论文翻译:2020_Improving Perceptual Quality By Phone-Fortified Perceptual Loss For Speech Enhancement
论文代码:https://github.com/aleXiehta/PhoneFortifiedPerceptualLoss
引用格式:Hsieh T A, Yu C, Fu S W, et al. Improving Perceptual Quality by Phone-Fortified Perceptual Loss using Wasserstein Distance for Speech Enhancement[J]. arXiv preprint arXiv:2010.15174, 2020.
摘要
语音增强(SE)的目标是提高语音质量和可懂度,这两个方面都与语音段的平稳过渡有关,这些语音段可能包含语音和音节等语言信息。在这项研究中,我们在训练过程中考虑到语音的特点。因此,我们设计了一个电话强化感知(PFP)损失,并以PFP损失为指导来训练我们的SE模型。在PFP损失中,采用基于对比预测编码(CPC)准则的无监督学习模型wav2vec来提取语音特征。与以往的基于深度特征的方法不同,该方法明确地利用深层特征提取过程中的语音信息来指导SE模型的训练。为了验证所提出的方法,我们首先使用t-分布随机邻近嵌入(t-SNE)分析来确认wav2vec表示包含清晰的语音信息。接下来,我们观察到,所提出的PFP损失与感知评估指标的相关性比逐点和信号级损失更为密切,从而在语音Bank–DEMAND数据集中获得了更高的标准化质量和可理解性评估指标的分数。
1 引言
在现实世界中与语音相关的应用中,语音信号可能会由于环境噪声而失真,从而限制了目标任务可实现的性能。为了解决这个问题,语音增强(SE)已经研究了数十年。已经提出了许多基于信号处理的方法[1、2、3、4]。这些方法基于语音和噪声信号的假定统计属性。当这些假定的属性无法实现时,SE性能可能会大大下降。随着神经网络(NN)模型的最新发展,SE性能显着提高。众所周知的NN模型,例如深度去噪自动编码器(DDAE)[5],深度神经网络(DNN)[6],递归神经网络(RNN)[7],长短期记忆(LSTM)[8],卷积神经网络(CNN)[9],完全卷积网络(FCN)[10、11],卷积递归神经网络(CRNN)[12]和生成对抗网络(GAN)[13、14、15、16、17、18 [19],对基于传统信号处理的SE方法进行了显着改进。
对于这些基于NN的SE方法,设计合适的目标函数非常重要。传统上,逐点距离经常被用作目标函数。点对点距离被计算为成对的噪声干净语音信号之间的L1和/或L2范数,试图恢复信号上的信息。最近的研究表明,基于点距的目标函数可能无法完全反映噪声和干净语音信号之间的感知差异。由于SE的目的是恢复语音质量和清晰度,因此针对基于NN的SE研究了使用感知指标的目标函数。在这些研究中,为了方便神经网络参数优化中的梯度计算,在其可微方案中修改了感知度量。一些值得注意的工作包括基于感知评估的损失函数[20],用于语音质量优化的联合信号失真比(SDR)感知评估[21]和用于网络优化的改进的短时目标清晰度(STOI)损失函数[10, 22,23]。沿着这条思路,一些研究集中在训练神经网络模型和目标度量为SE任务[24],以及诸如HiFi-GAN [18]和MetricGAN [19]等GAN方法中的模型。
除了评估度量的直接优化之外,目标函数还可以基于潜在空间中的表示来设计,以最大程度地减少损失,其中潜在空间来自预先训练的模型,该模型具有成对的干净噪声语音信号。 例如,在计算机视觉的风格转移研究中,[25]提出了基于感知损失的训练前馈网络。 在[26]中,作者提出利用声学场景识别网络的潜在空间作为损失函数,称为深度特征损失(DFL),并获得了可喜的结果。 我们相信,通过使用与SE任务更相关的NN模型提取的潜在表示,可以进一步改善此类目标函数。
在本文中,我们明确考虑了SE的语音特性。 为了强调这些特征,为SE模型优化设计了一个电话强化的感知(PFP)损失。 实验结果表明,wav2vec编码的语音特征代表语音信息。 我们可以得出结论,我们提出的包含PFP损失的框架相对于SE任务的其他感知优化方法提出了很大的改进。
2 相关工作
在本节中,我们首先介绍上一节中提到的DFL,并在2.1节中进行更详细的讨论。 然后,我们回顾了用训练网络近似的感知指标。这样的网络可以作为GAN或独立度量中的鉴别器。最后但并非最不重要的是,在第2.3节中,我们回顾了在上下文中最大化相互信息的方法。
2.1 深度特征损失
在DFL中提出了将声学场景识别纳入SE的想法[26]。根据[18],来自预训练的识别网络(用于机器感知)的潜在特征被用来近似人类的感知(在本例中是SE)。然而,声音场景识别似乎缺少语音特征信息,我们认为这是针对人类感知优化SE的关键。
2.2 MetricGAN和HiFi GAN
MetricGAN [19]应用了一个鉴别器(也称为Quality-Net [27])来近似评估评估函数的行为。 预测分数也可以被视为感知损失的特例,其嵌入维度等于1。由于维度有限,Quality-Net容易被更新的生成器生成的语音所欺骗。 因此,MetricGAN需要在生成器和鉴别器之间进行迭代训练,这会降低其训练效率。 HiFi-GAN [18]融合了GAN训练和深度特征损失的思想。 然而,其深层特征损失是基于鉴别器的,这可能与人类感知没有高度关系。
2.3 对比预测编码(CPC)与wav2vec
为了充分利用语音特征,我们调查了表征学习方法,这些方法可以直接从原始数据中自动发现代表性特征。最近在该研究领域中提出了一些值得注意的方法。例如,CPC [28]是一种无监督方法,提议从高维数据中提取信息丰富的特征。 CPC方法中的概率对比损失有助于捕获潜在特征,从而最大程度地提高了对未来样本的预测精度。然后,我们将重点放在使用表示学习方法的语音相关应用上。利用CPC技术的无监督自动语音识别(ASR)wav2vec[29]在识别精度上表现出了很大的表现。在实践中,语音信号首先通过编码器网络进行编码,该编码器网络提取具有丰富语音特征的特征。然后,基于这些特征作为输入来训练ASR解码器。根据我们对语音声学的理解,由于噪声污染,语音特征信息可能会大大失真。
就我们的直觉而言,至关重要的是,SE任务的目标函数应更注重语音特征(或语音特性级别)的特征域方面增强的语音完整性上,而不是简单地考虑信号层面的语音完整性。 也就是说,旨在最小化信号级别损失的SE不能保证语音特性级别上的完整性,因此尽管信号电平损失令人满意,但是在感知度量方面仍存在可观察到的失配。 结果,我们提出的PFP损失采用了wav2vec编码器网络的潜在空间,该空间提取了语音特征丰富的特征以创建损失域。 然后,我们设计一个PFP损耗,该损耗将在语音特征级别上执行距离计算。 我们还将平均绝对误差(MAE)与PFP损失相结合,以确保在SE的语音特征级别和信号级别上都进行优化。
3 提出的框架
在设计一个有效的基于神经网络的SE系统时,有两个方面是重要的。一种是模型结构,它可以有效地逼近噪声和干净语音之间的复杂映射函数。另一种是目标函数,在模型优化过程中保留必要的语音信息。
3.1 模型框架
受到[30]中的深层复杂U-Net(DCUnet)的启发,我们设计了一种修改后的框架,该框架使用不同的归一化机制为嘈杂的复数频谱估计了复数比率掩码(cRM)。具体来说,如图1所示,先将含噪语音信号通过短时傅立叶变换(short-time Fourier transform, STFT)转换为复频谱,增强模型生成cRM。然后,将噪声频谱逐点乘上cRM得到最终增强频谱,并通过逆STFT (iSTFT)变换得到波形。根据[30]的说法,本工作中使用了一种使用复数神经网络(cRMCn)产生cRM的方案。我们将大DCUnet -20[30]作为增强模型的参考架构。由于以前的许多工作[31,32]表明,实例归一化(instance normalization)在小批量中保留了样本的独立性,因此在生成任务上优于批归一化(batch normalization),我们用实例归一化层替代了DCUnet -20中的batch normalization层。为了精确地描述增强过程,在给定有噪声的输入语音信号$x$的情况下,由STFT得出噪声频谱$X_{t,f}$,使得$X_{t,f}=STFT(x)$,然后,增强模型生成一个cRM $M_{t,f}=_\theta(X_{t,f})$来产生增强频谱$\hat{Y}_{t,f}=M_{t,f}·X_{t,f}$,并通过iSTFT将其转换为增强波形$\hat{y}$。
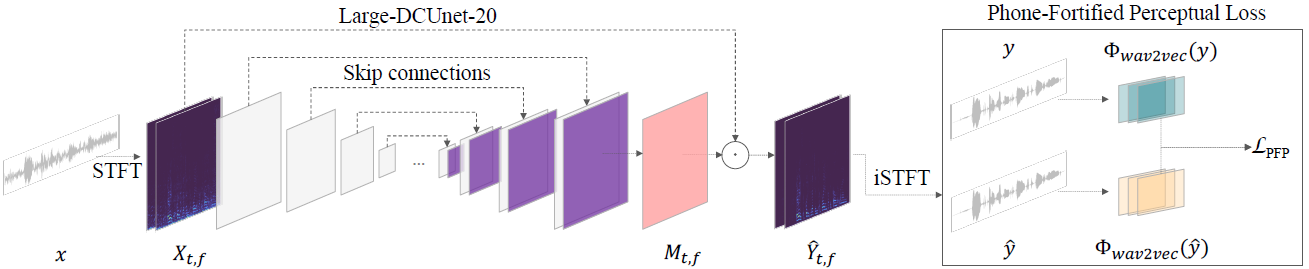
图1:我们提出的网络的框图。增强模型通过噪声频谱估计客户关系管理,从而产生一个增强的频谱
3.2 Phone-Fortified感知损失
由于SE系统的输出始终是语音信号,因此我们建议考虑与人的语音感知特性相匹配的PFP损失。由于one-hot编码的标签假定两个任意标签之间的相似度为零,这可能会低估手机之间的相关性,因此限制了特征表示,因此我们采用了无监督训练模型来计算PFP损失。由于语音信号会携带电话,而噪音不会携带电话,因此我们需要一种能够产生代表语音特征的特征损失模型。另外,由于CNN因其平移不变性而闻名,这类似于语音质量感知评估(PESQ)的行为[33],因此wav2vec编码器似乎适合我们的工作。对于PFP损失模型,wav2vec大的基于CNN的编码器$\Phi _{wav2vec}$将原始波形输入转换为一批512维矢量序列。损失模型的参数在训练期间是固定的。与先前关于感知损失的研究工作不同,该研究利用多层激活,仅提取最终输出,PFP损失定义为
$$公式1:\mathcal{L}_{\mathrm{PFP}}(x, y):=\mathbb{E}_{x, y \sim \mathcal{D}}\left[\left\|\Phi_{\text {wav2vec}}(y)-\Phi_{\text {wav2vec}}\left(f_{\theta}(x)\right)\right\|_{1}\right]$$
对于给定的来自D数据集的成对带噪语音x和干净语音y, PFP损失使干净语音和增强语音之间的语音距离最小。
4 实验
在本节中,我们从选择的数据集和作为标准基准使用的评估指标开始。接下来,我们提供可视化演示,说明由PFP损失模型生成的特征与PESQ和STOI相关。实验结果表明,所提出的改进方法在感知质量方面取得了较好的效果。
4.1 Voice Bank–DEMAND 数据集
为了将我们提出的SE系统与其他最近的方法进行比较,我们使用了语音银行需求数据集[34,35]进行评估。在这个数据集中,总共30个说话人中的28个说话人的话语被用于训练,剩下的2个说话人的话语被用于测试。在训练集中,利用10种噪声在4种不同信噪比(SNR)范围内合成噪声混合,并在测试集中加入5种不可见噪声,范围在2.5 dB到17.5 dB之间。
4.2 评估度量方法
在对语音银行需求数据集进行先前的工作评估之后,我们使用了五个指标,分别是CSIG、CBAK、COVL、[36]、PESQ和STOI,来衡量所提出的方法的性能。CSIG、CBAK和COVL分别代表了相同尺度的平均意见评分的信号失真、背景干扰和整体质量。PESQ和STOI分别量化语音信号的感知质量和可理解性。
4.3 将 SE 作为最优传输问题
如3.2节所述,通过wav2vec提取的特征对于语音特征是有用的。为了验证生成的特征能够有效地保存语音信息,我们展示了一个通过t-SNE将高维特征投射到二维空间的例子,t-SNE是一种非线性降维技术,广泛用于验证嵌入的有效性。如图2 (a)所示,将五种类型的手机分为五组。我们认为wav2vec生成的特征可以代表语音特征。在图2 (b)中,PFP损失模型可以区分大部分的噪声和干净的语音,即根据估计与目标语音的距离更新增强模型。
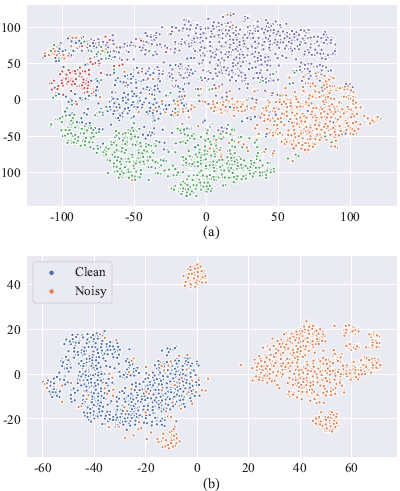
图2所示。基于wav2vec编码特征图的t-SNE分析
(a)五个手机类的特征图。(b)干净和嘈杂话语特征图
4.4 感知指标与损失的相关性
为了评估不同损失的转移敏感性,我们说明了损失在时间转移中的趋势。由于损失具有不同的规模,直接比较损失变化是不现实的。相反,我们使用损失与其次小值的比率,在图3中称为差异率。如图3所示,PESQ在时移水平上是一致的。比较所有列出的损失,DFL和我们提出的PFP损失比其他三个信号级别的损失更不敏感,更像听觉感知。
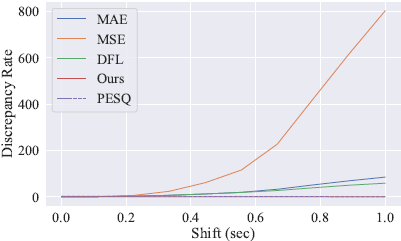
图3 不同时移水平下不同损失的趋势及其价值反应
4.5 PFPL 的消融研究
为了分析感知指标和其他损失之间的关系,我们将几种不同的损失与测试集中相应的指标得分进行了比较。注意,由于报告布局的局限性,我们报告了PESQ、STOI和不同损失值之间的关系。完整的比较和分析报告可以在我们的GitHub页面上访问。在图4中,我们说明了PESQ和STOI与五种损失的关系,包括MAE、均方误差(MSE)、加权信号失真比(wSDR)、深度特征损失(Deep Feature Loss)和PFP损失。在图4中,MAE和MSE与这两个指标有相似的相关性,四组点代表测试集中的四个信噪比水平。对于前三个损失,这两个指标之间没有明显的关系。然而,更明显的趋势是,DFL和PFP损失与PESQ和STOI相关。这里,利用皮尔逊相关系数(Pearson correlation coefficient, PCC)来量化指标与损失之间的相关性。图4中括号内为损失的pcc。PFP损失的PCC远高于其他指标的PCC。对比表1和表2,尽管DFL与PESQ的相关性比其他三个信号水平指标更高,但它与wSDR、MAE和MSE的结果相似。然而,由于PFP损失模型衡量的是语音信息方面特征的不同程度,而这在人类听觉系统中更为突出,因此PFP损失与PESQ和STOI高度相关是合理的。
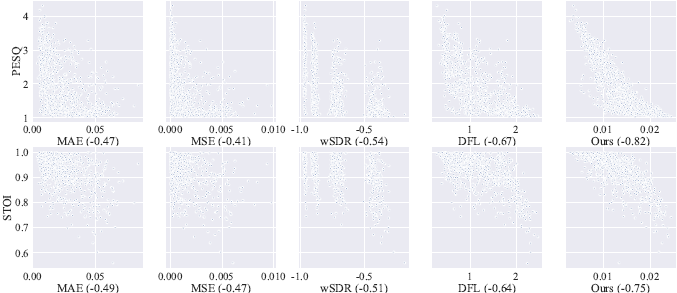
图4所示。这个图说明了PESQ和STOI与不同损失的相关性
为了量化损失与度量的相关程度,我们注意到括号中的皮尔逊相关系数
PCC的绝对值越高,说明损失与度量指标的相关性越强
4.6 定性分析
在表1中,我们比较了之前使用非信号水平目标的方法和关于感知专业损失的研究。在所有方法中,我们获得了最高的PESQ分数。需要注意的是,感知损失在处理背景噪声方面表现较差,因为网络更新时不考虑信号级别距离,所以与其他方法相比,CBAK仍然较低。为了解决这一不足,我们将MAE合并到PFP损失中,从而迫使增强模型匹配潜伏空间中的目标和信号水平。在表2中,我们进一步比较了使用相同增强模型的几种损失。与PFP损失相比,信号水平的损失导致较低的PESQ,但较高的CBAK。与仅通过PFP损失优化的结果相比,添加MAE在很大程度上消除了噪声干扰,从而获得更高的CBAK评分。
表1 我们提出的方法与一些关于不同度量的性能良好的方法相比。
DFL显示来自官方源代码和发布参数的结果。
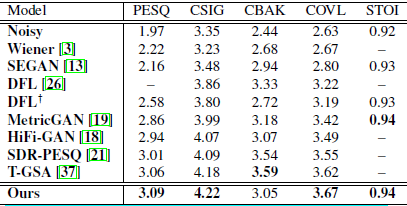
表2 我们提出的模型使用我们提出的损失对比使用不同的损失评估指标

5 结论
在本文中,我们提出了一种新的用于训练SE模型的PFPL损失。PFPL是基于Wave2vec模型的潜在表示导出的,该模型携带了丰富的语音信息。同时,PFPL使用Wasserstein距离作为距离度量。因此,SE训练可以看作是一个最优传输问题,其目标是将噪声语音的潜在再现分布转移到干净语音的潜在再现分布。实验结果首次表明,与其他相关的损失函数相比,PFPL与感知度量具有非常高的相关性。此外,用PFPL训练的SE模型的性能优于几个著名的标准化评价指标和相关工作。
参考文献
[1] S. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE TASSP, vol. 27, no. 2, pp. 113 120, 1979.
[2] J.S. Lim and A.V. Oppenheim, Enhancement and bandwidth compression of noisy speech, Proceedings of the IEEE, vol. 67, no. 12, pp. 1586 1604, 1979.
[3] K. Paliwal and A. Basu, A speech enhancement method based on kalman filtering, in Proc. ICASSP, 1987.
[4] P. Loizou, Speech enhancement: theory and practice, CRC press, 2013.
[5] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, Speech enhancement based on deep denoising autoencoder. , in Proc. Interspeech, 2013, vol. 2013, pp. 436 440.
[6] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, A regression approach to speech enhancement based on deep neural networks, IEEE/ACM TASLP, vol. 23, no. 1, pp. 7 19, 2014.
[7] F. Weninger, F. Eyben, and B. Schuller, Single-channel speech separation with memory-enhanced recurrent neural networks, in Proc. ICASSP, 2014.
[8] F.Weninger, H. Erdogan, S.Watanabe, E. Vincent, J. Le Roux, J. Hershey, and B. Schuller, Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr, in Proc. LVA/ICA, 2015.
[9] H. Zhao, S. Zarar, I. Tashev, and C.-H. Lee, Convolutionalrecurrent neural networks for speech enhancement, in Proc. ICASSP, 2018.
[10] S.-W. Fu, T.-W. Wang, Y. Tsao, X. Lu, and H. Kawai, Endto- end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks, IEEE/ACM TASLP, vol. 26, no. 9, pp. 1570 1584, 2018.
[11] A. Pandey and D. Wang, Tcnn: Temporal convolutional neural network for real-time speech enhancement in the time domain, in Proc. ICASSP, 2019.
[12] K. Tan and D. Wang, A convolutional recurrent neural network for real-time speech enhancement. , in Proc. Interspeech, 2018.
[13] Santiago S. Pascual, A. Bonafonte, and J. Serr`a, , in SEGAN: Speech Enhancement Generative Adversarial Network, 2017.
[14] M. Soni, N. Shah, and H. Patil, Time-frequency maskingbased speech enhancement using generative adversarial network, in Proc. ICASSP, 2018.
[15] A. Pandey and D. Wang, On adversarial training and loss functions for speech enhancement, in Proc. ICASSP, 2018.
[16] D. Baby and S. Verhulst, Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty, in Proc. ICASSP, 2019.
[17] S. Qin and T. Jiang, Improved wasserstein conditional generative adversarial network speech enhancement, EURASIP Journal on Wireless Communications and Networking, vol. 2018, no. 1, pp. 181, 2018.
[18] J. Su, Z. Jin, and A. Finkelstein, Hifi-gan: High-fidelity denoising and dereverberation based on speech deep features in adversarial networks, Proc. Interspeech, 2020.
[19] S.-W. Fu, C.-F. Liao, Y. Tsao, and S.-D. Lin, Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement, in Proc. ICML, 2019.
[20] J. Mart ın-Do nas, A. Gomez, J. Gonzalez, and A. Peinado, A deep learning loss function based on the perceptual evaluation of the speech quality, IEEE Signal processing letters, vol. 25, no. 11, pp. 1680 1684, 2018.
[21] J. Kim, M. El-Kharmy, and J. Lee, End-to-end multi-task denoising for joint sdr and pesq optimization, arXiv preprint arXiv:1901.09146, 2019.
[22] M. Kolbæk, Z.-H. Tan, and J. Jensen, Monaural speech enhancement using deep neural networks by maximizing a shorttime objective intelligibility measure, in Proc. ICASSP, 2018.
[23] Y. Zhao, B. Xu, R. Giri, and T. Zhang, Perceptually guided speech enhancement using deep neural networks, in Proc. ICASSP, 2018.
[24] S.-W. Fu, C.-F. Liao, and Y. Tsao, Learning with learned loss function: Speech enhancement with quality-net to improve perceptual evaluation of speech quality, IEEE Signal Processing Letters, vol. 27, pp. 26 30, 2019.
[25] J. Johnson, A. Alahi, and F.-F. Li, Perceptual losses for realtime style transfer and super-resolution, in Proc. ECCV, 2016.
[26] F. Germain, Q. Chen, and V. Koltun, Speech denoising with deep feature losses, Proc. Interspeech, 2019.
[27] S.-W. Fu, Y. Tsao, H.-T. Hwang, and H.-M. Wang, Qualitynet: An end-to-end non-intrusive speech quality assessment model based on blstm, Proc. Interspeech, 2018.
[28] A. Oord, Y. Li, and O. Vinyals, Representation learning with contrastive predictive coding, arXiv preprint arXiv:1807.03748, 2018.
[29] S. Schneider, A. Baevski, R. Collobert, and M. Auli, wav2vec: Unsupervised pre-training for speech recognition, Proc. Interspeech, 2019.
[30] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee, Phase-aware speech enhancement with deep complex u-net, in Proc. ICLR, 2018.
[31] D. Ulyanov, A. Vedaldi, and V. Lempitsky, Instance normalization: The missing ingredient for fast stylization, arXiv preprint arXiv:1607.08022, 2016.
[32] X. Huang and S. J. Belongie, Arbitrary style transfer in realtime with adaptive instance normalization., in Proc. ICCV, 2017.
[33] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, in Proc. ICASSP, 2001.
[34] C. Veaux, J. Yamagishi, and S. King, The voice bank corpus: Design, collection and data analysis of a large regional accent speech database, in Proc. O-COCOSDA/CASLRE, 2013.
[35] J. Thiemann, N. Ito, and E. Vincent, Demand: a collection of multi-channel recordings of acoustic noise in diverse environments, in Proc. Meetings Acoust, 2013.
[36] Y. Hu and P. Loizou, Evaluation of objective quality measures for speech enhancement, IEEE TSAP, vol. 16, pp. 229 238, 2008.
[37] J. Kim, M. El-Khamy, and J. Lee, T-gsa: Transformer with gaussian-weighted self-attention for speech enhancement, in Proc. ICASSP, 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号