论文翻译:2021_MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
论文地址:MetricGAN+:用于语音增强的 MetricGAN 的改进版本
论文代码:https://github.com/JasonSWFu/MetricGAN
引用格式:Fu S W, Yu C, Hsieh T A, et al. MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement[J]. arXiv preprint arXiv:2104.03538, 2021.
摘要
用于训练语音增强模型的代价函数与人类的听觉感知之间的差异往往使增强后的语音质量不能令人满意。因此,考虑人的感知的客观评价指标可以作为缩小差距的桥梁。我们之前提出的MetricGAN旨在通过将指标与鉴别器相连接来优化目标指标。因为在训练过程中只需要目标评估函数的分数,所以度量甚至可以是不可微的。在这项研究中,我们提出了一个MetricGAN+,其中提出了三种结合语音处理领域知识的训练技术。在Voicebank-Demand数据集上的实验结果表明,与之前的MetricGAN相比,MetricGAN+可以将PESQ分数提高0.3,并获得最先进的结果(PESQ分数=3.15)。
关键词:语音增强、语音质量优化、黑盒评分优化、MetricGAN
1 引言
语音增强(SE)模型有许多不同的应用和目标。例如,在人与人之间的交流中,我们关心语音质量或清晰度(例如,在具有严重背景噪声的电话通话中,清晰度可能比质量更重要)。另一方面,在人机通信中,SE的目标是提高语音识别性能(例如,降低自动语音识别(ASR)系统在噪声条件下的误词率(WER))。因此,训练特定于任务的SE模型可以为其目标应用程序获得更好的性能。
要部署特定于任务的SE模型,最直观的方法是采用与最终目标相关的损失函数。虽然基于信号电平的差异(例如,𝐿1或𝐿2损耗)直接应用测量方法是直接的,但一些研究表明它与语音质量[1-3]、可懂度[4]和语音误码率[5,6]没有很高的相关性。
另一种选择是直接优化语音质量或清晰度。这通常是非常具有挑战性的,通常客观的评估指标被用作替代指标。在人类感知相关的客观度量中,语音质量的感知评价(PESQ)[7]和短时客观可懂度(STOI)[8]分别是用于评价语音质量和清晰度的两个常用函数。这两个度量的设计考虑了人的听觉感知,并且与干净和退化语音信号之间的简单𝐿1或𝐿2距离相比,与主观听力测试显示出更高的相关性[1,4]。
根据是否必须知道评价指标的细节,当前优化这些客观得分的技术可以分为两类:1)白盒:这些方法[4,9-12]用手工制作的、可区分的评价指标来近似复杂的评价指标。但是,必须知道指标的详细信息,并且只能将其用于目标指标。(2)黑盒:这些方法[3,13,14]主要将度量作为奖励,并应用基于强化学习的技术来提高分数。然而,培训通常效率低下,性能提高有限。
MetricGAN[15]属于黑盒类别,与传统的𝐿1丢失相比,它可以获得更好的训练效率和适度的性能改善(平均PESQ分数增加0.1%以上)。虽然MetricGAN可以很容易地用于优化不同的评估指标(例如,PESQ、STOI或WER),但我们主要以PESQ分数优化为例。其他分机可在[16-18]找到。
在本研究中,为了进一步提升MetricGAN框架的性能,揭示影响性能的重要因素,我们提出了MetricGAN+。MetricGAN+背后的基本思想没有改变,改进来自于包括三种结合了语音处理领域知识的训练技术。对鉴别器(D)提出了两种改进,对生成器(G)提出了一种改进:
对于鉴别器:
1)、包含噪声语音用于鉴别器训练:除了增强和干净的语音之外,还使用噪声语音来最小化鉴别器和目标客观度量之间的距离。
2)、增加来自重放缓冲器的样本大小:将从前一个历元产生的语音重复用于训练D。这可以防止D灾难性地遗忘[19]。
对于生成器:
1)、掩码估计的可学习Sigmoid函数:传统的Sigmoid函数对于掩码估计并不是最优的,因为它对于所有频段都是相同的,并且具有最大值1。按频率学习的Sigmoid函数更灵活,并且改善了SE的性能。
为了提高重复性,SpeechBrain工具包中提供了MetricGAN+
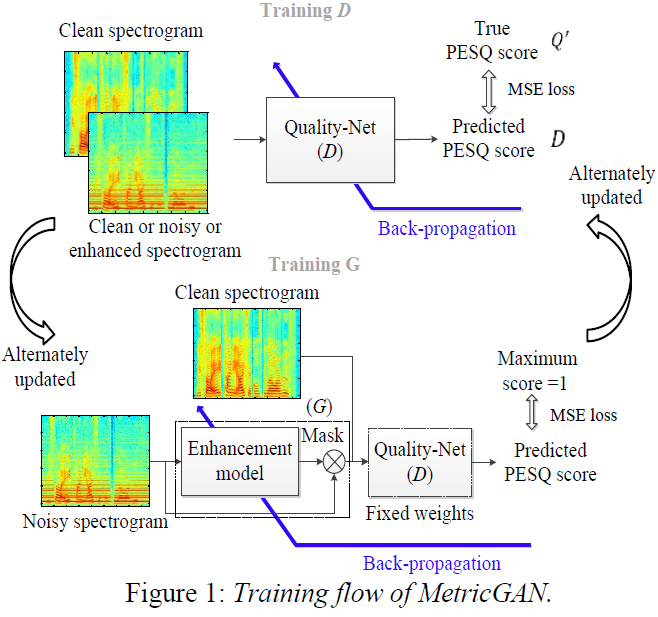
2 MetricGAN介绍
MetricGAN的主要思想是用神经网络(例如,Quality-Net[20])模拟目标评估函数(例如,PESQ函数)的行为。代理估计函数从原始分数中学习,将目标评价函数视为黑盒。一旦训练了代理评估,它就可以用作语音增强模型的损失函数。不幸的是,静态代理很容易被对抗性的例子愚弄[22](估计质量分数上升,但真实分数下降[21])。为了缓解这个问题,我们最近提出了一个学习框架,其中代理损失和增强模型交替更新[15]。这种方法被称为MetricGAN,因为它的目标是优化黑盒度量得分,其训练流程类似于生成对抗网络(GANS)。下面,我们简要介绍一下MetricGAN的培训情况。
设$Q'(I)$是表示归一化在0和1之间的目标评估度量的函数,其中$I$表示度量的输入。例如,对于PESQ和STOI,$I$表示我们想要评估的一对增强语音$G(x)$(或带噪语音$x$)及其对应的干净语音$y$。为了确保鉴别器网络(D)的行为类似于$D'$,$D$的目标函数是
$$公式1:\begin{aligned}
L_{\mathrm{D}(\text { MetricGAN })}=& \mathbb{E}_{x, y}\left[\left(D(y, y)-Q^{\prime}(y, y)\right)^{2}+\right.\\
&\left.\left(D(G(x), y)-Q^{\prime}(G(x), y)\right)^{2}\right]
\end{aligned}$$
这两个术语分别用于减少$D(.)$和$D'(.)$之间的差异,分别用于纯净语音和增强语音。注意,$D'(y,y)= 1$和$0 \leq Q'(G(x),y) \leq 1$。
生成器网络(G)的训练完全依赖于对抗性损失
$$公式2:L_{\mathrm{G}(\text { MetricGAN })}=\mathbb{E}_{x}\left[(D(G(x), y)-s)^{2}\right]$$
其中$s$表示期望分配的分数。例如,要生成干净的语音,只需将$s$赋值为1。整体的训练流程如图1所示。
3 从MetricGAN到MetricGAN+
为了提高MetricGAN框架的性能,提出了一些先进的学习技术。在调查过程中,我们还研究了对结果或训练效率有显著影响的因素。MetricGAN+的改进主要来自以下三个方面的修改。
3.1 学习噪声语音的度量学分数
Kawanaka et al.[16]建议在训练鉴别器时包含有噪音的语音。事实证明,这稳定了学习过程。我们对MetricGAN+也采用相同的策略。因此,将鉴别器网络的损失函数修改如下:
$$公式3:\begin{array}{r}L_{\mathrm{D}(\text { MetricGAN+ })}=\mathbb{E}_{x, y}\left[\left(D(y, y)-Q^{\prime}(y, y)\right)^{2}+\right. \left(D(G(x), y)-Q^{\prime}(G(x), y)\right)^{2}+ \left.\left(D(x, y)-Q^{\prime}(x, y)\right)^{2}\right]\end{array}$$
其中,第三项用于最小化$D(·)$和$D'(`)$对于带噪语音。
3.2 经验重放缓冲区(Replay Buffer)的样本
正如在深度Q-network[23]中一样,我们发现重用从前一个epoch产生的数据来训练鉴别器带来了巨大的性能改进。直观地,在没有经验重放的情况下,鉴别器可能会忘记目标$Q'$的函数在先前生成的语音中的行为,从而使得𝐷(.)与𝑄‘(.)不太相似。为了说明重放缓冲区的工作原理,我们在算法1中介绍了训练过程。在MetricGAN+中,我们将history_portion从0.1(在MetricGAN中使用)增加到0.2。

3.3 掩模估计的可学习Sigmoid函数
大多数基于掩码的语音增强方法[24]将S型激活应用于输出层,以将掩码限制在0和1之间。然而,由于相位差异,干净$|Y(t,f)|$和噪声($|N(t,f)|$)幅度谱的总和与噪声($|X(t,f)|$)的幅度谱[25]不完全匹配:
$$公式4:|X(t, f)| \neq|Y(t, f)|+|N(t, f)|$$
因此,不能保证理想的幅值掩码$|Y(t,f)|/|X(t,f)|$小于1。因此,我们在(5)中将刻度变量$\beta $设置为等于1.2.
此外,用于压缩输入值的标准Sigmoid函数对于语音处理可能不是最佳的。例如,由于噪声和语音在高、低频段的模式是不同的,不同的频段可以有自己的压缩函数来进行掩码估计。为了赋予我们的模型这种灵活性,我们设计了一个可学习的Sigmoid函数,如下所示:
其中$\alpha $是从训练数据中学习的。不同的频段有自己的$\alpha $。
$\alpha $控制压缩函数的形状。如图2所示,大$\alpha $(红色)的值类似于硬阈值,并且大多数输出值不是0就是1(更不平滑、更饱和[26],类似于二进制掩码)。另一方面,小$\alpha $(绿色)的行为更像线性函数,可以观察到它与绿色虚线有较大的重叠(虚线和Sigmoid函数之间的重叠可以大致表示线性的范围)

图2:带有不同$\alpha $的Sigmoid函数
4 实验
4.1 数据集
为了将提出的MetricGAN+与其他现有方法进行比较,我们使用公开可用的Voicebank-Demand数据集[27]。训练集(11572个话语)由28个说话人组成,具有4个信噪比(15、10、5和0dB)。测试集(824个话语)由2个说话人组成,具有4个SNR(17.5、12.5、7.5和2.5dB)。有关数据的详细信息可以在原文中找到。除了PESQ评分外,我们还使用其他三个度量对性能进行评估:CSIG预测信号失真的平均意见评分(MOS),CBAK预测背景噪声干扰的MOS,COVL预测整体语音质量的MOS。这三个指标的范围都在1到5之间。对于使用的所有指标,值越高表示性能越好。
4.2 模型搭建
本实验中使用的生成器是具有两个双向LSTM层的BLSTM[28],每个层有200个神经元。LSTM之后是两个完全连接的层,每个层分别具有用于掩码估计的300个LeakyReLU节点和257个(可学习的)Sigmoid节点。当该掩码与输入的噪声幅度谱图相乘时,噪声分量应该被去除。此外,如文献[3]中所述,为了防止音乐噪音,在T-F掩模处理之前,将地板(flooring)应用于估计的掩模。这里,我们将T-F掩码的下限阈值设置为0.05。这里的鉴别器是具有四个二维(2-D)卷积层的CNN,具有15个滤波器和(5,5)核大小。为了处理可变长度的输入(不同的语音发声具有不同的长度),添加了2-D全局平均池化层(global average pooling layer),使得特征可以固定在15维(15是前一层中的特征映射的数量)。随后添加3个完全连通的层,每层分别有50个和10个LeakyReLU神经元,以及1个线性节点。此外,为了使D为平滑函数(即,输入谱图中的任何小的修改都可以显著改变估计分数),通过使用谱归一化将鉴别器限制为1-Lipschitz连续[29]。在实验中,Number_of_Samples设置为100。
4.3 实验结果
我们首先展示在第3节中介绍的不同训练技术的效果。在表1中,每一行的结果是使用上一行的设置加上当前技术得出的。从表中可以看出,与进一步增加缓冲器中的样本大小相比,去除输入谱图的归一化,并将噪声语音包含到$D$训练中 会带来更大的改善。但是,表2显示,如果不保留重放缓冲区,PESQ得分仅达到2.82。当我们从缓冲区中随机抽取10%和20%的历史增强数据时,分数分别增加0.2和0.23。当history_portion=0.3时,我们没有观察到进一步的改进。这意味着如果没有缓冲器,鉴别器可能只关注当前样本的评估结果,而忽略其对先前生成的语音的正确性(灾难性遗忘[19])。由于$D$和$Q'$之间的差异,因此$D$的梯度可能不是$Q$的梯度的一个很好的近似。
表2 不同history_part的结果
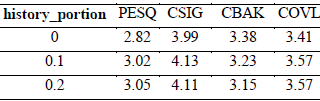
表1 MetricGAN+消融研究
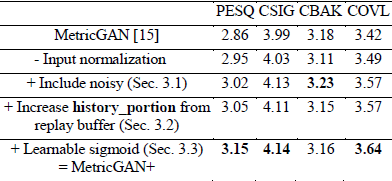
表1还显示,使用可学习的sigmoid可以进一步提高分数。我们试图让$\beta $也可学习,但性能没有进一步改善。学习到的$\alpha$值如图3所示。大多数$\alpha$值小于1(传统的S形函数的原始值),接近0.5。正如第3.3节所指出的,这意味着对于大多数频率bin,可学习的sigmoid的行为更像一个线性函数。这自然地导致了一个梯度反向传播,比发生在饱和区域的更有效。另一方面,对于高频频率bin,学习到的$\alpha$值远大于1,因此掩码的行为更像二进制掩码。我们推测这是因为训练数据中的噪声类型没有占据高频区域,或者是因为PESQ函数的特性。然而,还需要更多的实验来验证可能的原因。
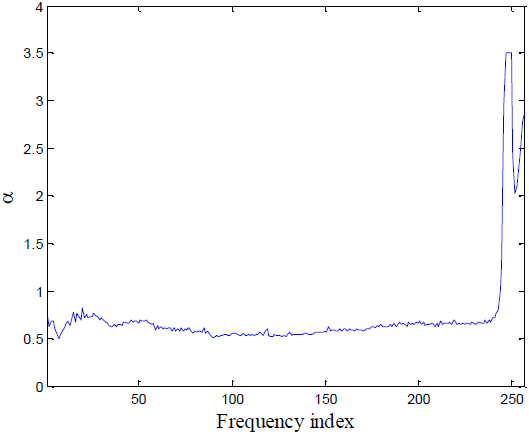
图3 在可学习的S形函数中学习\alpha的值
在图4中,我们展示了不同训练技术和相同BLSTM模型结构的MetricGAN的训练曲线,但训练时使用了均方误差损失。从这个图中,我们可以首先观察到,所有基于MetricGAN的方法都大大优于MSE损失。此外,引入噪声语音进行判别器训练和采用可学习的sigmoid不仅提高了最终性能,而且提高了训练效率。

图4 不同设置的学习曲线(G结构是固定的)。
表3将MetricGAN+与其他常用方法进行了比较。虽然我们的生成器只是一个传统的BLSTM,以幅度谱图作为输入,并具有适当的损失函数,但它的性能优于最近的模型(例如,注意机制[30,31])或相感知输入(例如,波形[32][33]或相位[34])。我们也注意到[35]报告的分数比我们的高,但是感知损失函数训练需要额外的数据集。与BLSTM (MSE)相比,我们的MetricGAN+将PESQ分数从2.71提高到3.15。我们还发现,我们的模型的CBAK得分低于其他先进水平;这可能是由于T-F mask的低阈值设置为0.05,如4.2节所述,因此仍然存在一些噪声。
表3 在VoiceBank-DEMAND数据集上比较MetricGAN+和其他方法

5 未来工作
MetricGAN+的代码可以在SpeechBrain工具包中获得,我们鼓励社区不断提高它的性能和培训效率。在下面,我们列出了一些值得探索的方向
1)、由于MetricGAN是一个黑盒框架,它可以被用来优化不同的度量。在[17]中,它被用于优化语音清晰度。据我们所知,它还没有被用于黑箱ASR模型(如谷歌ASR)的噪声条件下的WER最小化。
2)、可以进一步研究鉴别器的结构。现在它只是一个简单的CNN和全局平均池化。更先进的机制,如注意力[30,31]可能会取代全局池化。此外,如果目标$Q'$函数更复杂(如ASR模型的WER),则可能需要增加鉴别器的复杂度。
3)、使用重放缓冲区训练非常耗时,特别是当缓冲区中已经有大量的历史数据时。增量学习(Incremental learning)[40]可能是这个问题的一个很好的解决方案。
6 结论
在本研究中,我们提出了几种技术来提高MetricGAN框架的性能。我们发现,在鉴别器训练中引入噪声语音和应用可学习的s型函数是最有用的方法。我们的MetricGAN+在VoicBank-DEMAND数据集上实现了最先进的结果,与MetricGAN和BLSTM (MSE)相比,PESQ分数可以分别提高0.3和0.45。从实验结果来看,我们认为所提出的框架可以进一步改进并应用于不同的任务;因此,我们将代码公开。
7 参考文献
[1] C. K. Reddy, V. Gopal, and R. Cutler, "DNSMOS: A nonintrusive perceptual objective speech quality metric to evaluate noise suppressors," arXiv preprint arXiv:2010.15258, 2020.
[2] P. Manocha, A. Finkelstein, R. Zhang, N. J. Bryan, G. J. Mysore, and Z. Jin, "A differentiable perceptual audio metric learned from just noticeable differences," in Proc. Interspeech, 2020.
[3] Y. Koizumi, K. Niwa, Y. Hioka, K. Kobayashi, and Y. Haneda, "DNN-based source enhancement to increase objective sound quality assessment score," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, pp. 1780-1792, 2018.
[4] S.-W. Fu, T.-W. Wang, Y. Tsao, X. Lu, and H. Kawai, "End-toend waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks," IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 26, pp. 1570-1584, 2018.
[5] D. Bagchi, P. Plantinga, A. Stiff, and E. Fosler-Lussier, "Spectral feature mapping with mimic loss for robust speech recognition," in Proc. ICASSP, 2018, pp. 5609-5613.
[6] L. Chai, J. Du, and C.-H. Lee, "Acoustics-guided evaluation (AGE): a new measure for estimating performance of speech enhancement algorithms for robust ASR," arXiv preprint arXiv:1811.11517, 2018.
[7] A. Rix, J. Beerends, M. Hollier, and A. Hekstra, "Perceptual evaluation of speech quality (PESQ), an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs," ITU-T Recommendation P. 862, 2001.
[8] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, "A short-time objective intelligibility measure for time-frequency weighted noisy speech," in Proc. ICASSP, 2010, pp. 4214-4217. [9] Y. Zhao, B. Xu, R. Giri, and T. Zhang, "Perceptually guided speech enhancement using deep neural networks," in Proc. ICASSP, 2018, pp. 5074-5078.
[10] J. M. Martin-Donas, A. M. Gomez, J. A. Gonzalez, and A. M. Peinado, "A deep learning loss function based on the perceptual evaluation of the speech quality," IEEE Signal Processing Letters, 2018.
[11] J. Kim, M. El-Kharmy, and J. Lee, "End-to-end multi-task denoising for joint SDR and PESQ optimization," arXiv preprint arXiv:1901.09146, 2019.
[12] M. Kolbæ k, Z.-H. Tan, and J. Jensen, "Monaural speech enhancement using deep neural networks by maximizing a shorttime objective intelligibility measure," in Proc. ICASSP, 2018.
[13] Y. Koizumi, K. Niwa, Y. Hioka, K. Kobayashi, and Y. Haneda, "DNN-based source enhancement self-optimized by reinforcement learning using sound quality measurements," in Proc. ICASSP, 2017, pp. 81-85.
[14] H. Zhang, X. Zhang, and G. Gao, "Training supervised speech separation system to improve STOI and PESQ directly," in Proc. ICASSP, 2018, pp. 5374-5378.
[15] S.-W. Fu, C.-F. Liao, Y. Tsao, and S.-D. Lin, "MetricGAN: Generative adversarial networks based black-box metric scores optimization for speech enhancement," in Proc. ICML, 2019.
[16] M. Kawanaka, Y. Koizumi, R. Miyazaki, and K. Yatabe, "Stable training of DNN for speech enhancement based on perceptuallymotivated black-box cost function," in Proc. ICASSP, 2020.
[17] H. Li, S.-W. Fu, Y. Tsao, and J. Yamagishi, "iMetricGAN: Intelligibility enhancement for speech-in-noise using generative adversarial network-based metric learning," in Proc. Interspeech, 2020.
[18] S.-W. Fu, C.-F. Liao, T.-A. Hsieh, K.-H. Hung, S.-S. Wang, C. Yu, et al., "Boosting objective scores of speech enhancement model through MetricGAN post-processing," in Proc. APSIPA, 2020.
[19] I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio, "An empirical investigation of catastrophic forgetting in gradient-based neural networks," in Proc. ICLR, 2014.
[20] S.-W. Fu, Y. Tsao, H.-T. Hwang, and H.-M. Wang, "Quality-Net: An end-to-end non-intrusive speech quality assessment model based on blstm," in Proc. Interspeech, 2018.
[21] S.-W. Fu, C.-F. Liao, and Y. Tsao, "Learning with learned loss function: Speech enhancement with quality-net to improve perceptual evaluation of speech quality," IEEE Signal Processing Letters, 2019.
[22] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, et al., "Intriguing properties of neural networks," arXiv preprint arXiv:1312.6199, 2013.
[23] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, et al., "Human-level control through deep reinforcement learning," Nature, vol. 518, pp. 529-533, 2015.
[24] D. Wang and J. Chen, "Supervised speech separation based on deep learning: An overview," IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
[25] H. ErdoGAN, J. R. Hershey, S. Watanabe, and J. Le Roux, "Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks," in Proc. ICASSP, 2015, pp. 708-712.
[26] Z. Cao, M. Long, J. Wang, and P. S. Yu, "Hashnet: Deep learning to hash by continuation," in Proc. ICCV, 2017, pp. 5608-5617.
[27] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, "Investigating RNN-based speech enhancement methods for noise-robust Text-to-Speech," in SSW, 2016, pp. 146-152.
[28] F. Weninger, H. ErdoGAN, S. Watanabe, E. Vincent, J. Le Roux, J. R. Hershey, et al., "Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR," in Proc. LVA/ICA, 2015, pp. 91-99.
[29] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, "Spectral normalization for generative adversarial networks," arXiv preprint arXiv:1802.05957, 2018.
[30] Y. Koizumi, K. Yaiabe, M. Delcroix, Y. Maxuxama, and D. Takeuchi, "Speech enhancement using self-adaptation and multihead self-attention," in Proc. ICASSP 2020, pp. 181-185.
[31] J. Kim, M. El-Khamy, and J. Lee, "Transformer with Gaussian weighted self-attention for speech enhancement," in Proc. ICASSP, 2020.
[32] J. Su, Z. Jin, and A. Finkelstein, "HiFi-GAN: High-fidelity denoising and dereverberation based on speech deep features in adversarial networks," in Proc. Interspeech, 2020.
[33] A. Defossez, G. Synnaeve, and Y. Adi, "Real time speech enhancement in the waveform domain," in Proc. Interspeech, 2020.
[34] D. Yin, C. Luo, Z. Xiong, and W. Zeng, "Phasen: A phase-andharmonics- aware speech enhancement network," in Proc. AAAI 2020, pp. 9458-9465.
[35] S. Kataria, J. Villalba, and N. Dehak, "Perceptual loss based speech denoising with an ensemble of audio pattern recognition and self-supervised models," in Proc. ICASSP, 2021.
[36] S. Pascual, A. Bonafonte, and J. Serra, "SEGAN: Speech enhancement generative adversarial network," in Proc. Interspeech, 2017.
[37] M. H. Soni, N. Shah, and H. A. Patil, "Time-frequency maskingbased speech enhancement using generative adversarial network," in Proc. ICASSP, 2018, pp. 5039-5043.
[38] D. Baby and S. Verhulst, "SerGAN: Speech enhancement using relativistic generative adversarial networks with gradient penalty," in Proc. ICASSP, 2019, pp. 106-110.
[39] Q. Zhang, A. Nicolson, M. Wang, K. K. Paliwal, and C. Wang, "Deepmmse: A deep learning approach to mmse-based noise power spectral density estimation," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1404- 1415, 2020.
[40] C.-C. Lee, Y.-C. Lin, H.-T. Lin, H.-M. Wang, and Y. Tsao, "SERIL: Noise adaptive speech enhancement using regularization-based incremental learning," in Proc. Interspeech, 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号