论文翻译:2000_narrowband to wideband conversion of speech using GMM based transformation
论文地址:基于GMM的语音窄带到宽带转换
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/12151027.html
摘要
在不改变现有通信网络的情况下,利用窄带语音重建宽带语音是一个很有吸引力的问题。本文提出了一种从窄带语音中恢复宽带语音的新方法。该方法基于高斯混合模型(GMM)将输入语音的窄带频谱包络变换为宽带频谱包络,并采用联合密度估计技术对其参数进行计算。然后利用重构后的谱包络,利用LPC合成器对低频和高频语音信号进行重构。本文还提出了一种基于码字的功率估计方法。客观和主观测试结果均表明,该算法优于传统的码本映射方法。
1 引言
在模拟电话网络和移动通信系统中,语音带宽限制在300Hz - 3.4 kHz范围内。结果,窄带语音的音质不如宽带语音,特别是辅音的可懂度降低。由于人类对宽带语音的偏好,将窄带语音改造成宽带语音显得很有吸引力。
窄带到宽带(NB到WB)语音转换的目的是从窄带语音中重建附加的低频(20hz-300hz)和高频(3.4khz-8khz)信号。重建基于两个假设[1]。一是窄带语音与高、低频段信号密切相关。二是即使重构的低频段和高频段信号不完全准确,也能显著提高感知语音质量。NB到WB语音转换的最大优点是,它在不需要任何额外传输信息的情况下生成增强的宽带语音(盲源频带扩展),从而为现有网络提供向后兼容性。
本文对NB到WB语音转换问题进行了一些尝试,包括基于codebook mapping (码本映射)[1]的方法和统计方法[2]。其主要问题是宽带频谱包络的重构。在码本映射方法中,声学空间由一组离散的模板codevector(码矢)表示。利用窄带码本和宽带码本之间的映射关系重构宽带频谱包络。该方法的局限性在于矢量量化(VQ)过程中对输入窄带谱向量的硬分类,虽然模糊VQ在一定程度上缓解了这一问题[1]。统计方法引入了统计恢复函数(SRF),它只预测基于窄带语音的高频段频谱。虽然统计方法获得了良好的性能,但它需要大量的计算。
众所周知,高斯混合模型(GMM)[3]能有力的表示语音的声学空间,并被成功地用作频谱变换的方法,特别是在说话人转换系统[4][5]中。由于声学空间的连续逼近,GMM提供了平滑的分类索引,避免了不自然的不连续性,从而优于VQ模型。因此,该算法将GMM作为宽带频谱包络重建的工具。
本文组织如下。第二部分介绍了基于GMM的NB到WB语音转换算法。第三部分给出了实验结果,最后得出结论。
2 基于GMM的NB到WB语音转换
本文提出了一种基于GMM的窄带语音重建方法。第一种是基于联合密度估计的GMM的频谱包络重构。将窄带谱向量转换为宽带谱向量的映射函数是最小二乘回归估计。最小二乘回归估计,简称回归,是由一对训练语音(窄带和宽带)得到的。第二步是生成低频带和高频带信号。 在本文中,与码本映射方法一样,使用LPC合成器生成低频带和高频带语音信号[1]。
2.1 高斯混合模型(GMM)
设$x\in R^n$为具有任意分布的随机向量。将$x$的分布密度建模为由Q个分量密度混合而成的高斯混合密度,表示为:
$$公式1:
p(x | \lambda)=\sum_{i=1}^{Q} \alpha_{i} b_{i}(x), \sum_{i=1}^{Q} \alpha_{i}=1, \alpha_{i} \geq 0
$$
其中$b_i(x),i=1,...,Q$为分量密度,$\alpha_i,i=1,...,Q$为分量权重。每个分量密度都是一个包含n个变量的高斯函数的形式
$$公式2:
b_{i}(x)=\frac{1}{(2 \pi)^{n / 2}\left|C_{i}\right|^{1 / 2}} \exp \left[-\frac{1}{2}\left(x-\mu_{i}\right)^{T} C_{i}^{-1}\left(x-\mu_{i}\right)\right]
$$
$\mu_i$为n*1个均值向量,变量$C_i$为n*n各协方差向量。
完整的高斯混合密度由各分量密度的均值向量、协方差矩阵和混合权重 参数化,这些参数用符号表示
$$公式3:
\lambda=\left\{\alpha_{i}, \mu_{i}, C_{i}\right\} \quad, i=1, \cdots, Q
$$
使用GMM来表示声学空间的两个主要的动机:
- 第一个是经验观察,一个高斯base函数的线性组合能够代表一大类样本分布。
- 第二种是直观的概念,即单个成分密度被解释为代表一些广泛的声学类别。
为了对声学空间分布进行建模,必须利用训练语音数据估计GMM的参数。有几种估计GMM参数的技术。最常用的方法是极大似然(ML)估计。ML参数估计可以使用众所周知的期望最大化(EM)算法[3]迭代获得。
2.2 频谱包络重构
2.2.1 联合密度估计的GMM
设$x\in R^n$为窄带语音的谱向量,$y\in R^n$为原宽带语音的谱向量。然后将向量$z=(x,y)$的联合密度建模为Q 2n变量高斯函数的混合。
$$公式4:\begin{array}{l}p(z|\lambda ) = \sum\limits_{i = 1}^Q {\frac{{{\alpha _i}}}{{{{(2\pi )}^n}|{C_i}{|^{1/2}}}}} \exp [ - \frac{1}{2}{(z - {\mu _i})^T}C_i^{ - 1}(z - {\mu _i})]\\\quad \quad \quad \quad \sum\limits_{i = 1}^Q {{\alpha _i}} = 1,{\alpha _i} \ge 0\end{array}$$
其中$\alpha_i$、$\mu_i$和$c_i$表示第$i$类的先验概率、平均向量和协方差矩阵。我们的目标是找到一个使均方误差最小化的映射函数F。
$$公式5:{\varepsilon _{mse}} = E[||y - F(x)|{|^2}]$$
其中$E[·]$表示期望,F(x)为待估计的重构宽带谱向量。
回归函数可以使重构的宽带频谱矢量和原始宽带频谱矢量之间的均方误差最小。
$$公式6:F(x)=E[y|x]=\sum_{i=1}^Qh_i(x)[\mu_i^y+C_i^{yx}C_i^{xx-1}(x-\mu_i^x)]$$
其中
$$公式7:{h_i}(x) = \frac{{\frac{{{\alpha _i}}}{{{{(2\pi )}^{n/2}}{{\left| {C_i^{xx}} \right|}^{1/2}}}}\exp \left[ { - \frac{1}{2}{{\left( {x - \mu _i^x} \right)}^T}C_i^{xx - 1}\left( {x - \mu _i^x} \right)} \right]}}{{\sum\limits_{j = 1}^Q {\frac{{{\alpha _j}}}{{{{(2\pi )}^{n/2}}{{\left| {C_j^{xx}} \right|}^{1/2}}}}} \exp \left[ { - \frac{1}{2}{{\left( {x - \mu _j^x} \right)}^T}C_j^{x{\rm{x}} - 1}\left( {x - \mu _j^x} \right)} \right]}}$$
其中$C _ { i } = \left[ \begin{array} { l l } { C _ { i } ^ { \infty } } & { C _ { i } ^ { \mathrm { xy } } } \\ { C _ { i } ^ { y x } } & { C _ { i } ^ { y y } } \end{array} \right]$和$\mu_i=\begin{bmatrix}\mu_i^x\\ \mu_i^y\end{bmatrix}$
加权函数$h_i(x)$表示第$i$个高斯分量生成矢量x的后验概率。
2.2.2 训练和参数提取
利用以上讨论的回归方法进行频谱包络重建。为得到最优回归,通过使宽带语音通过带通滤波器来生成窄带语音,并提取频谱矢量序列,如图1所示。令$x=[x_1,x_2,...x_N]$为窄带语音频谱向量序列,$y=[y_1,y_2,...,y_n]$为宽带语音的频谱向量序列。通过训练向量序列,使用EM算法估计式(4)中模型$(\alpha,\mu,C)$的参数。

图1 GMM联合密度参数估计过程框图
2.2.3 码字相关功率估计
在NB到WB的转换中,只需利用窄带语音信息就可以估计出重构后的低频和高频语音的功率。先前的方法使用恒定的功率比来产生低频和高频语音[1],但很明显,功率比取决于声音identity(特性)。受此启发,本文还提出了一种与码字相关的功率估计方法。该方法使用一对码本。其中一个码本包含有代表性的窄带谱模板,另一个码本包含低/高频带语音与其窄带版本之间的功率比。这两个码本也是使用一对训练语音、窄带和宽带语音生成的。具体步骤如下:首先,生成窄带频谱矢量的码本。然后利用窄带谱码本对窄带语音训练后的每一帧语音进行矢量量化,并将低带宽和窄带语音的功率比进行聚类。最后,平均每个功率比群集中的功率比,并将其存储为功率比码本的码字。
2.3 从窄带语音生成宽带语音
图2显示了宽带语音生成过程的框图。其基本思想与[1]相似,具体步骤如下
(1)对输入窄带语音进行LPC分析,逐帧提取基音、功率和谱向量。
(2)利用GMM参数,通过式(6)和式(7)得到重构的宽带谱向量。
(3)利用分析过的基音、功率和重建的谱向量,由LPC合成器合成宽带语音。
(4)通过带阻滤波器提取低频段和高频段信号。
(5)通过分析窄带谱向量,解码功率比,将(4)的输出乘以功率比。
(6)将功率补偿的低频段和高频段语音加入到输入窄带语音中,得到重构的宽带输出语音。
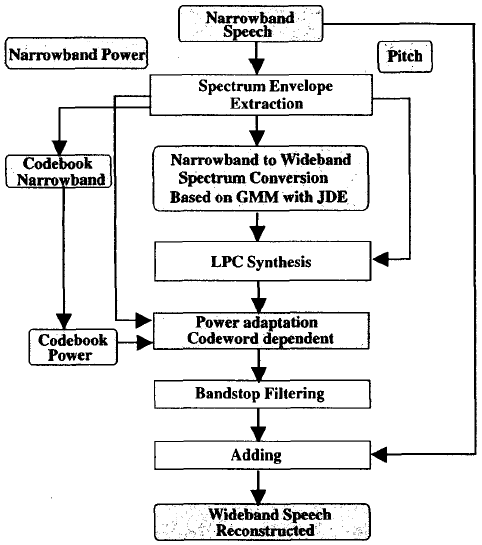
图2 基于GMM联合密度估计的宽带语音生成过程框图
3 实验结果
为了评估所提算法的性能,我们对所提算法和传统的忙了映射算法进行了客观语音质量测量和主观听力测试。实验条件如表1所示。
作为使用传统码本映射方法的初步实验,我们研究了哪种训练数据适合语音平衡的单词和句子数据库之间的NB到WB语音转换问题。结果表明,尽管词类型数据的数据库大小是句式数据的5倍,但是句式训练数据的性能要好于词类型数据。因此,我们选择了韩语语音平衡句子数据库进行训练。
我们还通过使用常规码本映射方法的另一个初步实验,评估了所提出的码字相关功率估计方法的性能。结果表明,使用所提出方法重建的宽带语音与使用原始语音的宽带语音之间没有明显的听觉差异。因此,为了将码本映射方法与基于GMM的方法进行比较,我们将所提出的功率估计方法应用于两种算法。除LPC顺序外,其他实验条件与[1]相同。在原始的码本映射方法中,LPC的阶数为14,但是我们将LPC的阶数增加到18,以覆盖宽带语音中的高频共振峰。因为在[13]中的最佳码本大小为128,所以我们选择GMM中相同数量的混合数128。
表一:实验条件
训练话术的数量:10句/每个说话人
分析window:Hamming
window长度:21ms
帧移长度:3ms
LPC阶数:18
VQ码本尺寸:128
GMM的混合数目:128
距离度量:LPC倒谱的欧氏距离
作为一种客观的质量度量,我们使用平均对数谱距离度量,它被近似为截断倒谱距离度量。表2显示了客观质量测量的结果,其中“spk-dep”和“spk-ind”分别表示说话人依赖的方式和说话人独立的方式。从表中可以看出,无论在说话人依赖还是说话人独立的情况下,提出的基于GMM的方法都优于传统的VQ码本映射方法。
表2:客观质量测量结果
| 语音类型 | 方法 | 方式 | 倒谱距离 |
| NB语音 | - | - | 11.82dB |
| 重建的宽带语音 | VQ | spk-dep | 3.27dB |
| GMM | spk-dep | 2.85dB | |
| VQ | spk-ind | 3.96dB | |
| GMM | spk-ind | 3.40dB |
我们通过主观偏好测试对算法的性能进行了评价。首先,我们比较了重建的宽带语音和窄带语音。在测试之前,给听众们展示了窄带和宽带语音的例子。为了验证实验的有效性,重构的宽带语音和窄带语音被随机地呈现在每个听众面前。在测试中,听众被要求判断两个测试话语中哪个更清晰。当听众不能确定哪一个更清晰时,他们可以选择“无差别”。我们还使用与上述相同的步骤,将所提出的算法所重建的宽带语音与传统的码本映射算法所重建的宽带语音进行了比较。
实验结果如表3所示。可以看出,该算法重构的宽带语音优于窄带语音,并且在说话人依赖和说话人独立两方面都优于传统的码本映射算法。
主观偏好测验结果
(a)、窄带语音与基于gmm的重组语音的比较
| NB 语音 | 无区别 | GMM | |
| spk-dep | 10.0% | 2.5% | 87.5% |
| spk-ind | 35.0% | 0.0% | 65.0% |
(b)、VQ码本映射法重构语音与基于gmm的方法重构语音
| VQ | 无区别 | GMM | |
| spk-dep | 2.5% | 32.5% | 65.0% |
| spk-ind | 7.5% | 27.5% | 65.0% |
4 总结
提出了一种基于联合密度估计的高斯混合模型,通过频谱变换从窄带语音中恢复宽带语音的新方法。我们还提出了一种基于码字的功率估计方法来获得重构的低频段和高频段语音信号的适当增益项。客观和主观测试结果均表明,该算法优于传统的码本映射方法。虽然所提算法的结果是很有希望的,但重建后的语音仍有一定的噪声。正在进行的研究正在处理这个问题。
参考文献
[1]Y. Yoshida and M. Abe, "An algorithm to reconstruct wideband speech from narrowband speech based on codebook mapping," Proc. of ICSLP 94, pp. 1591 -1 594, 1994.
[2]Y. M. Cheng, D. OShaughnessy, and P. Mermelstein,"Statistical recovery of wideband speech from narrowband speech," IEEE Trans. Speech and Audio Processing, Vo1.2,no.4, pp. 544-548, Oct. 1994.
[3]D. A. Reynolds and R. C. Rose, "Robust text-independent speaker identification using Gaussian mixture speaker models," IEEE Trans. Speech and Audio Processing, Vo1.3,no. 1, pp. 72-83, Jan. 1995.
[4]Y. Stylianou, Harmonic plus Noise Models for Speech,Combined with Statistical Methods, for Speech and Speaker Modification, Ph.D. thesis, Ecole Nationale Superieure des Telecommunication, Paris, France, pp. 115-144, Jan. 1996.
[5]A. Kain and M. W. Macon, "Spectral voice conversion for text-to-speech synthesis," Proc. of IEEE ICASSP 98, pp. 285-288,1998.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号