论文翻译:2021_PercepNet:A Perceptually Motivated Approach for Low-complexity, Real-time Enhancement of Fullband Speech
论文代码:https://github.com/search?q=PercepNet
引用格式:Valin J M, Isik U, Phansalkar N, et al. A Perceptually Motivated Approach for Low-complexity, Real-time Enhancement of Fullband Speech[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 2482-2486.
摘要
近几年来,基于深度学习的语音增强方法大大超过了传统的基于谱减法和谱估计的语音增强方法。许多新技术直接在频域操作,导致了很高的计算复杂度。在这项工作中,我们提出了PercepNet,这是一种高效的方法,它依赖于人类对语音的感知,通过关注语音的谱包络和语音的周期性,我们展示了高质量的实时增强全频带(48 KHz)语音的方法,使用了不到5%的CPU核。
关键词:语音增强,基音滤波,后置滤波
1 引用
在过去的几年里,基于深度学习的语音增强方法大大超过了传统的基于谱减法和谱估计的方法[1]和[2]。其中许多技术直接使用短时傅立叶变换(STFT),估计幅度[3,4,5]或者理想比值掩码(IRM)[6,7]。这通常需要大量的神经元和权重,导致很高的复杂性,这也部分解释了为什么许多这些方法被限制在8或16 kHz。STFT的使用还带来了窗长的权衡,长窗口会引起音乐噪声和类似混响的效果,而短窗口不能提供足够的频率分辨率来消除音调谐波之间的噪声。这些问题可以通过复数比值掩码(cRM)[8]或时域处理[9,10,11]来缓解,但代价是进一步增加复杂度。
我们提出了PercepNet,这是一种非常依赖于人类对语音信号的感知并改进了RNNoise的有效方法[12]。更确切地说,我们关注关键频段的音频感知(第2节),音调和噪音的感知(第3节),并使用了新的非因果梳状滤波器。我们使用的深度神经网络(DNN)模型是使用感知标准进行训练的(第4节)。我们提出了一种新的包络后置滤波器(第5节),进一步改善了增强后的信号。
PercepNet算法在10ms的帧上运行,具有40ms的look ahead,仅使用x86 CPU内核的4.1%就可以实时增强48 kHz的语音。我们发现它的性能大大超过了RNNoise(第6节)。
2 信号模型
设$x(n)$是纯净语音信号,在嘈杂的房间中由免提麦克风捕获的信号由下式给出
$$公式1:y(n)=x(n)*h(n)+\eta (n)$$
其中$\eta (n)$是来自房间的噪声,$h(n)$是从讲话者到麦克风的脉冲响应,$*$表示卷积。 此外,纯净语音可以表示为$x (n) = p (n)+ \mu (n)$,其中$p(n)$是局部周期分量,而$\mu(n)$是随机分量(这里考虑诸如停顿之类的瞬变作为随机分量的一部分)。 在这项工作中,我们尝试计算增强信号$\hat{x}(n)=\hat{p}(n)+\hat{\mu}(n)$,使它在感知上尽可能接近纯净语音$x(n)$。 从环境噪声$\eta (n)$中分离随机分量$\mu(n)$是一个非常困难的问题。 幸运的是,我们只需要$\hat{\mu}(n)$听起来像$\mu(n)$,这可以通过过滤混合$\mu(n)*h(n)+\eta (n)$以具有与$\mu(n)$相同的频谱包络来实现。 由于$p(n)$是周期性的,并且假设噪声不具有强周期性,因此$p(n)$应该更容易估计。 同样,我们主要需要$\hat{p}(n)$具有与$p(n)$相同的频谱包络和相同的周期。
我们试图构造一个增强信号,它具有与纯净信号相同的1)频谱包络,2)频率相关的周期随机比(periodic-to-stochastic ratio)。对于这两个属性,我们使用与人类感知相匹配的分辨率。
我们使用具有20 ms窗口和50%重叠的短时傅立叶变换(STFT)。我们使用满足Princen-Bradley完全重构准则的Vorbis窗函数[13]进行分析(analysis)和合成(synthesis),如图1所示。算法概述如图2所示 。

图1:当前合成(synthesized)窗以红色显示。我们使用三个前瞻(look-ahead)窗口(以虚线显示),以便在t = 40ms之前的采样用于计算t = 0之前的音频输出
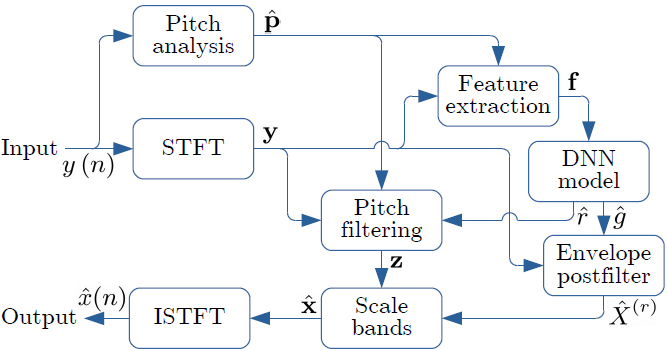
图2:PercepNet算法概述
2.1 Bands
绝大多数噪声信号具有较宽的带宽和平滑的频谱。类似地,语音的周期分量和随机分量都具有平滑的谱包络。这使得我们可以使用34个频段来表示它们的包络,范围从0到20 kHz,间隔根据人类听力等效矩形带宽(ERB)[15]。为了避免仅使用频率bin,我们将最小频带宽度设置为100Hz。
为了使增强信号的每个频带在感知上接近纯净语音,它们的总能量和周期都应该是相同的。在本文中,我们将信号$x(n)$复值谱用$x_b(l)$表示($l$表示帧索引,$b$表示频带索引)。我们也将该频带的L2 norm表示为$X_b(l)$。
2.2 Gains
根据频带$b$中noisy的语音信号的大小,我们计算理想的比率掩码(ideal ratio mask, IRM),将增益$g_b(l)$应用于$y_b$,使其具有与$x_b(l)$相同的能量:
$$公式2:g_b(l)=\frac{X_b(l)}{Y_b(l)}$$
在语音仅具有随机分量的情况下,将增益$g_b(l)$应用于频带$b$中的幅度谱将产生几乎无法与纯净语音信号区分的增强信号。另一方面,当语音是完全周期性的时,应用增益$g_b(l)$会产生一个增强的信号,听起来比纯净语音更粗糙;即使能量是相同的,增强后的信号也没有纯净语音那么刺耳。在这种情况下,由于音调对噪声的影响相对较小,因此噪声特别明显[16]。在这种情况下,我们使用下一节中描述的梳状滤波器来消除基音谐波之间的噪声,并使信号更具周期性。
3 Pitch滤波
为了重建纯净语音的谐波特性,我们使用了基于基音频率的梳状滤波。梳状滤波器可以获得比STFT(使用20毫秒帧的50 Hz)更好的频率分辨率。我们使用基于相关性的方法结合动态规划搜索来估计基音周期[17]。
3.1 滤波器
对于周期为$T$的浊音(voiced speech)信号,简单梳理过滤
$$公式3:C^{(0)}(z)=\frac{1+z^{-T}}{2}$$
在谐波之间以规则的间隔引入零,并将信号的噪声部分衰减约3dB。这在[12]中提供了一个很小但明显的质量改进。在这项工作中,我们将梳状过滤扩展到多个周期,包括使用以下过滤的非因果抽头:
$$公式4:C_{M}(z)=\sum_{k=-M}^{M} w_{k} z^{-k T}$$
其中$M$是中心抽头每侧的周期数,$w_k$是满足$\sum_kw_k=1$的窗函数。使用$C_M(z)$,信号的噪声部分由$\sigma_w^2=\sum_kw_k^2$衰减。虽然矩形窗口会使$\sigma_w^2$变得更小,但我们使用的是Hann窗口,它使剩余的噪声在谐波之间变得更低。由于音调掩蔽(tone masking)的行为[15],这导致了较低的感知噪声。对于$M$=5,我们有$\sigma_w=9$dB,全部响应如图3所示。在实践中,由于最大look-ahead是有限的,我们将窗口$w_k$截断为允许的$kT$的值。
滤波发生在时域中,输出表示为$\hat{p}(n)$,因为它近似于来自纯净语音的“完美”周期分量$p(N)$。其短时傅里叶变换表示为$\hat{P}_b(l)$。
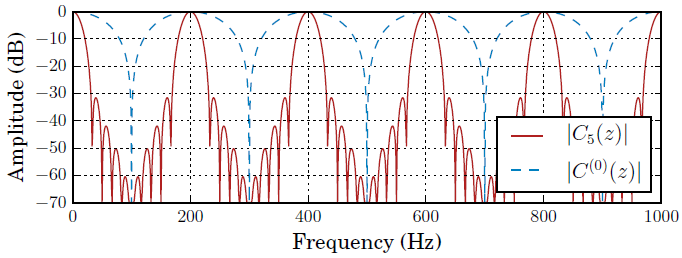
图3:提出的梳状滤波器(红色)与[12](蓝色)中使用的滤波器的频率响应为200 Hz
3.2 滤波强度(Strength)
梳状过滤量很重要:过滤不足会导致粗糙,而过滤过多则会产生机器人语音。文[12]中梳状过滤的强度由启发式控制。在这项工作中,我们取而代之的是让神经网络学习保持每个频带中周期能量与随机能量之比的强度。下面的公式描述了理想强度应该是多少。因为它们依赖于纯净语音的特性,所以它们只在训练时使用。
$$公式5:q_{x} \triangleq \frac{\Re\left[\mathbf{p}^{\mathrm{H}} \mathbf{x}\right]}{\|\mathbf{p}\| \cdot\|\mathbf{x}\|}$$
其中$·^H$表示Hermitian 转置,$R[·]$表示real分量。类似地,我们将$q_y$定义为噪声信号的基音相干性。由于ground truth $P$不可用,因此需要估计相干值。考虑到$\hat{P}$中的噪声被因子$\sigma _w^2$衰减,估计周期信号$\hat{P}$本身的基音相干性可近似为
$$公式6:q_{\hat{p}}=\frac{q_{y}}{\sqrt{\left(1-\sigma_{w}^{2}\right) q_{y}^{2}+\sigma_{w}^{2}}}$$
我们定义了基音过滤强$r\in[0,1]$,其中$r=0$不会导致发生滤波,$r=1$用$\hat{p}$替换信号。设$z=(1-r)y+r\hat{p}$是基音增强信号,我们希望$z$的基音相干性与纯净信号匹配:
$$公式7:q_{z}=\frac{\mathbf{p} \cdot((1-r) \mathbf{y}+r \hat{\mathbf{p}})}{\|\mathbf{p}\| \cdot\|(1-r) \mathbf{y}+r \hat{\mathbf{p}}\|}=q_{x}$$
求解(7)$r$的结果为
$$公式8:r=\frac{\alpha}{1+\alpha}$$
$$公式9:\alpha=\frac{\sqrt{b^{2}+a\left(q_{x}^{2}-q_{y}^{2}\right)}-b}{a}$$
其中,$a=q_{\hat{p}}^{2}-q_{x}^{2}$和$b=q_{\tilde{p}} q_{y}\left(1-q_{x}^{2}\right)$。
在非常嘈杂的条件下,周期估计$\hat{p}$可能比频带中的纯净语音具有更低的相干性$(q_\hat{p}<q_x)$。在这种情况下,我们设置$r=1$并计算增益衰减项,以确保增强语音的随机成分与纯净语音的水平相匹配(代价是使周期成分过于安静)
$$公式10:g^{(\mathrm{att})}=\sqrt{\frac{1+n_{0}-q_{x}^{2}}{1+n_{0}-q_{\hat{p}}^{2}}}$$
其中,$n0=0.03$(或15 dB)将最大衰减限制为噪声掩蔽音调阈值[18]。对于正常情况$(q_{\hat{p}}\geq q_x)$然后$g^{att}=1$。
4 DNN模型
该模型同时使用卷积层(1x5 层,然后是 1x3 层)和 GRU [19] 层,如图4所示。卷积层在时间上对齐,以便在未来使用多达 M 帧。 为了实现 40 毫秒的前瞻,包括 10 毫秒的重叠,我们使用$M = 3$。
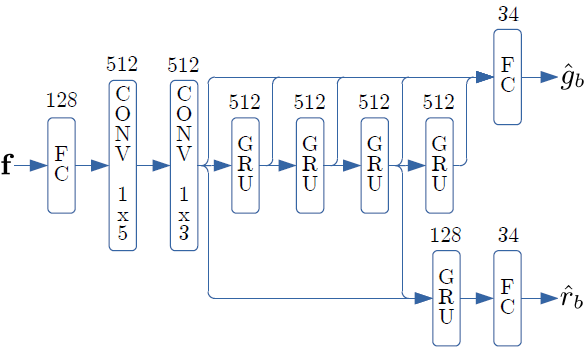
图4:从70维输入特征向量$f$计算34增益$\hat{g}_b$和34强度$\hat{r}_b$的DNN架构概述
每个层上的单元数在层类型的上面显示
模型使用的输入要素绑定到34个ERB波段。对于每个频带,我们使用两个特征:带look-ahead 的频带的幅度$Y_b(l+M)$和不带look-ahead的基音相干性$q_{t,b}(l)$(相干估计本身使用完全前瞻)。除了这68个与频带相关的特征之外,我们还使用基音周期$T(l)$,以及与前瞻的基音相关[20]的估计,用于总共70个输入特征。对于每个频带$b$,我们还具有2个输出:增益$\hat{g}_b(l)$近似$g_b^{att}(l)g_b(l)$和强度(strength)$\hat{r}_b(l)$近似$r_b(l)$。
模型的权重被强制设置为范围$\pm \frac{1}{2}$,并量化为8位整数。这减少了内存需求(和带宽),同时还利用向量化降低了推断的计算复杂度。
4.1 训练数据
我们在纯语音和噪声的合成混合物上训练模型,信噪比从-5 dB到45 dB,包括一些无噪声的例子。纯净语音数据包括来自不同公共和内部数据库的120小时48kHz的语音,包括200多人和20多种不同的语言。噪音数据包括80小时的各种类型的噪音,采样频率也是48kHz。
为了保证在混响条件下的鲁棒性,噪声信号与模拟和测量的房间脉冲响应进行卷积。受到[21]的启发,目标包括早期反射,因此只有晚期混响被衰减。
我们通过对语音和噪声应用不同的随机二阶极零滤波器来提高模型的泛化。我们还将相同的随机频谱倾斜应用于两个信号,以更好地推广不同的麦克风频率响应。为了实现带宽无关,我们使用了一个低通滤波器,其随机截止频率在3 kHz至20 kHz之间。这使得在窄带到全带音频上使用相同的模型成为可能。
4.2 损失函数
我们使用不同的损失函数的增益和pitch滤波强度。对于增益,我们认为信号的感知响度与其能量成正比,能量为$\frac{\gamma }{2}$次方,其中我们使用$\gamma =0.5$。因此,在计算指标之前,我们将增益提高到$\gamma $次方。除了平方误差,我们还使用四次幂来过分强调产生较大误差的损失例如,完全衰减语音)
$$公式11:\mathcal{L}_{g}=\sum_{b}\left(g_{b}^{\gamma}-\hat{g}_{b}^{\gamma}\right)^{2}+C_{4} \sum_{b}\left(g_{b}^{\gamma}-\hat{g}_{b}^{\gamma}\right)^{4}$$
其中我们使用$C_4=10$来平衡$L_2$和$L_4$项。
虽然很简单,(11)中的损失函数隐式地包含了[22]中提出的改进损失函数的许多特征,包括尺度不变性、信噪不变性、幂律压缩和非线性频率分辨率。
对于音高滤波强度,我们使用与$L_g$相同的原理,但评估增强语音的噪声成分的响度。由于强度为$r_b$的梳状滤波器将噪声衰减一个因子$(1-r_b)$,我们使用强度损失:
$$公式12:\mathcal{L}_{r}=\sum_{b}\left(\left(1-r_{b}\right)^{\gamma}-\left(1-\hat{r}_{b}\right)^{\gamma}\right)^{2}$$
由于增强对误差值$r_b$不太敏感,所以我们不使用四次幂项。
5 包络后置滤波
为了进一步增强语音,我们稍微偏离了DNN产生的增益$g_b$。这种偏差是受共振峰后滤子[23]的启发,[23]常用于CELP编解码器中。我们有意地去强调噪声波段比它们在纯净信号中稍微远一点,同时过度强调纯净波段以进行补偿。这是通过计算一个扭曲增益来实现的
$$公式13:\hat{g}_{b}^{(w)}=\hat{g}_{b} \sin \left(\frac{\pi}{2} \hat{g}_{b}\right)$$
这使得$\hat{g}_b$对于纯净频段基本上不受影响,而对非常嘈杂的频段进行平方(如维纳滤波器的增益)。 为了避免整体上过度衰减增强信号,我们还应用了全局增益补偿启发式计算,如下所示
$$公式14:G=\sqrt{\frac{(1+\beta) \frac{E_{0}}{E_{1}}}{1+\beta\left(\frac{E_{0}}{E_{1}}\right)^{2}}}$$
其中$E_0$是使用原始增益$\hat{g}_b$的增强信号的总能量,$E1$是使用扭曲增益$\hat{g}_b^{(w)}$时的总能量。 我们使用$\beta = 0.02$,这导致纯净频段的最大理论增益为 5.5 dB。 将帧的最终信号按$G$缩放会产生一个感知上更清晰的信号,它与纯净信号大致一样响亮。 后置滤波器后的band能量由下式给出($Y_b$是带噪语音的频带谱,$\hat{X}_{b}$是增强语音的频带谱,):
$$公式15:\hat{X}_{b}=G \hat{g}_{b}^{(w)} Y_{b}$$
当通过房间里的扬声器播放 增强的语音信号时,房间的脉冲响应会被加到信号中,以便它与来自房间的任何语音混合在一起。然而,当通过耳机听时,没有任何混响会使增强的信号声音过于干燥和不自然。这是通过执行能量的最小衰减来解决的,前提是永远不超过噪声语音的能量
$$公式16:\hat{X}_{b}^{(r)}(\ell)=\min \left(\max \left(\hat{X}_{b}(\ell), \delta \hat{X}_{b}^{(r)}(\ell-1)\right), \hat{Y}_{b}(\ell)\right)$$
其中,$\delta $被选择为等效于混响时间T60 = 100ms。
将频域增强语音转换回时域后,对输出应用高通滤波器。 该滤波器有助于消除一些剩余的低频噪声,其截止频率由说话者的估计音调决定 [20],以避免衰减基频。
6 实验和结果
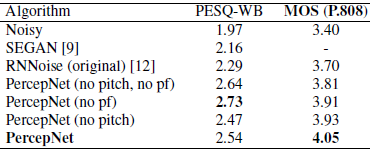
我们通过使用众包方法P.808[25]进行的两个平均意见得分(MOS)[24]测试来评估增强语音的质量。首先,我们使用[26]中提供的48kHz Noise VCTK测试集来比较PercepNet和原始RNNoise[12],同时还进行了消融研究。这项测试包括824个样本,每个样本由8名听众评分,结果是95%的置信区间为0.04。我们还提供了PESQ-WB[27]的结果作为与其他方法(如SEGAN[9])比较的参考。表1中的结果不仅显示了与RNNoise相比的基音改进,而且还显示了基音过滤和包络后置滤波器都有助于改善增强后的语音质量。此外,主观测试清楚地表明了PESQ-WB在评价包络后滤波时的局限性--尽管主观评价比后滤波有很大的提高,但PESQ-WB认为它是一种退化。请注意,MOS结果中异常高的离散值很可能是由于该测试中的全波段样本所致。
表1 P.808 MOS结果基于在48 kHz VCTK测试集上的内部测试
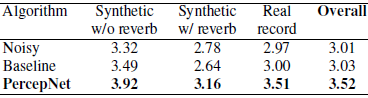
在第二次测试中,DNS挑战[28]组织者评估了用PercepNet处理的盲测试样本,并向我们提供了表2中的结果。该测试装置包括150个无混响合成样品,150个有混响合成样品和300个真实录音。每个样本由10名听众打分,所有算法的95%置信区间为0.02。由于PercepNet运行在48 kHz, 16 kHz的挑战测试数据在STFT域中被内部上采样(随后下采样),避免了任何额外的算法延迟。同样的模型参数用于挑战性的16 khz评估和我们自己的48 khz VCTK评估,展示了在不同带宽的语音上操作的能力。其质量也超过了基线的[29]算法。
表2:挑战官方P.808 MOS结果。基线模型由挑战组织者提供
算法的复杂度主要取决于神经网络,因此权值的个数。对于10ms和8M权重的帧大小,复杂度约为800 MMACS(每帧/秒每权重一次乘加)。通过对8位权值进行量化,使网络的高效运行成为可能。在默认的10毫秒的帧大小下,PercepNet需要5.2%的移动x86内核(1.8 GHz Intel i7-8565U CPU)来进行实时操作。以40毫秒的帧大小(4个内部帧,每个帧10毫秒,以提高缓存效率)进行评估,在相同的CPU核心和相同的输出上,复杂性降低到4.1%。尽管比DNS挑战所允许的最大复杂度低得多,但PercepNet在实时跟踪中排名第二。
定性地说,使用ERB波段而不是直接在频率bin上操作,使得算法不能在输出中产生音乐噪声(又称鸟伪信号)。类似地,用于分析的短窗口避免了在时域中的类混响涂抹。相反,主要值得注意的伪迹是由一些残留在音高谐波之间的噪声引起的一定数量的粗糙度,特别是对于大的汽车噪声。
7 结论
我们展示了一种有效的语音增强算法,该算法关注语音谱包络和周期性的主要感知特征,以实时生成低复杂度的高质量全频带语音。所提出的PercepNet模型使用带结构来表示频谱,以及基音滤波和额外的包络后滤波步骤。评估结果显示,宽带和全频带语音质量都有显著改善,并证明了基音滤波和后滤波的有效性。我们相信结果证明了使用感知相关参数建模语音的好处。
8 参考文献
[1] S. Boll. Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on acoustics, speech, and signal processing, 27(2):113 120, 1979.
[2] Y. Ephraim and D. Malah. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 33(2):443 445, 1985.
[3] D. Liu, P. Smaragdis, and M. Kim. Experiments on deep learning for speech denoising. In Proceedings of Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[4] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee. A regression approach to speech enhancement based on deep neural networks. IEEE Transactions on Audio, Speech and Language Processing, 23(1):7 19, 2015.
[5] K. Tan and D. Wang. A convolutional recurrent neural network for real-time speech enhancement. In Proceedings of INTERSPEECH, volume 2018, pages 3229 3233, 2018.
[6] A. Narayanan and D. Wang. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7092 7096, 2013.
[7] Y. Zhao, D. Wang, I. Merks, and T. Zhang. Dnn-based enhancement of noisy and reverberant speech. In Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6525 6529, 2016.
[8] D.S. Williamson, Y. Wang, and D. Wang. Complex ratio masking for monaural speech separation. IEEE/ACM transactions on audio, speech, and language processing, 24(3):483 492, 2016.
[9] S. Pascual, A. Bonafonte, and J. Serra. SEGAN: Speech enhancement generative adversarial network. arXiv:1703.09452, 2017.
[10] D. Rethage, J. Pons, and X. Serra. A wavenet for speech denoising. In Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5069 5073, 2018.
[11] C. Macartney and T. Weyde. Improved speech enhancement with the wave-u-net. arXiv:1811.11307, 2018.
[12] J.-M. Valin. A hybrid DSP/deep learning approach to real-time full-band speech enhancement. In Proceedings of IEEE Multimedia Signal Processing (MMSP) Workshop, 2018.
[13] C. Montgomery. Vorbis I specification, 2004.
[14] J. Princen and A. Bradley. Analysis/synthesis filter bank design based on time domain aliasing cancellation. IEEE Transactions on Acoustics, Speech, and Signal Processing, 34(5):1153 1161, 1986.
[15] B.C.J. Moore. An introduction to the psychology of hearing. Brill, 2012.
[16] H. Gockel, B.C.J. Moore, and R.D. Patterson. Asymmetry of masking between complex tones and noise: Partial loudness. The Journal of the Acoustical Society of America, 114(1):349 360, 2003.
[17] D. Talkin. A robust algorithm for pitch tracking (RAPT). In Speech Coding and Synthesis, chapter 14, pages 495 518. Elsevier Science, 1995.
[18] T. Painter and A. Spanias. Perceptual coding of digital audio. Proceedings of the IEEE, 88(4):451 515, 2000.
[19] K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio. On the properties of neural machine translation: Encoder-decoder approaches. In Proceedings of Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), 2014.
[20] K. Vos, K. V. Sorensen, S. S. Jensen, and J.-M. Valin. Voice coding with Opus. In Proceedings of the 135th AES Convention, 2013.
[21] Y. Zhao, D. Wang, B. Xu, and T. Zhang. Late reverberation suppression using recurrent neural networks with long short-term memory. In Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5434 5438. IEEE, 2018.
[22] H. Erdogan and T. Yoshioka. Investigations on data augmentation and loss functions for deep learning based speech-background separation. In Proceedings of INTERSPEECH, pages 3499 3503, 2018.
[23] J.-H. Chen and A. Gersho. Adaptive postfiltering for quality enhancement of coded speech. IEEE Transactions on Speech and Audio Processing, 3(1):59 71, 1995.
[24] ITU-T. Recommendation P.800: Methods for subjective determination of transmission quality, 1996.
[25] ITU-T. Recommendation P.808: Subjective evaluation of speech quality with a crowdsourcing approach, 2018.
[26] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi. Investigating rnn-based speech enhancement methods for noiserobust text-to-speech. In Proceedings of ISCA Speech Synthesis Workshop (SSW), pages 146 152, 2016.
[27] ITU-T. P.862.2: Wideband extension to recommendation P.862 for the assessment of wideband telephone networks and speech codecs (PESQ-WB). 2005.
[28] C.K.A. Reddy, V. Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun, P. Rana, S. Srinivasan, and J. Gehrke. The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results. arXiv preprint arXiv:2005.13981, 2020.
[29] Y. Xia, S. Braun, C.K.A. Reddy, H. Dubey, R. Cutler, and I. Tashev. Weighted speech distortion losses for neural-network-based real-time speech enhancement. arXiv:2001.10601, 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号