论文翻译:2020_RNNoise:A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement
网上已经有很多人翻译了,但我做这工作只是想让自己印象更深刻
博客地址:https://www.cnblogs.com/LXP-Never/p/15144882.html
论文代码:https://github.com/xiph/rnnoise
主页:https://jmvalin.ca/demo/rnnoise/
摘要
尽管噪声抑制已经是信号处理中一个成熟的领域,但仍然需要对它的估计算法和参数进行调优。文章演示了一种融合DSP和深度学习的方法来抑制噪声。该方法在保持尽可能低的计算复杂度的同时,实现了高质量的增强语音。使用具有四个循环神经网络来估计理想临界频带增益(ideal critical band gains),并用传统的pitch滤波器抑制谐波(pitch)之间的噪声。与传统的最小均方误差谱估计器相比,该方法可显着提高语音质量,同时将复杂度保持在足够低的水平。
关键词:噪声抑制,循环神经网络
1 引言
至少从 70年代开始,噪声抑制就成为了人们关注的话题。尽管质量有了显著提升,但算法结构基本保持不变。一些谱估计技术依赖于噪声谱估计器,而噪声谱估计器由语音活动检测器( VAD)或类似的算法驱动,如图1所示。 3个模块中的每个模块都需要准确的估计器,并且很难去调。尽管研究者们改进了这些估计器,但仍然很难设计它们,并且该过程需要大量的人工调优。这就是为什么最近深度学习技术上的进展对噪声抑制具有吸引力的原因。
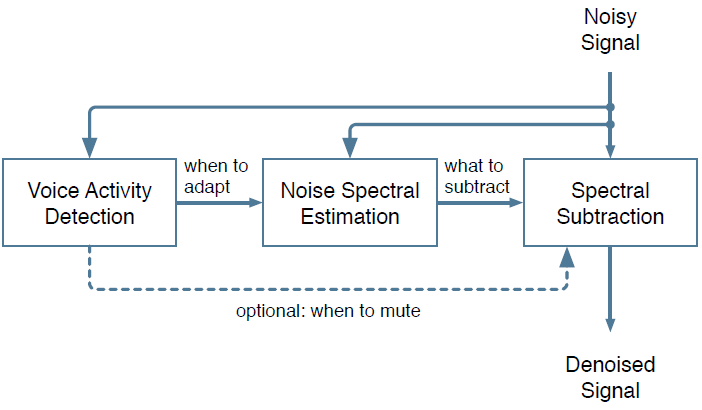
图1 大多数噪声抑制算法的高级结构
深度学习技术已被用于噪声抑制。许多方法都针对不需要低延迟的自动语音识别(ASR)应用。而且,在许多情况下,如果没有GPU,神经网络的庞大规模将使得实时变得困难。文章专注于低复杂度的实时应用(例如视频会议),并且专注于全频带(48 kHz)语音。为了实现这些目标,文章选择了一种混合的方法,该方法依靠信号处理技术并使用深度学习来替代传统上难以调优的估计器。该方法与所谓的端到端系统形成鲜明对比,在端到端系统中,大多数或所有信号处理操作 都被机器学习取代。这些端到端系统已经明确地展示了深度学习的能力,但是它们通常以显著地增加复杂度为代价。
我们提出的方法具有可接受的复杂性(第4节),并且它提供了比更传统的方法更好的质量(第5节)。我们在第6节总结了进一步改进该方法的方向。
2 信号模型
我们提出了一种混合的噪声抑制方法。我们的目标是在需要仔细调整的噪声抑制方面使用深度学习,而在不需要调整的部分使用传统的信号处理模块。
算法使用20ms的帧长,10ms的帧移。分析窗(analysis)和合成窗(synthesis)都使用Vorbis窗,它满足Princen-Bradley准则。该窗定义如下:
$$公式1:w(n)=\sin \left[\frac{\pi}{2} \sin ^{2}\left(\frac{\pi n}{N}\right)\right]$$
其中$N$是窗长
系统框图如图2所示。大部分的抑制是在低分辨率的谱包络上进行的,使用循环神经网络计算出频谱增益(maks,理想比值掩模IRM的平方根)。后面还使用梳状滤波器(pitch comb filter)来抑制谐波(pitch harmonics)之间的噪声以达到更加精细的抑制。
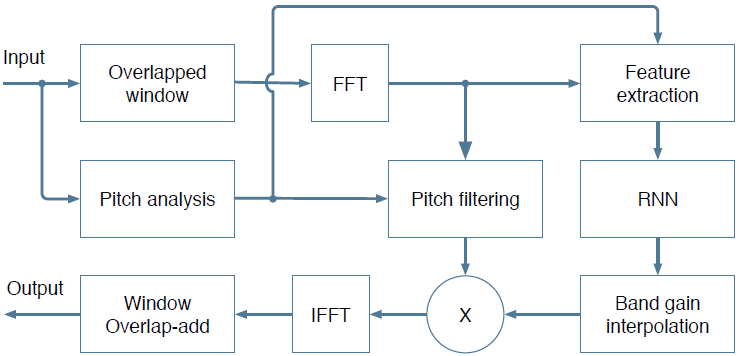
图2 框图
- Pitch analysis:基音追踪,追踪得到的基音周期一方面用于Feature extraction作为一个特征,另一方面利用其得到$x(n−pindex)$进而进行后面的基音滤波(pitch filtering)操作。
- feature extration:论文中求取42维特征的部分,将其作为输入送入RNN,RNN输出22位数据
- band gain interpolation:每一帧的增益为22维,因而为了将其作用于点数为481(帧长+1)的$X(k)$上,需要对其进行插值,
A 带(band)结构
在[5]的方法中,使用神经网络直接估计频率Bin的大小,共需要6144个隐藏单元和近1000万个权重来处理8 kHz的语音。使用20ms帧扩展到48kHz语音需要400个输出(0到20kHz)的网络,这显然会导致我们无法承受的更高复杂性。
为了避免产生大量输出——从而产生大量神经元——我们决定不直接处理样本或频谱。我们假设语音和噪声的频谱包络足够平坦,使用比频率bin更粗糙的分辨率——bark scale 频段,这是一种与人耳对声音感知相匹配的频率刻度。我们总共使用 22 个band,而不是我们必须考虑的 480 个(复数)频谱值。
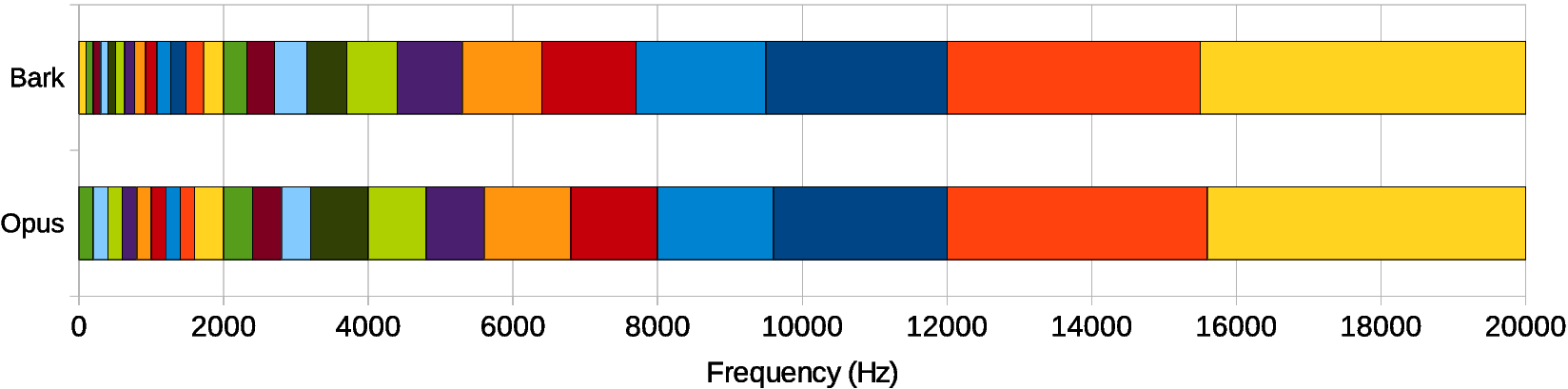
Opus 频带的布局与实际的 Bark scale,bark有25个频段,opus有21个频段。对于 RNNoise,我们使用与 Opus 相同的基本布局。
由于我们重叠了波段,因此 Opus 频段之间的边界成为重叠的 RNNoise 波段的中心。因此我们有22个三角滤波器
高频处频段更宽,因为耳朵在那里的频率分辨率较差。
低频处频带更窄,但不像bark scale给出的那么窄,因为那样我们将没有足够的数据来做出正确的估计
当然,我们不能仅从 22 频段的能量中重建音频。不过,我们可以做的是计算一个增益(22维)以应用于每个频段的信号。你可以将其视为使用 22 个频段均衡器并快速改变每个频段的 level 以衰减噪声,只让信号通过。(这里的增益和mask差不多概念)
使用频带增益操作有几个优点:
- 只用计算22个频段的增益,因此它的模型要简单得多。
- 它不可能产生所谓的音乐噪声伪影,即只有一个pitch可以通过,而它的邻居却被衰减了。这些伪影在噪声抑制中很常见,而且很烦人。对于足够宽的band,我们要么让整个band通过,要么全部剪掉。
- 增益总是在 0 和 1 之间,因此只需使用 sigmoid 激活函数(其输出也在 0 和 1 之间)来计算它们就可以确保我们永远不会做一些愚蠢的事情,比如添加一些原本就不存在的噪音
为了在训练期间更好地优化增益,损失函数是应用于gain的均方误差 (MSE) 的$\alpha$次幂。到目前为止,我们已经发现$\alpha=0.5$在感知上产生了最好的结果。使用$\alpha=0$将等同于最小化对数谱距离,这是有问题的,因为最优增益可能非常接近于零。
我们使用低分辨率频带(22个频带)会导致 没有一个足够好的分辨率来抑制pitch谐波之间的噪声。幸运的是,它并不是那么重要,甚至有一个简单的技巧去做它(见下面的音调过滤(pitch filtering)部分)。
此外,模型输出的是 22个[0,1]范围内的 理想的临界频带增益(ideal critical band gains)——应该也是基于Mask降噪方法的一种,其显著优点是限制在0和1之间。我们选择将频谱划分为与Opus编解码器[13]使用的Bark scale[12]相同的近似。也就是说,高频波段遵循Bark scale,但低频波段最少有4个频率bins。并且使用三角频带(滤波)而非矩形频带,每个三角的峰值和其相邻三角的边界点重合。
设$w_b(k)$为频带$b$在频率$k$处的振幅,有$\sum_bw_b(k)=1$。对于频域信号$X(k)$,某一个band频带中的能量由下式给出
$$公式2:E(b)=\sum_{k} w_{b}(k)|X(k)|^{2}$$
每个频带band的增益定义为$g_b$
$$公式3:g_{b}=\sqrt{\frac{E_{s}(b)}{E_{x}(b)}}$$
式中,$E_s(b)$是纯净语音(ground truth)的band能量,$E_x(b)$是输入(带噪)语音的band能量。增益g只有22个点,但是频谱有481个点,因此需要对增益$\hat{g}_b$进行插值,然后应用于每个频点$k$:
$$公式4:r(k)=\sum_{b} w_{b}(k) \hat{g}_{b}$$
B Pitch滤波器
因为我们神经网络使用的是bark scale bands,频带分辨率很低,丢失了频谱中很多精细的细节,阻碍pitch harmonics之间的噪声抑制。因此,我们利用一个梳状滤波器来抑制谐波之间的噪声,其方法类似于语音编解码后置滤波器的作用[14]。由于语音信号的周期性很大程度上依赖于频率(尤其是48 kHz采样率),因此基音滤波器在频域上基于每频带滤波系数$\alpha_b$进行工作。设$P(k)$为基音延迟信号$x(n-pindex)$进行DFT变换后的信号,滤波通过计算$X(k)+\alpha_bP(k)$进行,然后对得到的信号进行归一化,使其在每个频点的能量与原始信号$X(k)$相同。
频带$b$的基音相关性定义为:
$$公式5:p_{b}=\frac{\sum_{k} w_{b}(k) \Re\left[X(k) P^{*}(k)\right]}{\sqrt{\sum_{k} w_{b}(k)|X(k)|^{2} \cdot \sum_{k} w_{b}(k)|P(k)|^{2}}}$$
其中$\Re$表示复数值的实部,.* 表示复共轭。 请注意,对于单个band,公式(5) 将等效于时域上求基音相关性。
推导滤波器系数$\alpha_b$的最优值是困难的,使均方误差最小的值在感知上不一定是最优的。因为噪声会导致基音相关度(pitch correlation)的降低,我们不希望$p_b>g_b$,因而考虑以下几种情况进行约束:
- 对于$p_b \geq g_b$的频段,说明$x(n)$本身噪声较大,导致神经网络预测的基音相关性$g_b$较小,需要利用pitch延时信号来加强语音,所以$\alpha_b=1$。
- 在没有噪声的情况下,我们不想使信号失真,所以当$g_b = 1$时,所以$\alpha_b = 0$。
- 当$p_b = 0$时,即基音相关度为0时,没有pitch要增强,所以$\alpha_b = 0$。
可以使用一个式子来包含这些情况:
$$公式6:\alpha_{b}=\min \left(\sqrt{\frac{p_{b}^{2}\left(1-g_{b}^{2}\right)}{\left(1-p_{b}^{2}\right) g_{b}^{2}}}, 1\right)$$
上面提到的滤波器为 FIR pitch滤波器,也可以基于$H(z)=1 /\left(1-\beta z^{-T}\right)$形式的 IIR pitch滤波器计算$P(k)$,从而以略微增加失真为代价换来谐波之间的更多衰减。
C 特征提取
只有在网络的输入中包含与输出相同频带的噪声信号的对数谱才有意义。
- 22个频带能量 做 对数变换 再做 DCT,得到22个Bark-frequency倒频谱系数(BFCC)[0-21]
- 前6个BFCC的一阶时间导数和二阶时间导数[22-33]。
- 前6个基音相关度[34-39],因为我们已经需要计算(公式5)中的pitch,所以我们计算跨频带基音相关的DCT,并将前6个系数包含在我们的特征集中。
- 1个基音周期[40]($\frac{1}{基频}$)
- 1个特殊的非平稳值[41],可用于检测语音
我们总共使用了42个输入特性
与语音识别中通常使用的特征不同,这些特征不使用倒谱均值归一化,并且包含第一个倒谱系数。这个选择是经过深思熟虑的,因为我们必须跟踪噪声的绝对振幅,但它确实使特征对信号的绝对振幅和信道频率响应敏感。这在第3-A节中有说明。
3 深度学习模型
神经网络与传统的噪声抑制算法结构密切相关,如图3所示。该设计基于以下假设:三个循环层分别负责图1中的一个基本组件。当然,在实践中,神经网络可以自由地偏离这个假设(而且在某种程度上很可能是这样的)。它总共包含215个单位,4个隐藏层,最大的层有96个单位。我们发现,增加单元数量并不能显著改善噪声抑制的质量。然而,损失函数和我们构造训练数据的方式对最终质量有很大的影响。我们发现门控循环单元(GRU)[15]在这个任务上略优于LSTM,同时也更简单。
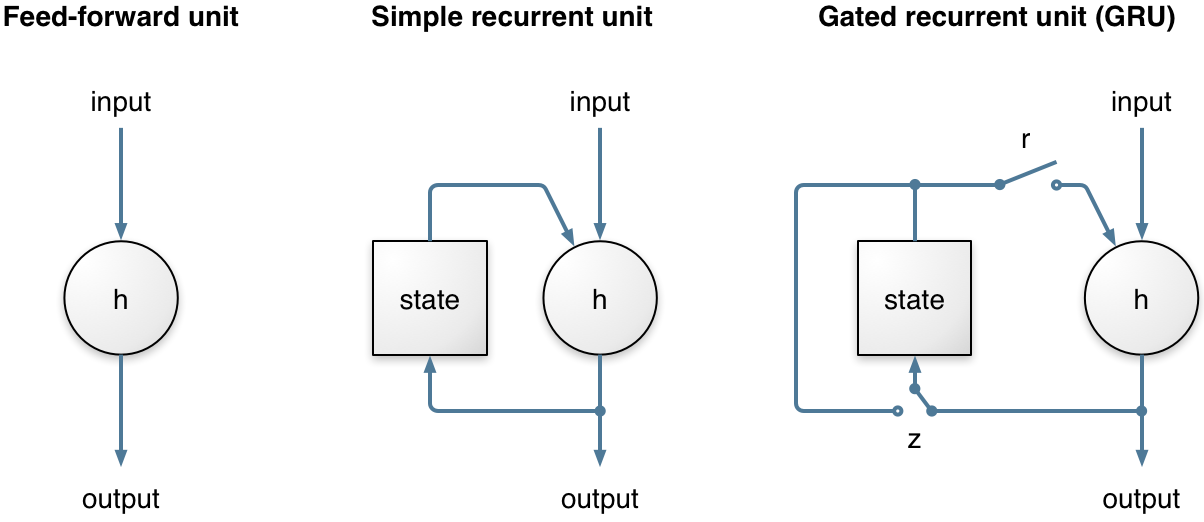
循环神经网络 (RNN) 在这里非常重要,因为它们可以对时间序列进行建模,而不仅仅是独立考虑输入和输出帧。这对于噪声抑制尤其重要,因为我们需要时间来对噪声进行良好的估计。长期以来,RNN 的能力受到严重限制,因为它们无法长时间保存信息,并且由于时间反向传播时涉及的梯度下降过程非常低效(梯度消失问题)。这两个问题都通过门控单元的发明解决,例如长短期记忆 (LSTM)、门控循环单元 (GRU) 及其许多变体。
RNNoise 使用门控循环单元 (GRU),因为它在此任务上的性能略好于 LSTM,并且需要更少的资源(用于权重的 CPU 和内存)。与简单的 循环单元相比,GRU 有两个额外的门。该复位是否状态(存储器)栅极控制在计算新的状态下使用,而更新栅极控制状态将改变多少基于新的输入。这个更新门(关闭时)使 GRU 可以(并且很容易)长时间记住信息,这也是 GRU(和 LSTM)比简单的循环单元表现得更好的原因。
网络包括一个VAD输出,尽管事实上它不是严格必需的。额外的复杂性代价非常小(24个额外权重),它通过确保相应的GRU确实学会了从噪声中区分语音来改进训练。
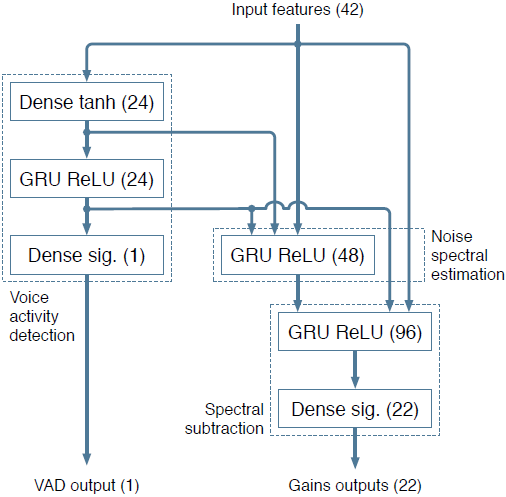
图3 神经网络的架构,显示前馈、全连接(密集)层和循环层,以及每层的激活函数和单元数
网络的一个输出是一组应用于不同频率的增益。另一个输出是语音活动概率,它不用于噪声抑制,而是网络的有用副产品。
A 训练数据
神经网络的训练需要 带噪语音 和 纯净语音的,但是我们很少能同时获得干净的语音和嘈杂的语音。因此必须通过在干净的语音数据中加入噪声来人工构造训练数据。我们还必须确保涵盖各种录制条件。例如,当音频以 8 kHz 进行低通滤波时,仅在全频带音频 (0-20 kHz) 上训练的早期版本将失败。对于语音数据,我们使用McGill TSP语音数据库 (法语和英语)和 NTT多语言电话语音数据库(21种语言)(使用44.1kHz音频CD轨道被使用而不是16kHz数据文件)。人们使用各种各样的噪声源,包括电脑风扇、办公室、人群、飞机、汽车、火车和建筑。噪声在不同的 level 上混合,以产生广泛的信噪比,包括干净的语音和纯噪声段。
由于我们没有使用倒谱平均归一化,并保留代表能量的第一个倒谱系数。我们使用数据增强使网络对频率响应的变化具有鲁棒性。 这是通过使用以下形式的二阶滤波器为每个训练示例独立过滤噪声和语音信号来实现的
$$公式7:H(z)=\frac{1+r_{1} z^{-1}+r_{2} z^{-2}}{1+r_{3} z^{-1}+r_{4} z^{-2}}$$
其中$r_1 ... r_4$中的每一个都是在$[-\frac{3}{8},\frac{3}{8}]$范围内均匀分布的随机值。 通过改变混合信号的最终幅值来实现信号幅度的稳健性。
我们总共有6小时的语音和4小时的噪声数据,我们使用这些数据产生140小时的噪声语音,通过使用各种增益和滤波器的组合,并将数据重新采样到40 kHz和54 kHz之间的频率。
B 优化过程
损失函数决定了当网络不能准确地估计正确增益,网络如何权衡过度衰减和不足衰减。虽然在优化[0,1]范围的值时,通常使用二元交叉熵函数,但这并不会产生良好的结果,因为它与它们的感知效果不匹配。对于增益估计$\hat{g}_b$和相应的ground truth $g_b$,我们用下面的损失函数训练
$$公式8:L\left(g_{b}, \hat{g}_{b}\right)=\left(g_{b}^{\gamma}-\hat{g}_{b}^{\gamma}\right)^{2}$$
其中$\gamma $指数是一个感知参数,用于控制抑制噪声的积极程度。 由于$lim_{\gamma\rightarrow 0}\frac{x^\gamma-1}{\gamma}=log(x)$,$lim_{\gamma\rightarrow 0}L(g_b,\hat{g}_b)$最小化了对数能量的均方误差,鉴于增益没有下限,这会使抑制过于激进。 实际上,值$\gamma=\frac{1}{2}$提供了一个很好的权衡,等效于最小化能量的$\frac{1}{4}$次幂的均方误差。 有时,特定频段中可能没有噪音和语音。 这在输入无声时或在信号被低通滤波时的高频时很常见。 当发生这种情况时,ground truth 增益被明确标记为未定义,并且该增益的损失函数被忽略以避免损害训练过程。
对于网络的VAD输出,我们使用标准的交叉熵损失函数。训练使用Keras库和Tensorflow后端进行。由于 Python 通常不是实时系统的首选语言,我们必须用 C 实现运行时代码。幸运的是,运行神经网络比训练神经网络容易得多,所以我们所要做的就是实现 feed -forward 和 GRU 层。为了更容易地在合理的足迹中拟合权重,我们在训练期间将权重的大小限制为 +/- 0.5,这样可以轻松地使用 8 位值存储它们。生成的模型仅适合 85 kB(而不是将权重存储为 32 位浮点数所需的 340 kB)。
C 代码在 BSD 许可下可用。尽管在编写此演示时,代码尚未优化,但它在 x86 CPU 上的运行速度已经比实时快 60 倍。它甚至比在 Raspberry Pi 3 上的实时运行速度快约 7 倍。通过良好的矢量化 (SSE/AVX),应该可以使其比当前快约 4 倍。
C 增益平滑
当使用增益$\hat{g}_b$来抑制噪声时,输出信号有时听起来过于干燥,缺乏最低期望的混响水平。这个问题很容易通过限制$\hat{g}_b$的跨帧衰减来解决。平滑增益$\tilde{g}_b$为
$$\tilde{g}_{b}=\max \left(\lambda \tilde{g}_{b}^{(p r e v)}, \hat{g}_{b}\right)$$
其中$\tilde{g}_b^{prev}$是前一帧的滤波增益,衰减因子$\lambda=0.6$相当于 135 ms 的混响时间。
4 复杂度分析
为了便于部署噪声抑制算法,需要保持较低的大小和复杂性。 可执行文件的大小由代表神经网络中 215 个单元所需的 87,503 个权重决定。 为了保持尽可能小的尺寸,可以将权重量化为 8 位而不损失性能。 这使得在 CPU 的 L2 缓存中适合所有权重成为可能。
由于每个权重在乘加运算中每帧只使用一次,因此神经网络每帧需要 175,000 次浮点运算(我们将乘加算作两次运算),因此需要 17.5 Mflops 以供实时使用。 IFFT 和每帧两个 FFT 需要大约 7.5 Mflops,pitch搜索(以 12 kHz 运行)需要大约 10 Mflops。 该算法的总复杂度约为 40 Mflops,可与全频带语音编码器相媲美。
该算法的非矢量化 C 实现需要大约 1.3% 的单个 x86 内核 (Haswell i7-4800MQ) 来执行单个通道的 48 kHz 噪声抑制。 1.2 GHz ARM Cortex-A53 内核(Raspberry Pi 3)上相同浮点代码的实时复杂度为 14%。
作为比较,[9] 中的 16 kHz 语音增强方法使用 3 个隐藏层,每个隐藏层有 2048 个单元。 这需要 1250 万个权重并导致 1600 Mflops 的复杂性。 即使量化为 8 位,权重也不适合大多数 CPU 的缓存,实时操作需要大约 800 MB/s 的内存带宽。
5 结果
我们使用训练集中未使用的语音和噪声数据来测试噪声抑制的质量。 我们将其与 SpeexDSP 库 中基于 MMSE 的噪声抑制器进行比较。 尽管噪声抑制在 48 kHz 下运行,但由于宽带 PESQ [16] 的限制,必须将输出重新采样到 16 kHz。 图 5 中的客观结果表明,使用深度学习显着提高了质量,尤其是对于非平稳噪声类型。 通过随意聆听样本证实了改进。 图4显示了噪声抑制对示例的影响。
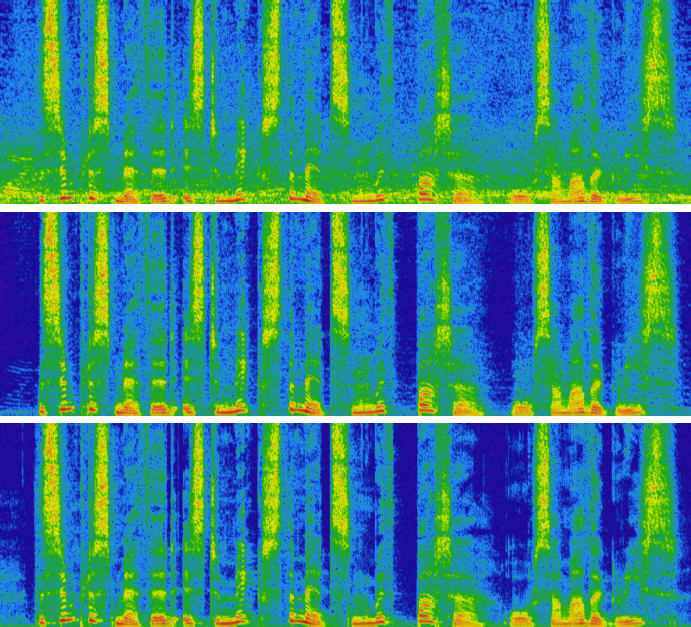
图4 在15db信噪比下抑制胡言乱语噪声的例子。噪声(上)、去噪(中)和干净(下)语音的声谱图。为了清晰起见,只显示0-12千赫波段
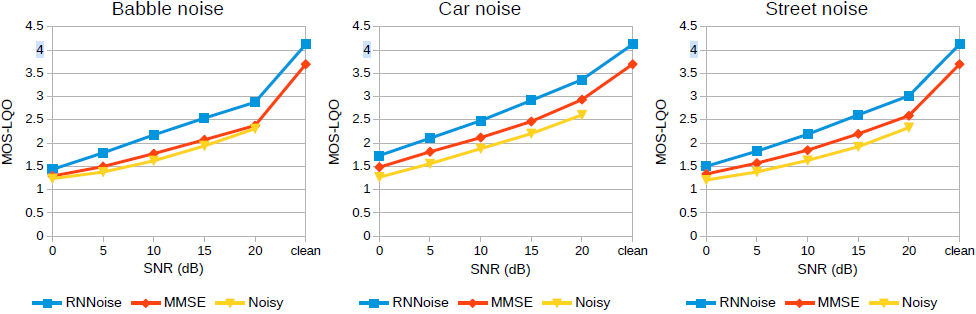
图5 PESQ MOS-LQO对噪音、汽车噪音和街道噪音的质量评估
我们提出来系统的交互式演示可在 https://people.xiph.org/~jm/demo/rnnoise/ 获得,包括实时 Javascript 实现。 实现提出系统的软件可以在 https://github.com/xiph/rnnoise/ 的 BSD 许可下获得,结果是使用提交哈希 91ef401 生成的。
6 总结
本文介绍了一种将基于DSP技术和深度学习相结合的噪声抑制方法。通过仅对难以调谐的噪声抑制方面使用深度学习,问题被简化为仅计算22个理想的临界频带增益,这可以使用很少的单元有效地完成。然后,通过使用简单的pitch滤波器处理频带的粗略分辨率。由此产生的低复杂性使得该方法适合在移动或嵌入式设备中使用,并且延迟足够低,可用于视频会议系统。我们还证明,质量明显高于基于纯信号处理的方法。
我们认为该技术可以很容易地扩展到残余回声抑制,例如通过在输入特征中加入远端信号或滤波后的远端信号的倒频谱。类似地,它应该适用于麦克风阵列后置滤波,通过使用 [17] 中的泄漏估计来增强输入特征。
参考文献
[1] S. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE Transactions on acoustics, speech, and signal processing, vol. 27, no. 2, pp. 113 120, 1979.
[2] H.-G. Hirsch and C. Ehrlicher, Noise estimation techniques for robust speech recognition, in Proc. ICASSP, 1995, vol. 1, pp. 153 156.
[3] T. Gerkmann and R.C. Hendriks, Unbiased MMSE-based noise power estimation with low complexity and low tracking delay, IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 4, pp. 1383 1393, 2012.
[4] Y. Ephraim and D. Malah, Speech enhancement using a minimum mean-square error log-spectral amplitude estimator, IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 33, no. 2, pp. 443 445, 1985.
[5] A. Maas, Q.V. Le, T.M. O Neil, O. Vinyals, P. Nguyen, and A.Y. Ng, Recurrent neural networks for noise reduction in robust ASR, in Proc. INTERSPEECH, 2012.
[6] D. Liu, P. Smaragdis, and M. Kim, Experiments on deep learning for speech denoising, in Proc. Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[7] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, A regression approach to speech enhancement based on deep neural networks, IEEE Transactions on Audio, Speech and Language Processing, vol. 23, no. 1, pp. 7 19, 2015.
[8] A. Narayanan and D. Wang, Ideal ratio mask estimation using deep neural networks for robust speech recognition, in Proc. ICASSP, 2013, pp. 7092 7096.
[9] S. Mirsamadi and I. Tashev, Causal speech enhancement combining data-driven learning and suppression rule estimation. , in Proc. INTERSPEECH, 2016, pp. 2870 2874.
[10] C. Montgomery, Vorbis I specification, 2004.
[11] J. Princen and A. Bradley, Analysis/synthesis filter bank design based on time domain aliasing cancellation, IEEE Tran. on Acoustics, Speech, and Signal Processing, vol. 34, no. 5, pp. 1153 1161, 1986.
[12] B.C.J. Moore, An introduction to the psychology of hearing, Brill, 2012.
[13] J.-M. Valin, G. Maxwell, T. B. Terriberry, and K. Vos, High-quality, low-delay music coding in the Opus codec, in Proc. 135th AES Convention, 2013.
[14] Juin-Hwey Chen and Allen Gersho, Adaptive postfiltering for quality enhancement of coded speech, IEEE Transactions on Speech and Audio Processing, vol. 3, no. 1, pp. 59 71, 1995.
[15] K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio, On the properties of neural machine translation: Encoder-decoder approaches, in Proc. Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), 2014.
[16] ITU-T, Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs, 2001.
[17] J.-M. Valin, J. Rouat, and F. Michaud, Microphone array post-filter for separation of simultaneous non-stationary sources, in Proc. ICASSP, 2004.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号