用在提出的框架
3 建议的框架
提出的TCNN有三个组成部分:编码器、解码器和TCM。编码器和解码器由二维因果卷积层组成,TCM由一维因果卷积层和扩张卷积层组成。该框架的框图如图3所示。

图3 提出的TCNN模型
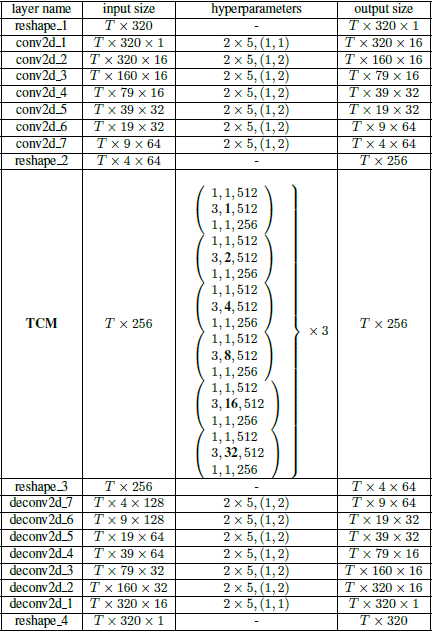
编码器将噪声帧序列作为输入,输入到编码器的大小为T×320×1,其中T为帧数,320为帧大小,1为输入通道数。编码器的第一层将通道数从1增加到64。第一层之后的输出维度为T×320×16,接下来的七层沿着帧维度以跨度为2的卷积 依次减少大小,最终编码器的输出是维度T×4×64,网络中没有一层沿时间维度修改大小,使得输出具有与输入相同的帧数。编码器中的每一层都经过批归一化和PReLU非线性处理。
编码器的输出被reshape为大小为T×256的一维信号。TCM对reshape后的输出进行操作,并产生相同大小的输出。TCM由三个 dilation blocks堆叠在一起。 dilation blocks是由6个膨胀率呈指数递增的残差块体叠加而成的。在 dilation blocks中,残差块的扩张率分别为$2^0$、$2^1$、$2^2$、$2^3$、$2^4$和$2^5$。
解码器是编码器的镜像,由一系列二维因果转置的卷积(反卷积)层组成。解码器在每一层之后的输出与编码器中相应对称层的输出级联。在训练时,我们向来自编码器的传入跳过连接添加0.3的dropout值。解码器中的每一层都经过批归一化和PRELU非线性处理。
具体网络参数见表1。对于编码器和解码器,超参数的格式为filterHeight filterWidth, (stride along time, stride along frame)。对于TCM,用小括号括起来的条目代表一个残差块,超参数的格式为filterSize、dilationRate、outputChannels。
表1 提出的模型体系结构。T表示时间帧的数量。括号中显示了剩余的块
4 实验
4.1 数据集
我们在WSJ0 SI-84数据集[18]上以一种说话人和噪声无关的方式评估了所提出的框架。WSJ0 SI-84数据集包含83名说话者(42名男性,41名女性)的7138个话语。我们为测试集选择了6个说话者。其余77位说话人被用来创建训练集。为了训练噪音,我们使用了来自音效库的10000个非语音声音(可在www.sound-ideas.com下载)。在-5 dB、-4 dB、-3 dB、-2 dB、-1 dB和0 dB的信噪比下生成训练话语。嘈杂的话语是通过以下方式产生的。首先,从训练者的话语中,随机选择一个信噪比和一个噪音类型。然后,在选定的信噪比下,将选定的话语与选定的噪声类型的随机片段混合。总共产生了32万个训练话语。训练噪音的持续时间约为125小时,而训练话语的持续时间约为500小时。
对于测试集,我们使用来自Auditec CD(http://www.auditec.com)的两种具有挑战性的噪音(babble和自助餐厅))。创建了两个测试集。第一个测试集使用了来自训练者的6个说话者(3个男性和3个女性)的话语。第二个测试集是由6个(3个男性和3个女性)不包括在训练集中的说话者的话语创建的。这两组测试用来评估受过训练和未受过训练的说话人的表现。请注意,所有的测试话语都被排除在训练集之外。
4.2 基线
对于基线,我们训练了两个模型。首先,我们训练一个基于LSTM的实时因果系统。在我们的结果中,我们称这个模型为LSTM。从输入层到输出层,LSTM模型有161、1024、1024、1024、1024、161个单元。其次,我们训练[19]中最近提出的另一个实时因果系统。该系统是一个递归卷积体系结构,使用基于编码器-解码器的卷积网络和LSTM递归。在我们的结果中,我们称这个模型为CRN。请注意,这两个基线模型都是在频域中操作的。
4.3 实验设置
所有的声音都被重新采样到16khz。使用大小为20 ms、重叠为10 ms的矩形窗口提取帧。所有模型都使用均方误差损失(MSE)和8个话语的batch size进行训练。小话语是零填充,以匹配批量中最大话语的大小。Adam优化器[20]用于基于随机梯度下降(SGD)的优化。设置学习速率为一个小的常值,等于0.0002。
4.4 实验结果
我们比较了短期客观可懂度(STOI)[21]和语音质量知觉评价(PESQ)[22]得分的模型。首先,我们将TCNN与训练有素的演讲者的基线进行比较。结果见表2。与LSTM相比,STOI在信噪比和信噪比上均有6.1%的平均改善。PESQ在-5 dB时提高0.14,在-2 dB时提高0.17。同样,与CRN相比,STOI在信噪比和PESQ上都提高了4%,在-5 dB和-2 dB上分别提高了0.04和0.09。

接下来,我们在未经训练的演讲者身上比较这些模型。结果见表3。在性能改进中观察到类似的趋势,除了在这种情况下,TCNN在PESQ得分方面也显著优于CRN。这说明CRN模型对训练集中的说话人过拟合。

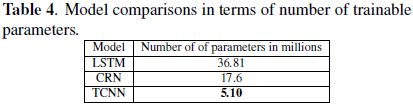
我们还比较了模型中可训练参数的数量。具体数字见表4。与基线模型相比,所提出的模型具有更少的参数,这使得它适合于真实世界应用程序的高效实现。
最后,值得一提的是,所提出的框架可以在输入处接受可变的帧大小。唯一需要更改的是根据所需的帧大小从编码器和解码器中添加或删除层。此外,该模型可以很容易地应用于其他基于回归的监督语音处理任务,如说话人分离、去混响和回声消除。
5 结论
在本研究中,我们提出了一种新颖的全卷积神经网络用于实时语音增强。提出的TCNN在频域显著优于现有的实时系统。此外,所提出的框架具有更少的可训练参数。此外,通过对网络的编码器和解码器进行简单的修改,系统很容易适应不同的帧大小。未来的研究包括探索TCNN模型用于其他语音处理任务,如去混响,回声消除和说话人分离。
6 致谢
这项研究部分得到了美国国家发展研究中心(NIDCD)的两项拨款(R01 DC012048和R01 DC015521)和俄亥俄州超级计算机中心的支持。
7 参考文献
[1] S. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE Transactions on Acoustics, Speech, and Signal processing, vol. 27, no. 2, pp. 113 120, 1979.
[2] P. Scalart et al., Speech enhancement based on a priori signal to noise estimation, in Proceedings of ICASSP, 1996, vol. 2, pp. 629 632.
[3] P. C. Loizou, Speech Enhancement: Theory and Practice, CRC Press, Boca Raton, FL, USA, 2nd edition, 2013.
[4] N. Mohammadiha, P. Smaragdis, and A. Leijon, Supervised and unsupervised speech enhancement using nonnegative matrix factorization, IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 10, pp. 2140 2151, 2013.
[5] D. Wang and J. Chen, Supervised speech separation based on deep learning: An overview, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, pp. 1702 1726, 2018.
[6] Y. Wang, A. Narayanan, and D. Wang, On training targets for supervised speech separation, IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 22, no. 12, pp. 1849 1858, 2014.
[7] H. Erdogan, J. R. Hershey, S.Watanabe, and J. Le Roux, Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks, in Proceedings of ICASSP, 2015, pp. 708 712.
[8] K. Paliwal, K. Wojcicki, and B. Shannon, The importance of phase in speech enhancement, Speech Communication, vol. 53, no. 4, pp. 465 494, 2011.
[9] S.-W. Fu, Y. Tsao, X. Lu, and H. Kawai, Raw waveform-based speech enhancement by fully convolutional networks, arXiv preprint arXiv:1703.02205, 2017.
[10] A. Pandey and D. Wang, A new framework for supervised speech enhancement in the time domain, in Proceedings of Interspeech, 2018, pp. 1136 1140.
[11] S. Bai, J. Z. Kolter, and V. Koltun, An empirical evaluation of generic convolutional and recurrent networks for sequence modeling, arXiv preprint arXiv:1803.01271, 2018.
[12] S. Pascual, A. Bonafonte, and J. Serr, SEGAN: Speech enhancement generative adversarial network, in Proceedings of Interspeech, 2017, pp. 3642 3646.
[13] Y. Luo and N. Mesgarani, TasNet: Surpassing ideal time-frequency masking for speech separation, arXiv preprint arXiv:1809.07454, 2018.
[14] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770 778.
[15] F. Chollet, Xception: Deep learning with depthwise separable convolutions, arXiv preprint, pp. 1610 02357, 2017.
[16] K. He, X. Zhang, S. Ren, and J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1026 1034.
[17] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in International Conference on Machine Learning, 2015, pp. 448 456.
[18] D. B. Paul and J. M. Baker, The design for the wall street journal-based CSR corpus, in Proceedings of the Workshop on Speech and Natural Language, 1992, pp. 357 362.
[19] K. Tan and D. Wang, A convolutional recurrent neural network for real-time speech enhancement, in Proceedings of Interspeech, 2018, pp. 3229 3233.
[20] D. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980, 2014.
[21] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time frequency weighted noisy speech, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125 2136, 2011.
[22] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ) - a new method for speech quality assessment of telephone networks and codecs, in Proceedings of ICASSP, 2001, pp. 749 752.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号