论文翻译:2015_DNN-Based Speech Bandwidth Expansion and Adding High-Frequency Missing Features Narrowband Speech
论文地址:基于DNN的语音带宽扩展和添加高频缺失特征窄带语音
论文代码:github
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/12361112.html
摘要
我们提出了一些增强技术来提高从窄带到宽带扩频(BWE)中的语音质量,解决了三个在实际应用中可能非常关键的问题,即:
- 窄带频谱和估计的高频频谱之间的不连续性,
- 测试和训练话语之间的能量不匹配,
- 扩展 域外语音信号(其他类型的语音) 的带宽。
通过带宽扩展语音中高频特征缺失的固有预测,我们还探讨了在窄带语音中加入这些估计特征的可行性,以提高窄带语音自动识别(ASR)的系统性能。利用最近提出的一种基于深度神经网络的语音BWE系统,该技术不仅改进了传统的主客观测量方法,而且将窄带语音识别的误字率从8.67%降低到8.26%在20000字的《华尔街日报》(Wall Street Journal)开放词汇ASR任务中,宽带扩展语音识别率接近8.12%。
索引词:深度神经网络,语音带宽扩展,自动语音识别
1 引言
语音带宽从窄带扩展到宽带的研究已有几十年[1,2,3,4],目的是提高窄带语音的收听质量,如现有的公共交换电话网(PSTN)的收听质量[5,6]。即使现在用于语音传输的带宽不再受到严格的限制,我们仍然有大量的设备来传输和接收窄带语音。例如,大多数蓝牙耳机[7]仍在窄带语音。因此,将语音带宽从窄带(带宽为4khz)扩展到宽带(带宽为8khz或更高)仍将有益于我们的日常生活。
另一方面,人不是交流所涉及的唯一目标,人类投入了大量的研究和工程努力在人机界面(HCI)系统(8、9、10)中,口语对话系统[11,12,13]能够理解自然的人类语言并做出反应。因此,如果带宽扩展可以提高人和计算机的语音清晰度,同时基于窄带信道的计算机辅助系统可以提供更好的用户体验,不仅可以提高语音质量,还可以提高自动语音识别(ASR)的潜在精度[14,15,16] 。
传统的带宽扩展通常侧重于估计高频频带的频谱包络和低频频带的激励来恢复高频频谱[17,18,19,20]。最近的一些研究也表明,直接估算高频频谱是可行的[21,22]。我们之前的工作[23]表明,基于DNN的BWE可以在这种情况下工作得很好。然而,存在一个叫做谱不连续的问题。在[24]中,通过旋转窄带频谱的端点并平滑高频分量来拟合它,解决了类似的问题。
1、窄带频谱和估计的高频频谱之间的不连续性:
我们建议联合估计整个宽带频谱,而不是仅仅预测高频频谱,因为我们观察到DNN在大多数基于DNN的回归任务中会固有地产生平滑的输出。结果发现,与传统的想法相反,DNN框架可以消除窄带和高频谱之间的过度不连续性,它还可以减小预测的宽带信号的窄带谱和估计的低频谱之间的差异。
2、BWE的另一个关键问题是测试和训练话语之间的能量不匹配:
语音活动检测(VAD[25, 26])和语音能量调节在一定程度上有帮助。
3、如何扩展 训练语音数据以外的 语音数据:
利用倒谱系数的低频成分能够表征给定语音[27]的平均能量特性,我们还建议将它们加入到DNN训练中。结果发现,这种方法训练的DNN可以较好地解决测试话语超出域的问题(BWE测试中使用的测试话语在声学上可能与基于DNN的BWE训练中使用的话语有很大不同)。
3、如何扩展域外语音的带宽:
为了扩展域外语音的带宽,还需要解决信道失配问题。在我们的实验中,我们发现话语归一化可以减少一些由偏置向量在对数谱域中建模的信道失配。
通过预测DNN训练中的整个宽带频谱,在DNN训练中加入倒谱(cesptral)特征,以及话语归一化,这三种改进技术比我们最近提出的基于DNN的BWE系统[23]有了很大的改进,我们的实验结果表明,这三种改进技术能够解决提高人类听力质量的三个关键问题,即:(1)窄带谱和估计的高频谱之间的不连续性;(2)测试和训练语句之间的能量不匹配;(3)扩展域外语音信号带宽的能力。增强的BWE语音信号的质量在主观和客观测试中都表现出良好的性能。
此外,为了提高语音识别系统的识别精度,我们还探讨了在已有的窄带语音基础上增加附加高频频谱的语音特征的可行性。我们对《华尔街日报》20000字开放词汇量任务的ASR进行的初步实验证实,如果系统基于相同的体系结构和训练策略,宽带语音的错误率(WER)为8.12%,可以始终优于窄带语音,WER为8.67%。尽管如此,在扩频语音上使用相同的设计,其功耗为8.26%,与宽带语音的性能接近。这一令人鼓舞的结果将激励我们在未来的工作中探索新的算法来估计丢失的高频谱中的额外语音特征,以便利用现有的许多窄带语音语料库,甚至将它们与现有的宽带语音数据库相结合,以进一步提高ASR性能。
2 基于DNN的频带扩展
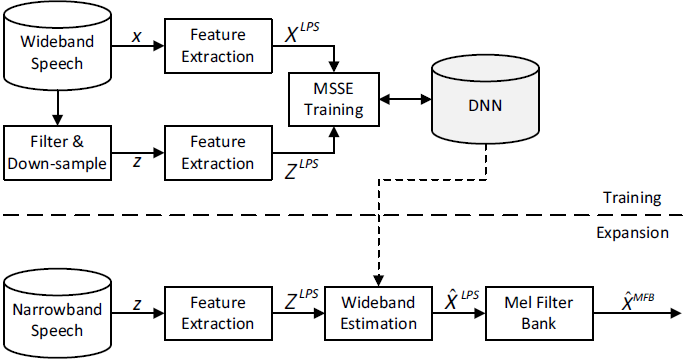
图1:DNN-BWE模块的框图
2.1 特征提取
在我们最近的工作[23]中,提出了一个基于DNN的BWE系统。虽然客观和主观的表现都很好,但当使用对数功率谱(LPS)作为特征时,预测高频带参数常常会导致低频(0~ 4khz)到高频(4~ 8khz)之间的过渡点出现不连续问题。为了减少这个问题,一种可能的补救方法是通过补偿能量间隙来平滑这些转换处的语音参数。我们最近的实验表明,一个基于DNN的BWE系统可以预测整个宽带频谱,而不仅仅是缺失的高频频段。通过这样做,它将导致预测的低频带和原始窄带之间的轻微不匹配,这通常在语谱图中很难注意到,但在使用客观测量时会暴露出来。
对于BWE,窄带信号的LPS $Z^{LPS}$和宽带信号的LPS $X^{LPS}$被用作DNN的输入和输出特征,并在输入DNN之前对其进行归一化[28](均值为0,方差为1)。设$\mu_n$和$\mu_w$为训练数据的LPS特征向量,$\sum_n$和$\sum_w$为各特征维上对应的方差。然后输入特征为$(Z^{LPS}-\mu_n)*\sum_n^{-1}$,DNN的输出为$Y$,估计的宽带LPS$X^{\hat{}}$的输出遵循以下关系:
$$公式1:\hat{X}^{\mathrm{LPS}}=Y \cdot \Sigma_{w}+\mu_{w}$$
最近的一些研究表明,Mel-filter bank的[29]特性在基于DNN的ASR系统中表现良好。此外,我们可以很容易地将LPS转换为对数Mel-filter bank特性,如下所示
$$公式2:X^{\mathrm{MFB}}=\ln \left[\exp \left(X^{\mathrm{LPS}}\right) \times F\right]$$
其中$X^{LPS}$为N维宽带LPS特征向量,F为带K个滤波器bin的Mel-filter bank的$N*K$矩阵。对于窄带信号及其相应的Mel filter特征$Z^{MFB}$,由于其频率范围和bin数目不同,通常窄带信号的bins较少,因此所用的滤波器组矩阵与宽带信号的滤波器组矩阵不同。滤波器箱的数量是通过确保窄带信号具有与宽带信号滤波器箱最相似的滤波器箱来确定的。
2.2 DNN训练

图2:DNN-BWE结构与训练
我们使用Kaldi工具包[28]来训练DNN。首先对受限玻尔兹曼机(RBM)进行无监督预训练[30]。然后,在判别微调中,使用最小平方和误差(MSSE[31])准则,试图最小化预测宽带特征和期望宽带信号的真实宽带特征之间的欧氏距离。设$[Y;R]$为DNN的输出,其中R是一些用于正则化的额外输出向量,将从最终输出Y截断,目标函数为
$$公式3:\begin{aligned} \min & \frac{1}{2}\left\|\left(X^{\mathrm{LPS}}-\mu_{w}\right) \Sigma_{w}^{-1}-Y\right\|_{2}^{2}+\\ & \frac{\rho}{2}\left\|f\left(X^{\mathrm{LPS}}\right)-R\right\|_{2}^{2}+\frac{\gamma}{2}\left(\|Y\|_{2}^{2}+\|R\|_{2}^{2}\right) \end{aligned}$$
其中$\rho $是惩罚因子,第三项是整个输出向量的L2损失,但在这项工作γ被设置为0。$f(\cdot)$可以是任何函数,如果$f(X^{LPS})$不是BWE的目标,则为多任务学习[32]。这里我们在第二项中使用了倒谱的下半部分,即$f(\cdot)$正在进行离散余弦变换(DCT),并放弃了上半部分的参数。这样可以更好地处理输入窄带信号与训练数据有较大偏差时可能出现的能量不匹配问题。
3 基于BWE语音的语音识别
本文所采用的ASR声学模型也是前馈DNNs[33]。首先将窄带信号的频谱通过基于DNN的BWE系统得到估计的宽带谱,然后利用估计的宽带谱提取特征向量(log Mel filter bank),将其输入到用于ASR的DNN声学模型中。
在典型的DNN声学模型设置中,隐含层通常由sigmoid单元构成,输出层为softmax层,直接建模依赖依赖于上下文的三音状态,有时也称为senones[34]。通过最大化训练框架上的对数后验概率来训练DNN。这等价于最小化交叉熵目标函数。设$X$为整个训练集,其中包含T帧,即$o^{1:T}\in X$,则相对于x的损失为
$$公式4:\mathcal{L}^{1: T}=-\sum_{t=1}^{T} \sum_{j=1}^{J} \tilde{\mathbf{p}}^{t}(j) \log p\left(C_{j} | \mathbf{o}^{t}\right)$$
其中$p(C_j|o^t)$是senone $j$的后验概率,$\tilde{p}^t$是第$t$帧的目标概率。在DNN系统的实际应用中,目标概率$\tilde{p}^t$通常是通过与现有系统进行强制对齐而获得的,结果是目标条目等于1。利用小批次随机梯度下降法(SGD)[35]对训练过程中所有神经参数进行更新,该方法通过合理的小批次大小使所有的矩阵都适合GPU内存。采用预训练方法初始化DNN参数。
4 实验和结果分析
4.1 实验步骤
我们在华尔街日报(WSJ0)语料库[36]上进行了实验,麦克风语音以16位 分辨率16 kHz采样,而交换机(SWB1)语料库[37]以16位 分辨率8 kHz采样。训练集中有31166个话语的WSJ0(约50小时训练,10小时验证)被用来训练BWE模型。在宽带信号上,STFT的窗口大小为400个样本,帧移为160个样本,而窄带信号的窗口大小为200个样本,增益为80个样本。特征提取采用汉明窗。宽带信号的Mel-filter bank有29个bin,范围从0 Hz到8000 Hz,前22个bin的范围从0 Hz到4132 Hz。窄带特征提取了覆盖0 Hz到4000 Hz频率范围的22个滤波器组bin的系数。将MSSE训练的基本学习率设置为$10^{-5}$,采用newbob方法[38],当均方误差减小小于0.25%时学习率减半,当均方误差减小小于0.25时停止。采用小批量训练[39],批量大小32个话语,动量(momentum)率0.9。
在《华尔街日报》20k开放词汇表任务的ASR实验中,使用WSJ0材料(SI-84)训练DNN声学模型。使用WSJ0标准适配集(si et ad, 8个说话者,每个说话者40个句子)对添加到与说话者无关的DNN中的仿射变换进行适配。使用标准开放词汇量2万字(20k) 阅读 NVP Senneheiser麦克风(si_et_20, 8个说话者* 40个句子)数据进行评估。解码过程中采用了标准的三源语言模型。ASR的性能是根据单词错误率(WER)给出的。
4.2 基于DNN的BWE模型的客观评价
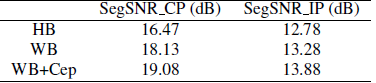
我们采用了[23,40]中的DNN结构设置,在输入端有11帧,每层有3个隐藏层,每层有2048个隐藏节点。这里的11帧表示将5个前帧和5个后帧与当前帧连接在一起,以输入DNNs层。客观的测量方法是对数谱失真(LSD)[41]和以[23]为例的分段信噪比(segmental signal-tonoise ratio, segmental snr)[42]。结果如表1和表2所示,其中$LSD_H$为高频频谱的LSD, HB表示DNN仅训练为预测高频参数,WB表示DNN将预测整个宽带参数,WB+Cep表示DNN同时学习LPS和倒谱参数。
表1左列的LSD结果表明,当训练DNN预测整个宽带参数(WB)时,它可以减少将宽带信号的窄带谱和低频谱之间的总体差别(从HB得到的6.13dB降低到5.45dB),而造成这种差异的原因可能是用于从宽带信号生成窄带信号的信道(模拟为低通滤波器或带通滤波器)。此外,学习倒谱和LPS参数(WB+Cep)进一步将LSD降低到5.42db。对于表1右栏的LSDH(高频LSD)结果也可以得出类似的结论。
此外,如表2所示,所提出的WB+Cep DNN训练策略在SegSRN上取得了比WB(本研究中提出的)和HB(在[23]中提出的)更大的增益,仅给出了宽带信号的实际相位(CP)和窄带信号(在[23]中IP)的高频imaged相位的重构信号。很明显,左柱的CP值提高了0.95分贝(从18.13分贝提高到19.08分贝)。即使在右栏的IP情况下,当相位没有被重新估计时,我们仍然获得0.6db的增益(从13.28到13.88db)。
表1:华尔街日报测试集的LSD
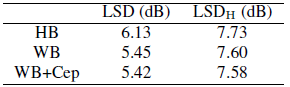
表2:WSJ测试集的SegSNR
4.3 域外数据集的主观测试
DNN模型具有很强的学习能力和鲁棒性。这促使我们测试域外窄带语音。我们用来训练BWE系统的数据集是相对干净和稳定的WSJ0,我们选择交叉测试系统的数据集是相对困难的SWB集,它可能包含有回声的语音以外的其他语音,有时还包含多个扬声器。为了减少信道失配,如果我们使用失配数据集进行训练和测试,这可能是最重要的问题,在这种情况下,在话语级别执行归一化,每个话语将有自己的$\mu_n^i$和$\sum_n^i$进行规范化。
我们还对训练数据进行了话语水平归一化,并使用新的特征对DNN进行了重新训练,但DNN结构相同。由于SWB数据是真实的窄带语音,带宽仅为3.4khz,因此我们建立了3.5khz~7khz的BWE系统,并对其特征维数进行了相应的修正。另一方面,SWB语句没有$\mu_w$和$\sum_w$,没有$\mu_w$和$\sum_w$就不容易重建LPS和波形。这里我们借用了《华尔街日报》的数据估算出的$\mu_w$和$\sum_w$,并分别对它们应用了$b_i$和$s_i$。假设$\mu_{wn}$是$\mu_w$的低频部分,$\sum_{wn}$是$\sum_w$的低频部分,那么
$$公式5:b_{i}=\overline{\mu_{n}^{i}-\mu_{w n}}$$
$$公式6:s_{i}=\left|\Sigma_{n}^{i} \cdot \Sigma_{w n}^{-1}\right|^{\frac{1}{M}}$$
其中$i$是话语的索引,$\bar{\cdot}$给出向量所有项的平均值,$|\cdot|$是决定因素,M为窄带特征向量的维数。在此基础上,采用窄带相位(IP)的[23]方法重建了听力测试的波形。
图3显示了一个SWB语句示例。如果只使用全局归一化(右上角),估计的高频频谱清晰度较低,能量较少,椭圆区域出现多帧高频缺失,这可能是由于DNN没有找到对应的模式造成的。如果使用话语水平归一化(左下面板),高频频谱中有更多的能量,但矩形区域显示噪声被扩展为一个辅音。我们认为这主要是由于能量不匹配,训练数据在相同的能量水平上没有噪音(非语音声音)。所提出的声谱图在所有声音上都有很好的表现,使声谱图更加清晰和准确。
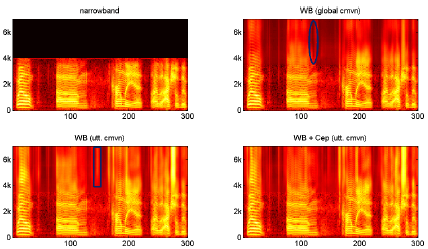
图3:SWB语音示例的频谱图:左上原始窄带语音、右上bBWE语音(具有全局规范化)、左下BWE语音(使用语音归一化)和右下BWE语音(使用语音归一化和倒谱多任务学习)。
我们邀请了乔治亚理工学院的男女学生到我们的实验室来测试他们对带宽扩展语音的偏好。没有一个志愿者在BWE工作。随机选择SWB测试集1%的子集,每个志愿者听从1%子集中随机选择的10个序列。在偏好测试中,一次给志愿者两个平行的序列,而没有有关序列的其他信息,并要求他们选择他们偏好的一个或无偏好(N / P)。结果如表3所示,在大多数情况下,带宽扩展序列比其他两种选择具有更好的质量(几乎90%)和更高的清晰度。只有在少数情况下,当志愿者更喜欢窄带语音时,才会被描述为噪音更小或声音更柔和。
表3:SWB偏好测试

4.4 《华尔街日报》20000字开放词汇任务中的ASR
最后,我们利用WSJ0材料(SI-84)对DNN声学模型进行了初步的ASR测试。利用Kaldi toolkit[28]分别对原始宽带语音、只有宽带语音的低频频谱(0~ 4khz)的窄带语音和由窄带语音扩展而来的语音带宽(4.2中的WB)分别训练ASR系统的基于DNN的声学模型。然后使用三个模型对测试集上的语音进行解码,单词错误率如表4所示。原始宽带语音的执话率为8.12%,窄带语音的执话率为8.67%,相对于原始宽带语音的执话率降低了6.8%,而BWE语音的执话率为8.26%,相对于窄带语音的执话率降低了4.7%,相对于原始宽带语音的执话率降低了1.7%。
表4:WER来自20k单词开放词汇《华尔街日报》ASR任务的宽带、宽带和窄带语音训练数据。

5 总结和未来工作
为了提高BWE在听觉质量和语音识别方面的性能,本文提出了一种基于DNN的BWE框架。为了解决以往工作中出现的频谱不连续问题,提高系统在能量失配和信道失配情况下的性能,我们探索了三种新的技术。实验结果表明,客观测量对域内测试话语有显著的改善,对域外窄带话语的主观听力测试进一步证实了系统在实际应用中的性能提高。初步的ASR实验表明,BWE技术可以提高窄带语音的识别性能。未来的工作将集中于迁移BWE增强的ASR框架,以通过额外的通道匹配和规范化来处理实际世界中的域数据集。
6 参考文献
[1] J. Epps and W. H. Holmes, A new technique for wideband enhancement of coded narrowband speech, in Proc. IEEE Workshop on Speech Coding, 1999, pp. 174 176.
[2] S. Vaseghi, E. Zavarehei, and Q. Yan, Speech bandwidth extension: extrapolations of spectral envelop and harmonicity quality of excitation, in Proc. ICASSP, vol. 3, 2006.
[3] J. Han, G. J. Mysore, and B. Pardo, Language informed bandwidth expansion, in Proc. IEEE Workshop on Machine Learning for Signal Processing, 2012, pp. 1 6.
[4] H. Seo, H.-G. Kang, and F. Soong, A maximum a posterior-based reconstruction approach to speech bandwidth expansion in noise, in Proc. ICASSP, 2014, pp. 6087 6091.
[5] L. A. Litteral, J. B. Gold, D. C. Klika Jr, D. B. Konkle, C. D. Coddington, J. M. McHenry, and A. A. Richard III, PSTN architecture for video-on-demand services, 1993, US Patent 5,247,347.
[6] C. Marvin, When old technologies were new. Oxford University Press, 1997.
[7] J. C. Haartsen and E. Radio, The bluetooth radio system, in IEEE Personal Communications, 2000.
[8] B. Laurel and S. J. Mountford, The art of human-computer interface design. Addison-Wesley Longman Publishing Co., Inc., 1990.
[9] B. Shneiderman, Designing the user interface: strategies for effective human-computer interaction. Addison-Wesley Reading, MA, 1992, vol. 2.
[10] R. Sharma, V. Pavlovic, and T. S. Huang, Toward multimodal human-computer interface, Proc. of the IEEE, vol. 86, no. 5, pp. 853 869, 1998.
[11] V. Zue, S. Seneff, J. R. Glass, J. Polifroni, C. Pao, T. J. Hazen, and L. Hetherington, JUPlTER: a telephone-based conversational interface for weather information, IEEE Trans. Speech Audio Process., vol. 8, no. 1, pp. 85 96, 2000.
[12] J. D. Williams and S. Young, Partially observable Markov decision processes for spoken dialog systems, Computer Speech & Language, vol. 21, no. 2, pp. 393 422, 2007.
[13] R. Pieraccini and J. Huerta, Where do we go from here? research and commercial spoken dialog systems, in 6th SIGdial Workshop on Discourse and Dialogue, 2005.
[14] S. E. Levinson, L. R. Rabiner, and M. M. Sondhi, An introduction to the application of the theory of probabilistic functions of a Markov process to automatic speech recognition, The Bell System Technical Journal, vol. 62, no. 4, pp. 1035 1074, 1983.
[15] C.-H. Lee, F. K. Soong, and K. K. Paliwal, Automatic speech and speaker recognition: advanced topics. Springer Science & Business Media, 1996, vol. 355.
[16] C. Weng, D. Yu, S. Watanabe, and B.-H. F. Juang, Recurrent deep neural networks for robust speech recognition, in Proc. ICASSP, 2014, pp. 5532 5536.
[17] B. Iser and G. Schmidt, Bandwidth extension of telephony speech, in Speech and Audio Processing in Adverse Environments. Springer, 2008, pp. 135 184.
[18] Y. Nakatoh, M. Tsushima, and T. Norimatsu, Generation of broadband speech from narrowband speech based on linear mapping, Electronics and Communications in Japan (Part II: Electronics), vol. 85, no. 8, pp. 44 53, 2002.
[19] K.-Y. Park and H. S. Kim, Narrowband to wideband conversion of speech using GMM based transformation, in Proc. ICASSP, vol. 3, 2000, pp. 1843 1846.
[20] G.-B. Song and P. Martynovich, A study of HMM-based bandwidth extension of speech signals, Signal Processing, vol. 89, no. 10, pp. 2036 2044, 2009. [21] K. Kalgaonkar and M. A. Clements, Sparse probabilistic state mapping and its application to speech bandwidth expansion, in Proc. ICASSP, 2009, pp. 4005 4008.
[22] H. Seo, H.-G. Kang, and F. Soong, A maximum a posterior-based reconstruction approach to speech bandwidth expansion in noise, in Proc. ICASSP, 2014, pp. 6087 6091.
[23] K. Li and C.-H. Lee, A deep neural network approach to speech bandwidth expansion, in Proc. ICASSP, 2015.
[24] B. Iser and G. Schmidt, Neural networks versus codebooks in an application for bandwidth extension of speech signals, in Proc. INTERSPEECH, 2003, pp. 565 568.
[25] J. Ramirez, J. M. G orriz, and J. C. Segura, Voice activity detection: Fundamentals and speech recognition system robustness. INTECH Open Access Publisher, 2007.
[26] S. Morita, M. Unoki, X. Lu, and M. Akagi, Robust voice activity detection based on concept of modulation transfer function in noisy reverberant environments, in Chinese Spoken Language Processing (ISCSLP), 9th International Symposium on, 2014, pp. 560 564.
[27] O. Viikki and K. Laurila, Cepstral domain segmental feature vector normalization for noise robust speech recognition, Speech Communication, vol. 25, no. 1, pp. 133 147, 1998.
[28] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., The Kaldi speech recognition toolkit, in Proc. ASRU, 2011, pp. 1 4.
[29] S. Molau, M. Pitz, R. Schluter, and H. Ney, Computing melfrequency cepstral coefficients on the power spectrum, in Proc. ICASSP, vol. 1, 2001, pp. 73 76.
[30] D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, A learning algorithm for Boltzmann machines, Cognitive Science, vol. 9, no. 1, pp. 147 169, 1985.
[31] D. M. Allen, Mean square error of prediction as a criterion for selecting variables, Technometrics, vol. 13, no. 3, pp. 469 475, 1971.
[32] R. Caruna, Multitask learning: A knowledge-based source of inductive bias, in Proc. ICML, 1993, pp. 41 48.
[33] G. E. Dahl, D. Yu, L. Deng, and A. Acero, Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition, IEEE Trans. Audio, Speech, and Lang. Process., vol. 20, no. 1, pp. 30 42, 2012.
[34] M.-Y. Hwang and X. Huang, Shared-distribution hidden Markov models for speech recognition, IEEE Trans. Speech Audio Process., vol. 1, no. 4, pp. 414 420, 1993.
[35] O. Dekel, R. Gilad-Bachrach, O. Shamir, and L. Xiao, Optimal distributed online prediction, in Proc. ICML, 2011, pp. 713 720.
[36] D. B. Paul and J. M. Baker, The design for the Wall Street Journal-based CSR corpus, in HLT 91 Proceedings of the workshop on Speech and Natural Language, 1992, pp. 357 362.
[37] J. J. Godfrey and E. Holliman, Switchboard-1 release 2, Linguistic Data Consortium, Philadelphia, 1997.
[38] ICSI QuickNet toolbox. Newbob approach is implemented in the toolbox. [Online]. Available: http://www1.icsi.berkeley.edu/Speech/qn.html
[39] G. E. Hinton, A practical guide to training restricted Boltzmann machines, Dept. Comput. Sci., Univ. Toronto, Tech. Rep. UTML TR 2010 003, 2010.
[40] Y. Xu, J. Du, L. Dai, and C.-H. Lee, An experimental study on speech enhancement based on deep neural networks, IEEE Signal Process. Lett., pp. 65 68, 2014.
[41] I. Cohen and S. Gannot, Spectral enhancement methods, in Springer Handbook of Speech Processing. Springer, 2008, pp. 873 902.
[42] S. R. Quackenbush, T. P. Barnwell, and M. A. Clements, Objective measures of speech quality. Prentice Hall Englewood Cliffs, NJ, 1988.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号