词向量表示:word2vec与词嵌入
在NLP任务中,训练数据一般是一句话(中文或英文),输入序列数据的每一步是一个字母。我们需要对数据进行的预处理是:先对这些字母使用独热编码再把它输入到RNN中,如字母a表示为(1, 0, 0, 0, …,0),字母b表示为(0, 1, 0, 0, …, 0)。如果只考虑小写字母a~z,那么每一步输入的向量的长度是26。如果一句话有1000个单词,我们需要使用 (1000, ) 维度的独热编码表示每一个单词。
缺点:
- 每一步输入的向量维数会非常大
- 在独热表示中,所有的单词之间都是平等的,单词间的依赖关系被忽略
解决方法:
- 使用word2vec,学习一种映射关系f,将一个高维词语(word)变成一个低维向量(vector),vec=f(word)。
实现词嵌入一般来说有两种方法:
- 基于“计数”的方法
- 在大型语料库中,计算一个词语和另一个词语同时出现的概率,将经常出现的词映射到向量空间的相似位置。
- 基于“预测”的方法
- 从一个词或几个词出发,预测它们可能的相邻词,在预测过程中自然而然地学习到了词嵌入的映射f。
通常使用的是基于预测的方法。具体来讲,又有两种基于预测的方法,分别叫CBOW和Skip-Gram,接下来会分别介绍它们的原理。
CBOW实现词嵌入的原理
CBOW(Continuous Bag of Words)连续词袋模型,利用某个词语的上下文预测这个词语。例如:The manfell in love with the woman。如果只看句子的前半部分,即The man fell in love with the_____,也可以大概率猜到横线处填的是“woman”。CBOW就是要训练一个模型,用上下文(在上面的句子里是“The man fell inlove with the”)来预测可能出现的单词(如woman)。
先来考虑用一个单词来预测另外一个单词的情况,对应的网络结构如下图所示:
CBOW模型:用一个单词预测一个单词
在这里,输入的单词还是被独热表示为x,经过一个全连接层得到隐含层h,h再经过一个全连接层得到输出y。
V是词汇表中的单词的数量,因此独热表示的x的维度是(V, )。另外输出y相当于做Softmax操作前的logits,它的形状也是(V, ),这是用一个单词预测另一个单词。隐层的神经元数量为N, N一般设定为小于V的值,训练完成后,隐层的值被当作是词的嵌入表示,即word2vec中的“vec”。
如何用多个词来预测一个词呢?答案很简单,可以先对它们做同样的全连接操作,将得到的值全部加起来得到隐含层的值。对应的结构如下图所示。
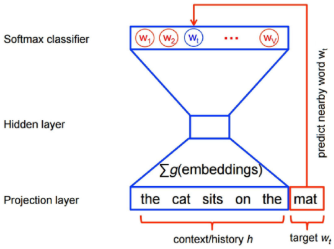
左图:CBOW模型:用多个单词预测一个单词;右图:CBOW模型的另外一种表示
在上图中,上下文是“the cat sits on the”,要预测的单词为“mat”。图中的∑g(embeddings)表示将the、cat、sits、on、the这5个单词的词嵌入表示加起来(即隐含层的值相加)。
在上述结构中,整个网络相当于是一个V类的分类器。V是单词表中单词的数量,这个值往往非常大,所以比较难以训练,通常会简单修改网络的结构,将V类分类变成两类分类。
具体来说,设要预测的目标词汇是“mat”,会在整个单词表中,随机地取出一些词作为“噪声词汇”,如“computer”、“boy”、“fork”。模型会做一个两类分类:判断一个词汇是否属于“噪声词汇”。一般地,设上下文为h,该上下文对应的真正目标词汇为$w_t$,噪声词汇为$\tilde{w}$,优化函数是
$$J=\ln Q_{\theta}\left(D=1 | \boldsymbol{w}_{t}, \boldsymbol{h}\right)+k \underset{\tilde{\boldsymbol{w}}-P_{\min }}{E}\left[\ln Q_{\theta}(D=0 | \tilde{\boldsymbol{w}}, \boldsymbol{h})\right]$$
$Q_{\theta}\left(D=1 | \boldsymbol{w}_{t}, \boldsymbol{h}\right)$代表的是利用真实词汇$w_t$和上下文$h$对应的词嵌入向量进行一次Logistic回归得到的概率。这样的Logistic回归实际可以看作一层神经网络。因为$w_t$为真实的目标单词,所以希望对应的D=1。另外噪声词汇$\tilde{w}$为与句子没关系的词汇,所以希望对应的D=0,即$\ln Q_{\theta}(D=0 | \tilde{w}_{t},{h})$。另外,$\underset{\tilde{w}-P_{noise}}{E}$表示期望,实际计算的时候不可能精确计算这样一个期望,通常的做法是随机取一些噪声单词去预估这个期望的值。该损失对应的网络结构如下图所示。
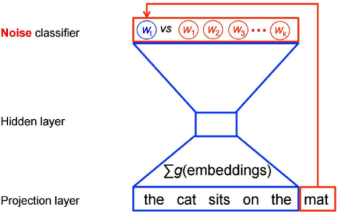
选取噪声词进行两类分类的CBOW模型
通过优化二分类损失函数来训练模型后,最后得到的模型中的隐含层可以看作是word2vec中的“vec”向量。对于一个单词,先将它独热表示输入模型,隐含层的值是对应的词嵌入表示。另外,在TensorFlow中,这里使用的损失被称为NCE损失,对应的函数为tf.nn.nce_loss。
Skip-Gram实现词嵌入的原理
有了CBOW的基础后,Skip-Gram的原理比较好理解了。在CBOW方法中,是使用上下文来预测出现的词,如上下文是:“The man fell in love with the”,要预测的词是“woman”。Skip-Gram方法和CBOW方法正好相反:使用“出现的词”来预测它“上下文文中词”。例如:The manfell in love with the woman。如果只看句子的前半部分,即The man fell in love with the_____,Skip-Gram是使用“woman”,来预测“man”、“fell”等单词。所以,可以把Skip-Gram方法看作从一个单词预测另一个单词的问题。
在损失的选择上,和CBOW一样,取出一些“噪声词”,训练一个两类分类器(即同样使用NCE损失)。
在TensorFlow中实现词嵌入
我们以Skip-Gram方法为例,在TensorFlow中训练一个词嵌入模型。
下载数据集
首先导入一些需要的库:
import collections import math import os import random import zipfile import numpy as np from six.moves import urllib from six.moves import xrange # pylint: disable=redefined-builtin import tensorflow as tf
为了用Skip-Gram方法训练语言模型,需要下载对应语言的语料库。在网站http://mattmahoney.net/dc/上提供了大量英语语料库供下载,为了方便学习,使用一个比较小的语料库http://mattmahoney.net/dc/text8.zip作为示例训练模型。程序会自动下载这个文件:


# 第一步: 在下面这个地址下载语料库 url = 'http://mattmahoney.net/dc/' def maybe_download(filename, expected_bytes): """ 这个函数的功能是: 如果filename不存在,就在上面的地址下载它。 如果filename存在,就跳过下载。 最终会检查文字的字节数是否和expected_bytes相同。 """ if not os.path.exists(filename): print('start downloading...') filename, _ = urllib.request.urlretrieve(url + filename, filename) statinfo = os.stat(filename) if statinfo.st_size == expected_bytes: print('Found and verified', filename) else: print(statinfo.st_size) raise Exception( 'Failed to verify ' + filename + '. Can you get to it with a browser?') return filename # 下载语料库text8.zip并验证下载 filename = maybe_download('text8.zip', 31344016)
正如注释中所说的,这段程序会从地址http://mattmahoney.net/dc/text8.zip下载该语料库,并保存为text8.zip文件。如果在当前目录中text8.zip已经存在了,则不会去下载。此外,这段程序还会验证text8.zip的字节数是否正确。
如果读者运行这段程序后,发现没有办法正常下载文件,可以尝试使用上述的url手动下载,并将下载好的文件放在当前目录下。
下载、验证完成后,使用下面的程序将语料库中的数据读出来:
# 将语料库解压,并转换成一个word的list def read_data(filename): """ 这个函数的功能是: 将下载好的zip文件解压并读取为word的list """ with zipfile.ZipFile(filename) as f: data = tf.compat.as_str(f.read(f.namelist()[0])).split() return data vocabulary = read_data(filename) print('Data size', len(vocabulary)) # 总长度为1700万左右 # 输出前100个词。 print(vocabulary[0:100])
这段程序会把text8.zip解压,并读取为Python中的列表,列表中的每一个元素是一个单词,如:
['anarchism', 'originated', 'as',...,'although', 'there', 'are', 'differing']
这个单词列表原本是一些连续的句子,只是在语料库的预处理中被去掉了标点。它是原始的语料库。
制作词表
下载并取出语料库后,来制作一个单词表,它可以将单词映射为一个数字,这个数字是该单词的id。如原来的数据是['anarchism', 'originated', 'as', 'a', 'term', 'of','abuse', 'first', ....., ],那么映射之后的数据是[5234, 3081,12, 6, 195, 2, 3134, 46, ....],其中5234代表单词anarchism,3081代表单词originated,依此类推。
一般来说,因为在语料库中有些词只出现有限的几次,如果单词表中包含了语料库中的所有词,会过于庞大。所以,单词表一般只包含最常用的那些词。对于剩下的不常用的词,会将它替换为一个罕见词标记“UNK”。所有的罕见词都会被映射为同一个单词id。
制作词表并对之前的语料库进行转换的代码为:
# 第二步: 制作一个词表,将不常见的词变成一个UNK标识符 # 词表的大小为5万(即我们只考虑最常出现的5万个词) vocabulary_size = 50000 def build_dataset(words, n_words): """ 函数功能:将原始的单词表示变成index """ count = [['UNK', -1]] count.extend(collections.Counter(words).most_common(n_words - 1)) dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) data = list() unk_count = 0 for word in words: if word in dictionary: index = dictionary[word] else: index = 0 # UNK的index为0 unk_count += 1 data.append(index) count[0][1] = unk_count reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reversed_dictionary data, count, dictionary, reverse_dictionary = build_dataset(vocabulary, vocabulary_size) del vocabulary # 删除已节省内存 # 输出最常出现的5个单词 print('Most common words (+UNK)', count[:5]) # 输出转换后的数据库data,和原来的单词(前10个) print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]]) # 我们下面就使用data来制作训练集 data_index = 0
在这里的程序中,单词表中只包含了最常用的50000个单词。请注意,在这个实现中,名词的单复数形式(如boy和boys),动词的不同时态(如make和made)都被算作是不同的单词。原来的训练数据vocabulary是一个单词的列表,在经过转换后,它变成了一个单词id的列表,即程序中的变量data,它的形式是[5234, 3081, 12, 6, 195, 2,3134, 46, ....]。
生成每步的训练样本
上一步中得到的变量data包含了训练集中所有的数据,现在把它转换成训练时使用的batch数据。一个batch可以看作是一些“单词对”的集合,如woman -> man, woman-> fell,箭头左边表示“出现的单词”,右边表示该单词所在的“上下文”中的单词,这是在第14.2.2节中所说的Skip-Gram方法。
制作训练batch的详细程序如下:
# 第三步:定义一个函数,用于生成skip-gram模型用的batch def generate_batch(batch_size, num_skips, skip_window): # data_index相当于一个指针,初始为0 # 每次生成一个batch,data_index就会相应地往后推 global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) span = 2 * skip_window + 1 # [ skip_window target skip_window ] buffer = collections.deque(maxlen=span) # data_index是当前数据开始的位置 # 产生batch后就往后推1位(产生batch) for _ in range(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) for i in range(batch_size // num_skips): # 利用buffer生成batch # buffer是一个长度为 2 * skip_window + 1长度的word list # 一个buffer生成num_skips个数的样本 # print([reverse_dictionary[i] for i in buffer]) target = skip_window # target label at the center of the buffer # targets_to_avoid保证样本不重复 targets_to_avoid = [skip_window] for j in range(num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) targets_to_avoid.append(target) batch[i * num_skips + j] = buffer[skip_window] labels[i * num_skips + j, 0] = buffer[target] buffer.append(data[data_index]) # 每利用buffer生成num_skips个样本,data_index就向后推进一位 data_index = (data_index + 1) % len(data) data_index = (data_index + len(data) - span) % len(data) return batch, labels # 默认情况下skip_window=1, num_skips=2 # 此时就是从连续的3(3 = skip_window*2 + 1)个词中生成2(num_skips)个样本。 # 如连续的三个词['used', 'against', 'early'] # 生成两个样本:against -> used, against -> early batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1) for i in range(8): print(batch[i], reverse_dictionary[batch[i]], '->', labels[i, 0], reverse_dictionary[labels[i, 0]])
尽管代码中已经给出了注释,但为了便于读者理解,还是对这段代码做进一步详细的说明。这里生成一个batch的语句为:batch, labels=generate_batch(batch_size=8,num_skips=2, skip_window=1),每运行一次generate_batch函数,会产生一个batch以及对应的标签labels。注意到该函数有三个参数,batch_size、num_skips和skip_window,下面来说明这三个参数的作用。
参数batch_size应该是最好理解的,它表示一个batch中单词对的个数。generate_batch返回两个值batch和labels,前者表示Skip-Gram方法中“出现的单词”,后者表示“上下文”中的单词,它们的形状分别为(batch_size, )和(batch_size, 1)。
再来看参数num_skips和skip_window。在生成单词对时,会在语料库中先取出一个长度为skip_window*2+1连续单词列表,这个连续的单词列表是上面程序中的变量buffer。buffer中最中间的那个单词是Skip-Gram方法中“出现的单词”,其余skip_window*2个单词是它的“上下文”。会在skip_window*2个单词中随机选取num_skips个单词,放入的标签labels。
如skip_window=1 , num_skips=2的情况。会首先选取一个长度为3的buffer,假设它是['anarchism', 'originated','as'],此时originated为中心单词,剩下的两个单词为它的上下文。再在这两个单词中选择num_skips形成标签。由于num_skips=2,所以实际只能将这两个单词都选上(标签不能重复),最后生成的训练数据为originated ->anarchism和originated -> as。
又如skip_window=3, num_skips=2,会首先选取一个长度为7的buffer,假设是['anarchism', 'originated', 'as','a', 'term', 'of', 'abuse'],此时中心单词为a,再在剩下的单词中随机选取两个,构成单词对。比如选择term和of,那么训练数据是a -> term, a-> of。
由于每一次都是在skip*2个单词中选择num_skips个单词,并且单词不能重复,所以要求skip_window*2>=num_skips。这在程序中也有所体现(对应的语句是assert num_skips <=2 * skip_window)。
在接下来的训练步骤中,每一步都会调用一次generate_batch函数,并用返回的batch和labels作为训练数据进行训练。
定义模型
此处的模型实际可以抽象为:用一个单词预测另一个单词,在输出时,不使用Softmax损失,而使用NCE损失,即再选取一些“噪声词”,作为负样本进行两类分类。对应的定义模型代码为:
# 第四步: 建立模型. batch_size = 128 embedding_size = 128 # 词嵌入空间是128维的。即word2vec中的vec是一个128维的向量 skip_window = 1 # skip_window参数和之前保持一致 num_skips = 2 # num_skips参数和之前保持一致 # 在训练过程中,会对模型进行验证 # 验证的方法就是找出和某个词最近的词。 # 只对前valid_window的词进行验证,因为这些词最常出现 valid_size = 16 # 每次验证16个词 valid_window = 100 # 这16个词是在前100个最常见的词中选出来的 valid_examples = np.random.choice(valid_window, valid_size, replace=False) # 构造损失时选取的噪声词的数量 num_sampled = 64 graph = tf.Graph() with graph.as_default(): # 输入的batch train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) # 用于验证的词 valid_dataset = tf.constant(valid_examples, dtype=tf.int32) # 下面采用的某些函数还没有gpu实现,所以我们只在cpu上定义模型 with tf.device('/cpu:0'): # 定义1个embeddings变量,相当于一行存储一个词的embedding embeddings = tf.Variable( tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) # 利用embedding_lookup可以轻松得到一个batch内的所有的词嵌入 embed = tf.nn.embedding_lookup(embeddings, train_inputs) # 创建两个变量用于NCE Loss(即选取噪声词的二分类损失) nce_weights = tf.Variable( tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) # tf.nn.nce_loss会自动选取噪声词,并且形成损失。 # 随机选取num_sampled个噪声词 loss = tf.reduce_mean( tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed, num_sampled=num_sampled, num_classes=vocabulary_size)) # 得到loss后,我们就可以构造优化器了 optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) # 计算词和词的相似度(用于验证) norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm # 找出和验证词的embedding并计算它们和所有单词的相似度 valid_embeddings = tf.nn.embedding_lookup( normalized_embeddings, valid_dataset) similarity = tf.matmul( valid_embeddings, normalized_embeddings, transpose_b=True) # 变量初始化步骤 init = tf.global_variables_initializer()
先定义了一个embeddings变量,这个变量的形状是(vocabulary_size, embedding_size),相当于每一行存了一个单词的嵌入向量。例如,单词id为0的嵌入是embeddings[0, :],单词id为1的嵌入是embeddings[1,:],依此类推。对于输入数据train_inputs,用一个tf.nn.embedding_lookup函数,可以根据embeddings变量将其转换成对应的词嵌入向量embed。对比embed和输入数据的标签train_labels,用tf.nn.nce_loss函数可以直接定义其NCE损失。
另外,在训练模型时,还希望对模型进行验证。此处采取的方法是选出一些“验证单词”,计算在嵌入空间中与其最相近的词。由于直接得到的embeddings矩阵可能在各个维度上有不同的大小,为了使计算的相似度更合理,先对其做一次归一化,用归一化后的normalized_embeddings计算验证词和其他单词的相似度。
执行训练
完成了模型定义后,就可以进行训练了,对应的代码比较简单:
# 第五步:开始训练 num_steps = 100001 with tf.Session(graph=graph) as session: # 初始化变量 init.run() print('Initialized') average_loss = 0 for step in xrange(num_steps): batch_inputs, batch_labels = generate_batch( batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} # 优化一步 _, loss_val = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += loss_val if step % 2000 == 0: if step > 0: average_loss /= 2000 # 2000个batch的平均损失 print('Average loss at step ', step, ': ', average_loss) average_loss = 0 # 每1万步,我们进行一次验证 if step % 10000 == 0: # sim是验证词与所有词之间的相似度 sim = similarity.eval() # 一共有valid_size个验证词 for i in xrange(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8 # 输出最相邻的8个词语 nearest = (-sim[i, :]).argsort()[1:top_k + 1] log_str = 'Nearest to %s:' % valid_word for k in xrange(top_k): close_word = reverse_dictionary[nearest[k]] log_str = '%s %s,' % (log_str, close_word) print(log_str) # final_embeddings是我们最后得到的embedding向量 # 它的形状是[vocabulary_size, embedding_size] # 每一行就代表着对应index词的词嵌入表示 final_embeddings = normalized_embeddings.eval()
每执行1万步,会执行一次验证,即选取一些“验证词”,选取在当前的嵌入空间中,与其距离最近的几个词,并将这些词输出。例如,在网络初始化时(step=0),模型的验证输出为:
Nearest to they: uniformity, aiding, cei, hutcheson, roca, megawati, ginger, celled,
Nearest to would: scores, amp, ethyl, takes, gopher, agni, somalis, ideogram,
Nearest to nine: anglophones, leland, fdi, scavullo, woven, sepp, tonle, allying,
Nearest to three: geschichte, physically, awarded, walden, idm, drift, devries, sure,
Nearest to but: duplicate, marcel, phosphorus, paths, devout, borrowing, zap, schism,
可以发现这些输出完全是随机的,并没有特别的意义。
但训练到10万步时,验证输出变为:
Nearest to they: we, there, he, you, it, she, not, who, Nearest to would: will, can, could, may, must, might, should, to, Nearest to nine: eight, seven, six, five, zero, four, three, circ, Nearest to three: five, four, two, six, seven, eight, thaler, mico, Nearest to but: however, and, although, which, microcebus, while, thaler, or,
此时,embedding空间中的向量表示已经具备了一定含义。例如,和单词that最相近的是which,与many最相似的为some,与its最相似的是their等。这些相似性都是容易理解的。如果增加训练的步数,并且合理调节模型中的参数,还会得到更精确的词嵌入表示。
最终,得到的词嵌入向量为final_embeddings,它是归一化后的词嵌入向量,形状为(vocabulary_size,embedding_size), final_embeddings[0, :]是id为0的单词对应的词嵌入表示,final_embeddings[1, :]是id为1的单词对应的词嵌入表示,依此类推。
可视化
其实,程序得到final_embeddings之后就可以结束了,不过可以更进一步,对词的嵌入空间进行可视化表示。由于之前设定的embedding_size=128,即每个词都被表示为一个128维的向量。虽然没有方法把128维的空间直接画出来,但下面的程序使用了t-SNE方法把128维空间映射到了2维,并画出最常使用的500个词的位置。画出的图片保存为tsne.png文件:
# Step 6: 可视化 # 可视化的图片会保存为“tsne.png” def plot_with_labels(low_dim_embs, labels, filename='tsne.png'): assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings' plt.figure(figsize=(18, 18)) # in inches for i, label in enumerate(labels): x, y = low_dim_embs[i, :] plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.savefig(filename) try: # pylint: disable=g-import-not-at-top from sklearn.manifold import TSNE import matplotlib matplotlib.use('agg') import matplotlib.pyplot as plt # 因为我们的embedding的大小为128维,没有办法直接可视化 # 所以我们用t-SNE方法进行降维 tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000) # 只画出500个词的位置 plot_only = 500 low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :]) labels = [reverse_dictionary[i] for i in xrange(plot_only)] plot_with_labels(low_dim_embs, labels) except ImportError: print('Please install sklearn, matplotlib, and scipy to show embeddings.')
在运行这段代码时,如果是通过ssh连接服务器的方式执行,则可能会出现类似于“RuntimeError: InvalidDISPLAY variable”之类的错误。此时只需要在语句“import matplotlib.pyplot as plt”之前加上下面两条语句即可成功运行:
import matplotlib matplotlib.use('agg') # must be before importing matplotlib.pyplot or pylab
生成的“tsne.jpg”如图14-5所示。
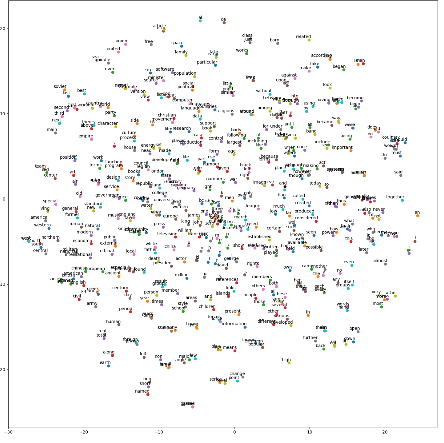
使用t-SNE方法可视化词嵌入
相似词之间的距离比较近。如下图所示为放大后的部分词嵌入分布。

放大后的部分词嵌入分布
很显然,his、her、its、their几个词性相近的词被排在了一起。
除了相似性之外,嵌入空间中还有一些其他的有趣的性质,如图14-7所示,在词嵌入空间中往往可以反映出man-woman, king-queen的对应关系,动词形式的对应关系,国家和首都的对应关系等。

词嵌入空间中的对应关系
在第12章训练Char RNN时,也曾提到对汉字做“embedding”,那么第12章中的embedding和本章中的word2vec有什么区别呢?事实上,不管是在训练CharRNN时,还是在训练word2vec模型,都是加入了一个“词嵌入层”,只不过对象有所不同——一个是汉字,一个是英文单词。这个词嵌入层可以把输入的汉字或英文单词嵌入到一个更稠密的空间中,这有助于模型性能的提升。训练它们的方式有所不同,在第12章中,是采用CharRNN的损失,通过预测下一个时刻的字符来训练模型,“顺带”得到了词嵌入。在本章中,是采用Skip-Gram方法,通过预测单词的上下文来训练词嵌入。
最后,如果要训练一个以单词为输入单位的CharRNN(即模型的每一步的输入都是单词,输入的每一步也是单词,而不是字母),那么可以用本章中训练得到的词嵌入作为要训练的Char RNN的词嵌入层的初始值,这样做可以大大提高收敛速度。对于汉字或是汉字词语,也可以采取类似的方法。
我把整个代码放在这里
# coding: utf-8 # Copyright 2015 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== """Basic word2vec example.""" # 导入一些需要的库 # from __future__ import absolute_import # from __future__ import division # from __future__ import print_function import collections import math import os import random import zipfile import numpy as np from six.moves import urllib from six.moves import xrange # pylint: disable=redefined-builtin import tensorflow as tf # 第一步: 在下面这个地址下载语料库 url = 'http://mattmahoney.net/dc/' def maybe_download(filename, expected_bytes): """ 这个函数的功能是: 如果filename不存在,就在上面的地址下载它。 如果filename存在,就跳过下载。 最终会检查文字的字节数是否和expected_bytes相同。 """ if not os.path.exists(filename): print('start downloading...') filename, _ = urllib.request.urlretrieve(url + filename, filename) statinfo = os.stat(filename) if statinfo.st_size == expected_bytes: print('Found and verified', filename) else: print(statinfo.st_size) raise Exception( 'Failed to verify ' + filename + '. Can you get to it with a browser?') return filename # 下载语料库text8.zip并验证下载 filename = maybe_download('text8.zip', 31344016) # 将语料库解压,并转换成一个word的list def read_data(filename): """ 这个函数的功能是: 将下载好的zip文件解压并读取为word的list """ with zipfile.ZipFile(filename) as f: data = tf.compat.as_str(f.read(f.namelist()[0])).split() return data vocabulary = read_data(filename) print('Data size', len(vocabulary)) # 总长度为1700万左右 # 输出前100个词。 print(vocabulary[0:100]) # 第二步: 制作一个词表,将不常见的词变成一个UNK标识符 # 词表的大小为5万(即我们只考虑最常出现的5万个词) vocabulary_size = 50000 def build_dataset(words, n_words): """ 函数功能:将原始的单词表示变成index """ count = [['UNK', -1]] count.extend(collections.Counter(words).most_common(n_words - 1)) dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) data = list() unk_count = 0 for word in words: if word in dictionary: index = dictionary[word] else: index = 0 # UNK的index为0 unk_count += 1 data.append(index) count[0][1] = unk_count reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reversed_dictionary data, count, dictionary, reverse_dictionary = build_dataset(vocabulary, vocabulary_size) del vocabulary # 删除已节省内存 # 输出最常出现的5个单词 print('Most common words (+UNK)', count[:5]) # 输出转换后的数据库data,和原来的单词(前10个) print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]]) # 我们下面就使用data来制作训练集 data_index = 0 # 第三步:定义一个函数,用于生成skip-gram模型用的batch def generate_batch(batch_size, num_skips, skip_window): # data_index相当于一个指针,初始为0 # 每次生成一个batch,data_index就会相应地往后推 global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) span = 2 * skip_window + 1 # [ skip_window target skip_window ] buffer = collections.deque(maxlen=span) # data_index是当前数据开始的位置 # 产生batch后就往后推1位(产生batch) for _ in range(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) for i in range(batch_size // num_skips): # 利用buffer生成batch # buffer是一个长度为 2 * skip_window + 1长度的word list # 一个buffer生成num_skips个数的样本 # print([reverse_dictionary[i] for i in buffer]) target = skip_window # target label at the center of the buffer # targets_to_avoid保证样本不重复 targets_to_avoid = [skip_window] for j in range(num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) targets_to_avoid.append(target) batch[i * num_skips + j] = buffer[skip_window] labels[i * num_skips + j, 0] = buffer[target] buffer.append(data[data_index]) # 每利用buffer生成num_skips个样本,data_index就向后推进一位 data_index = (data_index + 1) % len(data) data_index = (data_index + len(data) - span) % len(data) return batch, labels # 默认情况下skip_window=1, num_skips=2 # 此时就是从连续的3(3 = skip_window*2 + 1)个词中生成2(num_skips)个样本。 # 如连续的三个词['used', 'against', 'early'] # 生成两个样本:against -> used, against -> early batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1) for i in range(8): print(batch[i], reverse_dictionary[batch[i]], '->', labels[i, 0], reverse_dictionary[labels[i, 0]]) # 第四步: 建立模型. batch_size = 128 embedding_size = 128 # 词嵌入空间是128维的。即word2vec中的vec是一个128维的向量 skip_window = 1 # skip_window参数和之前保持一致 num_skips = 2 # num_skips参数和之前保持一致 # 在训练过程中,会对模型进行验证 # 验证的方法就是找出和某个词最近的词。 # 只对前valid_window的词进行验证,因为这些词最常出现 valid_size = 16 # 每次验证16个词 valid_window = 100 # 这16个词是在前100个最常见的词中选出来的 valid_examples = np.random.choice(valid_window, valid_size, replace=False) # 构造损失时选取的噪声词的数量 num_sampled = 64 graph = tf.Graph() with graph.as_default(): # 输入的batch train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) # 用于验证的词 valid_dataset = tf.constant(valid_examples, dtype=tf.int32) # 下面采用的某些函数还没有gpu实现,所以我们只在cpu上定义模型 with tf.device('/cpu:0'): # 定义1个embeddings变量,相当于一行存储一个词的embedding embeddings = tf.Variable( tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) # 利用embedding_lookup可以轻松得到一个batch内的所有的词嵌入 embed = tf.nn.embedding_lookup(embeddings, train_inputs) # 创建两个变量用于NCE Loss(即选取噪声词的二分类损失) nce_weights = tf.Variable( tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) # tf.nn.nce_loss会自动选取噪声词,并且形成损失。 # 随机选取num_sampled个噪声词 loss = tf.reduce_mean( tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed, num_sampled=num_sampled, num_classes=vocabulary_size)) # 得到loss后,我们就可以构造优化器了 optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) # 计算词和词的相似度(用于验证) norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm # 找出和验证词的embedding并计算它们和所有单词的相似度 valid_embeddings = tf.nn.embedding_lookup( normalized_embeddings, valid_dataset) similarity = tf.matmul( valid_embeddings, normalized_embeddings, transpose_b=True) # 变量初始化步骤 init = tf.global_variables_initializer() # 第五步:开始训练 num_steps = 100001 with tf.Session(graph=graph) as session: # 初始化变量 init.run() print('Initialized') average_loss = 0 for step in xrange(num_steps): batch_inputs, batch_labels = generate_batch( batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} # 优化一步 _, loss_val = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += loss_val if step % 2000 == 0: if step > 0: average_loss /= 2000 # 2000个batch的平均损失 print('Average loss at step ', step, ': ', average_loss) average_loss = 0 # 每1万步,我们进行一次验证 if step % 10000 == 0: # sim是验证词与所有词之间的相似度 sim = similarity.eval() # 一共有valid_size个验证词 for i in xrange(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8 # 输出最相邻的8个词语 nearest = (-sim[i, :]).argsort()[1:top_k + 1] log_str = 'Nearest to %s:' % valid_word for k in xrange(top_k): close_word = reverse_dictionary[nearest[k]] log_str = '%s %s,' % (log_str, close_word) print(log_str) # final_embeddings是我们最后得到的embedding向量 # 它的形状是[vocabulary_size, embedding_size] # 每一行就代表着对应index词的词嵌入表示 final_embeddings = normalized_embeddings.eval() # Step 6: 可视化 # 可视化的图片会保存为“tsne.png” def plot_with_labels(low_dim_embs, labels, filename='tsne.png'): assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings' plt.figure(figsize=(18, 18)) # in inches for i, label in enumerate(labels): x, y = low_dim_embs[i, :] plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.savefig(filename) try: # pylint: disable=g-import-not-at-top from sklearn.manifold import TSNE import matplotlib matplotlib.use('agg') # must be before importing matplotlib.pyplot or pylab import matplotlib.pyplot as plt # 因为我们的embedding的大小为128维,没有办法直接可视化 # 所以我们用t-SNE方法进行降维 tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000) # 只画出500个词的位置 plot_only = 500 low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :]) labels = [reverse_dictionary[i] for i in xrange(plot_only)] plot_with_labels(low_dim_embs, labels) except ImportError: print('Please install sklearn, matplotlib, and scipy to show embeddings.')
参考
论文《Efficient Estimation of WordRepresentations in Vector Space》CBOW模型和Skip-Gram模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号