Pytorch从入门到精通
记得刚开始学TensorFlow的时候,那给我折磨的呀,我一直在想这个TensorFlow官方为什么搭建个网络还要画什么静态图呢,把简单的事情弄得麻烦死了,直到这几天我开始接触Pytorch,发现Pytorch是就是不用搭建静态图的Tensorflow版本,就想在用numpy一样,并且封装了很多深度学习高级API,numpy数据和Tensor数据相互转换不用搭建会话了,只需要一个转换函数,搭建起了numpy和TensorFlow爱的桥梁。
Pytorch自17年推出以来,一度有赶超TensorFlow的趋势,是因为Pytorch采用动态图机制,替代Numpy使用GPU的功能,搭建网络灵活。
Pytorch和TensorFlow的区别:
- TensorFlow是基于静态计算图的,静态计算图是先定义后运行,一次定义多次运行(Tensorflow 2.0也开始使用动态计算图)
- PyTorch是基于动态图的,是在运行的过程中被定义的,在运行的时候构建,可以多次构建多次运行
上手难度:tensorflow 1 > tensorflow 2 > pytorch
工业界:tensorflow 1>tensorflow 2 > pytorch
学术界:pytorch > tesnroflow 2 > tensorflow 1(已经被谷歌抛弃)
pytorch的数据类型
| Data type |
CPU tensor |
GPU tensor |
| torch.float32 | torch.FloatTensor | torch.cuda.FloatTensor |
| torch.floar64 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| torch.int32 | torch.IntTensor | torch.cuda.IntTensor |
| torch.int64 | torch.LongTensor | torch.cuda.LongTensor |
即便是同一个变量同时部署在CPU和GPU上面是不一样的
这篇文章的所有代码,请务必手敲!!!
安装
这个网址包含pytorch与cuda的对应关系
由于我的cuda是 10.0
我选择的安装命令是:
CPU版本:pip install torch==1.4.0 torchvision==0.5.0 -f https://download.pytorch.org/whl/torch_stable.html
GPU版本:pip install torch==1.4.0+cu92 torchvision==0.5.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html
官网给的安装命令是:
pip install torch==1.2.0 torchvision==0.4.0 # 或 pip install torch==1.2.0+cu92 torchvision==0.4.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html
我原本是:torch-1.2.0+cu92
目前我装的是(安装torchaudio时候帮我升级的):torch-1.6.0+cu101 torchaudio-0.6.0
创建张量
torch的数据类型torch.float32、torch.floar64、torch.float16、torch.int8、torch.int16、torch.int32、torch.int64。当数据在GPU上时,数据类型需要加上cuda,例:torch.cuda.FloatTensor
tensor.shape/tensor.size():获取张量的shape
tensor.reshape()/tensor.view():修改张量的shape
tensor.item():如果我们的张量只有一个数值,可以使用.item()获取,常用于获取loss值
tensor.dim():返回张量的阶数\维度
tensor.type():查看数据类型
tensor.cuda():将tensor转换到GPU上
# 0阶\0维 张量 a = torch.tensor(1.3) print(a) # tensor(1.3000) print(a.shape) # torch.Size([]) # 1阶张量 a = torch.tensor([1.1]) b = torch.tensor([1.1, 2.2]) print(a.shape) # torch.Size([1]) print(b.shape) # torch.Size([2]) # 2阶张量 a = torch.randn(2,3) print(a.shape) # torch.Size([2, 3]) # 3阶张量 a = torch.rand(1, 2, 3) print(a.shape) # torch.Size([1, 2, 3])
直接指定tensor的数值
print(torch.tensor([2.,3.2])) # tensor([2.0000, 3.2000]) print(torch.FloatTensor([2.,3.2])) # tensor([2.0000, 3.2000]) print(torch.tensor([[2.,3.2],[1.,22.3]])) # tensor([[ 2.0000, 3.2000], # [ 1.0000, 22.3000]])
定义未初始化张量
print(torch.empty(2,3)) # tensor([[2.5657e-05, 6.3199e-43, 2.5657e-05], # [6.3199e-43, 2.5855e-05, 6.3199e-43]]) print(torch.FloatTensor(2,3)) # tensor([[2.5804e-05, 6.3199e-43, 8.4078e-45], # [0.0000e+00, 1.4013e-45, 0.0000e+00]]) print(torch.IntTensor(2,3)) # tensor([[937482688, 451, 1], # [ 0, 1, 0]], dtype=torch.int32)
设置tensor数据的默认类型type
print(torch.tensor([1.2,3]).type()) torch.set_default_tensor_type(torch.DoubleTensor) print(torch.tensor([1.3,3]).type())
torch.ones(size)/zero(size)/eye(size):返回全为1/0/单位对角 张量
torch.full(size, fill_value):返回以size大小填充fill_value的张量
torch.rand(size):返回[0, 1)之间的均匀分布 张量
torch.randn(size):均值为0,方差为1的正态分布
torch.*_like(input):返回一个和input shape一样的张量,*可以为rand、randn...
torch.randint(low=0, high, size):返回shape=size,[low, high)之间的随机整数
torch.arange():和np.arange类似用法
torch.linspace(start, end, step=1000):返回start和end之间等距steps点的一维步长张量。
torch.logspace(start, end, steps=1000, base=10.0):返回$base^{start}$和$base^{end}$之间等距steps点的一维步长张量。
torch.randperm(n):返回从0到n-1的整数的随机排列
b = torch.rand(4) idx = torch.randperm(4) print(b) # tensor([0.0224, 0.7826, 0.5529, 0.2261]) print(idx) # tensor([0, 2, 1, 3]) print(b[idx]) # tensor([0.5573, 0.6121, 0.6581, 0.1892])
pytorch与numpy变量转换
numpy变量 -----> torch变量:torch.from_numpy(ndarray)
torch变量 ------> numpy变量:tensor.numpy()
x = np.array([[1, 2], [3, 4]]) y = torch.from_numpy(x) # 转换为 torch数据 z = y.numpy() # 转换为 numpy 数据
维度变换
- tensor.reshape():维度变换
- tensor.view():维度变换
- squeeze:去除对应维度为1的维度
- unsqueeze:往对应位置索引插入一个维度
a = torch.rand(4, 1, 28, 28) b = a.unsqueeze(0) print(b.shape) # torch.Size([1, 4, 1, 28, 28]) a = torch.rand(4, 1, 1, 28) b = a.squeeze() print(b.shape) # torch.Size([4, 28]) b = a.squeeze(1) print(b.shape) # torch.Size([4, 1, 28])
- tensor.expand(*size):返回具有单个尺寸扩展到更大尺寸的张量
- tensor.repeat(*size):沿指定尺寸重复此张量
x = torch.tensor([[1], [2], [3]]) print(x.size()) # torch.Size([3, 1]) print(x.expand(3, 4)) # tensor([[ 1, 1, 1, 1], # [ 2, 2, 2, 2], # [ 3, 3, 3, 3]]) print(x.expand(-1, 4)) # -1表示不改变维度的大小 # tensor([[ 1, 1, 1, 1], # [ 2, 2, 2, 2], # [ 3, 3, 3, 3]]) b = torch.tensor([1, 2, 3]) # torch.Size([1, 3]) print(b.repeat(4, 2).shape) # torch.Size([4, 6]) print(b.repeat(4, 2, 1).size()) # torch.Size([4, 2, 3])
- tensor.transpose():调换张量指定维度的顺序
- tensor.permute():将张量按指定顺序排列
b = torch.rand(4, 3, 28, 32) print(b.transpose(1, 3).shape) # torch.Size([4, 32, 28, 3]) print(b.permute(0, 2, 3, 1).shape) # torch.Size([4, 28, 32, 3])
- torch.cat(inputs, dim=0) :在给定维度上对输入的张量进行连接拼接
- torch.stack():沿着一个新维度对输入张量序列进行拼接
import torch a = torch.randn(2, 3) b = torch.randn(2, 3) c = torch.cat((a, b), 0).size() # (4, 3) d = torch.stack((a, b), 0).size() # (2, 2, 3)
索引与切片操作
a = torch.rand(4, 3, 28, 28) print(a.shape) # torch.Size([4, 3, 28, 28]) # 索引 print(a[0, 0].shape) # torch.Size([28, 28]) print(a[0, 0, 2, 4]) # tensor(0.1152) # 切片 print(a[:2].shape) # torch.Size([2, 3, 28, 28]) print(a[:2, :2, :, :].shape) # torch.Size([2, 2, 28, 28]) print(a[:2, -1:, :, :].shape) # torch.Size([2, 1, 28, 28]) # ...的用法 print(a[...].shape) # torch.Size([4, 3, 28, 28]) print(a[0, ...].shape) # torch.Size([3, 28, 28]) print(a[:, 1, ...].shape) # torch.Size([4, 28, 28]) print(a[..., :2].shape) # torch.Size([4, 3, 28, 2])
掩码取值
x = torch.tensor([[0.4573, 0.8571], [0.7237, 0.0265]]) mask = x.gt(0.5) # ge 是符号 >。满足条件返回True,否则False print(mask) # tensor([[False, True], # [ True, False]]) mask = x > 0.5 # 满足条件返回True,否则False # tensor([[False, True], # [ True, False]]) x_index = x[x > 0.5] # 把大于0.5的值都取出来 # tensor([0.8571, 0.7237]) print(torch.masked_select(x, mask)) # 返回满足条件的值 # tensor([0.8571, 0.7237]) mask = torch.where(x > 0.5) # 返回满足条件的索引((行,行), (列,列)) # (tensor([0, 1]), tensor([1, 0])) mask = torch.nonzero(x > 0.5) # tensor([[0, 1], # 第0行第1列 # [1, 0]]) # 第1行第0列
通过torch.take取值
src = torch.tensor([[4,3,5],[6,7,8]]) print(torch.take(src, torch.tensor([0,2,5]))) # 取第0、2、5个元素 # tensor([4, 5, 8])
数学运算
加法:tensor1 + tensor2 或 torch.add(tensor1, tensor2)
减法:tensor1 - tensor2 或 torch.sub(tensor1, tensor2)
a = torch.rand(3, 4) # dim=2 b = torch.rand(4) # dim=1 # 加法 print(a + b) print(torch.add(a, b)) # 减法 print(a - b) print(torch.sub(a, b))
乘法
tensor1 * tensor2 :对位元素相乘
torch.mul(tensor1, other) :input是矩阵,other可以是矩阵或标量,是矩阵时,对位相乘,就可以广播
torch.mm(tensor1, tensor2) :只能处理二维矩阵的乘法
tensor1 @ tensor2 :二维矩阵相乘
torch.bmm(tensor1, tensor2) :在torch.mm的基础上加了个batch计算,不能广播
torch.matmul(input, other) :适用性最多的,能处理batch,能广播的矩阵
- 如果第一个参数是一维,第二个是二维,那么给第一个提供一个维度
- 如果第一个是二维,第二个是一维,就是矩阵乘向量
- 带有batch的情况,可保留batch计算
- 维度不同时,可先广播,再batch计算
“广播”注释:Broadcasting,在运算中,不同大小的两个 array 应该怎样处理的操作。通常情况下,小一点的数组会被 broadcast 到大一点的,这样才能保持大小一致。Broadcasting 过程中的循环操作都在 C 底层进行,所以速度比较快。但也有一些情况下 Broadcasting 会带来性能上的下降。
总结:对位相乘用 torch.mul ,二维矩阵乘法用 torch.mm ,batch二维矩阵用 torch.bmm ,batch、广播用 torch.matmul
平方
a = torch.full([2,2], 2) # 创建一个shape=[2,2]值为2的数组 print(a.pow(2)) print(a**2)
平方根
a = torch.full([2,2], 4) # 创建一个shape=[2,2]值为4的数组 print(a.sqrt()) # 平方根 print(a**(0.5))
torch.exp():e的指数冥
torch.log():取对数
tensor.floor():向下取整
tensor.ceil() :向上取整
tensor.round():四舍五入
tensor.trunc():取整数值
tensor.frac():取小数值
tensor.clamp(min,max):不足最小值的变成最小值,大于最大值的变成最大值
torch.mean():求均值
torch.sum():求和
torch.max\torch.min:求最大最小值
torch.prod(input, dtype=None) :返回input中所有元素的乘积
torch.argmin(input)\torch.argmax(input):返回input张量中所有元素的最小值\最大值的索引
torch.where(condition, x, y):如果符合条件返回x,如果不符合条件返回y
torch.gather(input, dim, index):沿dim指定的轴收集值
- input:输入tensor
- dim:索引所沿的轴
- index:要收集的元素的索引
t = torch.tensor([[1,2],[3,4]]) torch.gather(t, 1, torch.tensor([[0,0],[1,0]])) # tensor([[ 1, 1], # [ 4, 3]])
autograd:自动求导
autograd 包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(define-by-run)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的.
让我们用一些简单的例子来看看吧。
张量
如果torch.Tensor 的属性 .requires_grad 设置为True,那么autograd 会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个 torch.Tensor 张量的所有梯度将会自动累加到 .grad属性上。
如果要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。
为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
每个张量都有一个 .grad_fn 属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的 grad_fn 是 None )。
如果需要计算导数,可以在 Tensor 上调用 .backward()。如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
有一部分有点难,需要多看几遍。
https://pytorch.apachecn.org/docs/1.2/beginner/blitz/autograd_tutorial.html
如果设置torch.tensor_1(requires_grad=True),那么会追踪所有对该张量tensor_1的所有操作。
import torch # 创建一个张量并设置 requires_grad=True 用来追踪他的计算历史 x = torch.ones(2, 2, requires_grad=True) print(x) # tensor([[1., 1.], # [1., 1.]], requires_grad=True)
当Tensor完成一个计算过程,每个张量都会自动生成一个.grad_fn属性
# 对张量进行计算操作,grad_fn已经被自动生成了。 y = x + 2 print(y) # tensor([[3., 3.], # [3., 3.]], grad_fn=<AddBackward>) print(y.grad_fn) # <AddBackward object at 0x00000232535FD860> # 对y进行一个乘法操作 z = y * y * 3 out = z.mean() print(z) # tensor([[27., 27.], # [27., 27.]], grad_fn=<MulBackward>) print(out) # tensor(27., grad_fn=<MeanBackward1>)
.requires_grad_(...) 可以改变张量的requires_grad属性。
import torch a = torch.randn(2, 2) a = ((a * 3) / (a - 1)) print(a.requires_grad) # 默认是requires_grad = False a.requires_grad_(True) print(a.requires_grad) # True b = (a * a).sum() print(b.grad_fn) # <SumBackward0 object at 0x000002325360B438>
梯度
回顾到上面
import torch # 创建一个张量并设置 requires_grad=True 用来追踪他的计算历史 x = torch.ones(2, 2, requires_grad=True) print(x) # tensor([[1., 1.], # [1., 1.]], requires_grad=True) # 对张量进行计算操作,grad_fn已经被自动生成了。 y = x + 2 print(y) # tensor([[3., 3.], # [3., 3.]], grad_fn=<AddBackward>) print(y.grad_fn) # <AddBackward object at 0x00000232535FD860> # 对y进行一个乘法操作 z = y * y * 3 out = z.mean() print(z) # tensor([[27., 27.], # [27., 27.]], grad_fn=<MulBackward>) print(out) # tensor(27., grad_fn=<MeanBackward1>)
让我们来反向传播,运行 out.backward() ,等于out.backward(torch.tensor(1.))
对out进行反向传播,$out = \frac{1}{4}\sum_i z_i$,其中$z_i = 3(x_i+2)^2$,因为方向传播中torch.tensor=1(out.backward中的参数)因此$z_i\bigr\rvert_{x_i=1} = 27$
对于梯度$\frac{\partial out}{\partial x_i} = \frac{3}{2}(x_i+2)$,把$x_i=1$代入$\frac{\partial out}{\partial x_i}\bigr\rvert_{x_i=1} = \frac{9}{2} = 4.5$
print(out) # tensor(27., grad_fn=<MeanBackward1>) print("*"*50) out.backward() # 打印梯度 print(x.grad) # tensor([[4.5000, 4.5000], # [4.5000, 4.5000]])
对吃栗子找到规律,才能看懂
import torch x = torch.randn(3, requires_grad=True) y = x * 2 while y.data.norm() < 1000: y = y * 2 print(y) # tensor([-920.6895, -115.7301, -867.6995], grad_fn=<MulBackward>) gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float) # 把gradients代入y的反向传播中 y.backward(gradients) # 计算梯度 print(x.grad) # tensor([ 51.2000, 512.0000, 0.0512])
为了防止跟踪历史记录,可以将代码块包装在with torch.no_grad():中。 在评估模型时特别有用,因为模型的可训练参数的属性可能具有requires_grad = True,但是我们不需要梯度计算。
print(x.requires_grad) # True print((x ** 2).requires_grad) # True with torch.no_grad(): print((x ** 2).requires_grad) # False
自定义数据集
这一节从我的另一篇文章截取了部分,想要具体了解请参考:pytorch加载语音类自定义数据集
pytorch内部集成了一些常用的数据集调用接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合
- torch.utils.data.Dataset:所有继承他的子类都应该重写 __len()__ , __getitem()__ 这两个方法
- __len()__ :返回数据集中数据的数量
- __getitem()__ :返回支持下标索引方式获取的一个数据
- torch.utils.data.DataLoader:对数据集进行包装,可以设置batch_size、是否shuffle....
要创建自己的自定义的数据集首先要创建一个自定义的数据集类,这个类要继承torch.utils.data.Dataset类,并且我们还需要重写父类的__init__()和__getitem__()方法,具体形式如下
from torch.utils.data import Dataset # 创建 MyselfDataset 数据集类 class MyselfDataset(Dataset): def __init__(self): # 类的初始化 def __getitem__(self, item): # 根据索引item 返回数据 def __len__(self): # 返回数据集的总数
接下来我们通过例子和代码注释来学习一下如何创建自己的数据集:
假设我们有一下文件目录结构:
filename_dataset.py 是我们创建数据集的脚本文件,我们的目的是每次读取都能返回一个shape为(batch_size, channel, seq_len)的语音数据。
import fnmatch import os import librosa import numpy as np from torch.utils.data import Dataset # 创建fileDataset数据集 class fileDataset(Dataset): def __init__(self, data_folder, sr=16000, dimension=8192): """ :param data_folder:音频数据地址 :param sr: 音频采样率 :param dimension:音频帧长 """ self.data_folder = data_folder self.sr = sr self.dim = dimension # 获取音频名列表 self.wav_list = [] for root, dirnames, filenames in os.walk(data_folder): for filename in fnmatch.filter(filenames, "*.wav"): # 实现列表特殊字符的过滤或筛选,返回符合匹配“.wav”字符列表 self.wav_list.append(os.path.join(root, filename)) def __getitem__(self, item): # 根据索引item 返回数据 filename = self.wav_list[item] # 从列表中取一个音频文件名 wb_wav, _ = librosa.load(filename, sr=self.sr) # 读取音频文件 # 取 帧 if len(wb_wav) >= self.dim: # 如果音频长度大于帧长,则随机取一帧 max_audio_start = len(wb_wav) - self.dim audio_start = np.random.randint(0, max_audio_start) wb_wav = wb_wav[audio_start: audio_start + self.dim] else: # 如果音频长度小于帧长,则通过在音频后面补0,补齐到帧长 wb_wav = np.pad(wb_wav, (0, self.dim - len(wb_wav)), "constant") # 返回一帧语音数据和文件名 return wb_wav, filename def __len__(self): # 返回音频文件的总数 return len(self.wav_list) # 实例化 fileDataset数据集 对象 train_set = fileDataset("./p225", sr=16000) for data in train_set: wav_data, wav_name = data # 第一个返回对象是数据,第二个返回对象是文件名 print(wav_data.shape) # (8192,) print(wav_name) # 0 ./p225\p225_001.wav break
训练模型
搭建网络
我们先来定义一个网络,所有的使用pytorch框架定义的的神经网络模型都需要继承nn.Module类。在定义神经网络时,我们需要在__init__()函数中初始化网络层,在forward()函数 将数据输入神经网络进行前向传播,返回模型输出。
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 输入图像channel:1,输出channel:6; 5*5卷积核 self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # 前向传播 x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # 如果核大小是正方形,则只能指定一个数字 x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) # reshape 成二维,方便做全连接操作 x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # 除去 batch 维度的其他维度 num_features = 1 for s in size: num_features *= s return num_features net = Net() # 打印模型结构 print(net) # Net( # (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) # (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) # (fc1): Linear(in_features=400, out_features=120, bias=True) # (fc2): Linear(in_features=120, out_features=84, bias=True) # (fc3): Linear(in_features=84, out_features=10, bias=True))
权重初始化
对网络中的某一层进行初始化
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
init.xavier_uniform(self.conv1.weight)
init.constant(self.conv1.bias, 0.1)
对网络的整体进行初始化
在网络之外初始化
方法一
def weights_init(m): classname = m.__class__.__name__ # 返回传入的module类型 if classname.find("Conv") != -1: m.weight.data.xavier_(0.0, 0.02) elif classname.find("BatchNorm2d") != -1: m.weight.data.normal_(1.0, 0.02) # bn层里初始化γ,服从(1,0.02)的正态分布# bn层里初始化γ,服从(1,0.02)的正态分布 m.bias.data.fill_(0) # bn层里初始化β,默认为0 model = Net() # 构建网络 # 对所有的Conv层都初始化权重. # apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。 model.apply(weights_init)
不建议访问以下划线为前缀的成员,他们是内部的,如果有改变不会通知用户。更推荐的一种方法是检查某个module是否是某种类型:
方法二
for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): # 卷积层和全连接层参数初始化 nn.init.normal(m.weight.data) m.bias.data.fill_(0) elif isinstance(m, nn.BatchNorm2d): # BatchNorm2d层参数初始化 m.weight.data.normal_()
在网络里面初始化
def weights_init(m): classname = m.__class__.__name__ if classname.find("Conv") != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find("BatchNorm2d") != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) def my_model(nn.Module): def __init__(self): # 因为self代表类的实例化, # 也就是说谁调用这个类的方法,self就指向谁 # 我们可以在__init()__中,直接初始化模型,一般放在最后 self.apply(weights_init)
关于pytorch中的参数初始化方法总结可以参考这篇文章:链接,
损失函数
我们这里计算均方误差 $loss=nn.MSELoss(模型预测值-目标)$
output = net(input) # torch.Size([1, 10]) target = torch.randn(10) # 生成一个随机数据作为target target = target.reshape(1,-1) # [1, 10] mse_loss = nn.MSELoss() loss_value = mse_loss(output, target) print(loss_value) # tensor(0.5513, grad_fn=<MseLossBackward>)
当我们调用loss.backward(),将误差反向传播,图中所有设置了requires_grad=True的张量的开始计算梯度,模型开始反向传播训练参数
反向传播
为了实现损失函数的梯度反向传播,我们只需要使用 loss.backward() 来反向传播权重。首先需要清零现有的梯度,否则梯度会与之前计算的梯度累加。
我们还可以观察 conv1层的偏置项(bias)的梯度,在反向传播前后的梯度。
net.zero_grad() # 清零所有参数的梯度 print('反向传播之前的 conv1.bias.grad 梯度') print(net.conv1.bias.grad) # tensor([0., 0., 0., 0., 0., 0.]) loss.backward() print('反向传播之后的 conv1.bias.grad 梯度') print(net.conv1.bias.grad) # tensor([-0.0118, 0.0125, -0.0085, -0.0225, 0.0125, 0.0235])
优化器更新模型参数
pytorch在 torch.optim 中集成了非常多的优化器,我们经常用的有:Adam、SGD、RMSProp...,使用方法如下
import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.01) # 创建 SGD 优化器 optimizer.zero_grad() # 清零梯度缓存 output = net(input) loss = criterion(output, target) # 损失函数 loss.backward() # 损失函数的梯度反向传播 optimizer.step() # 更新参数
TensorBoard可视化
我通过from torch.utils.tensorboard import SummaryWriter导入tensorboard有问题,因此我选择通过tensorboardX。
from tensorboardX import SummaryWriter
创建事件对象:writer = SummaryWriter(logdir)
写入图片数据:writer.add_image(tag, img_tensor, global_step=None)
写入标量数据:writer.add_scalar(tag=, scalar_value, global_step=None)
关闭事件对象:writer.close()
在事件文件夹 ./events 中打开cmd,输入
tensorboard --logdir=runs # 或者 tensorboard --logdir "./"
然后在浏览器中输入
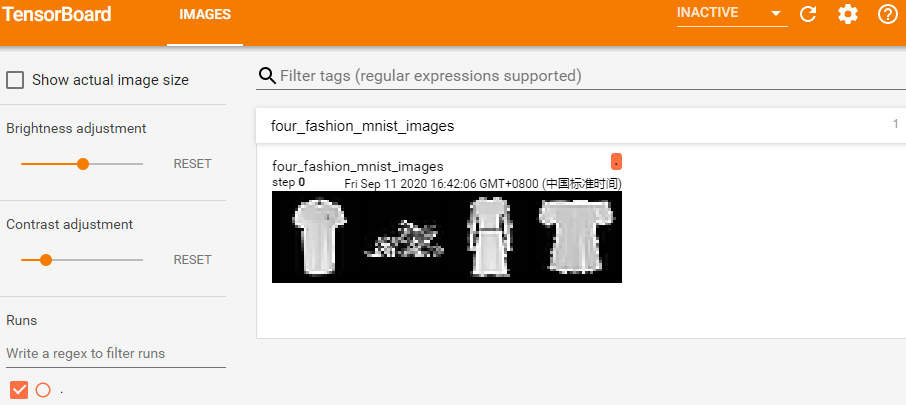
MNIST图像分类器
我们通过一个小小的项目案例来讲解
- 导包和定义超参数
- 加载训练和测试数据集
- 定义一个卷积神经网络
- 定义一个损失函数
- 在训练样本数据上训练网络
- 在测试样本数据上测试网络
# Author:凌逆战 # -*- coding:utf-8 -*- import os import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from tensorboardX import SummaryWriter from torchvision import datasets, transforms batch_size = 64 epochs = 10 checkpoints_dir = "./checkpoint" event_dir = "./enent_file" model_name = None # 如果要加载模型继续训练 则 "/10.pth" lr = 1e-4
检测GPU是否可用,可用则使用GPU,不可用则使用CPU
print("GPU是否可用:", torch.cuda.is_available()) # True device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
加载MNIST数据集
# 实例化 Dataset train_dataset = datasets.MNIST(root="./dataset/", train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])) test_dataset = datasets.MNIST(root="./dataset/", train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])) # 数据加载器 train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
保存检查点的地址(如果检查点不存在,则创建)
# ########### 保存检查点的地址(如果检查点不存在,则创建) ############ if not os.path.exists(checkpoints_dir): os.makedirs(checkpoints_dir)
模型搭建
# ########### 模型搭建 ############ class Net(nn.Module): """ConvNet -> Max_Pool -> RELU -> ConvNet -> Max_Pool -> RELU -> FC -> RELU -> FC -> SOFTMAX""" def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(in_channels=1, out_channels=20, kernel_size=5, stride=1) self.conv2 = nn.Conv2d(in_channels=20, out_channels=50, kernel_size=5, stride=1) self.fc1 = nn.Linear(in_features=4 * 4 * 50, out_features=500) self.fc2 = nn.Linear(in_features=500, out_features=10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.max_pool2d(x, kernel_size=2, stride=2) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, 2, 2) x = x.view(-1, 4 * 4 * 50) x = F.relu(self.fc1(x)) x = self.fc2(x) return x # 模型实例化,如果GPU可用则把模型放到GPU上 model = Net().to(device)
损失函数
# ########### 损失函数 ############ criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
优化器
# ########### 优化器 ############ optimizer = optim.SGD(model.parameters(), lr=lr)
TensorBoard可视化
# ########### TensorBoard可视化 summary ############ writer = SummaryWriter(event_dir) # 创建事件文件
如果我们之前训练了模型并且中途中断,想要继续训练,则进行检查,如果存在则加载之前的模型继续训练
# ########### 加载模型检查点 ############ start_epoch = 0 if model_name: print("加载模型:", checkpoints_dir + model_name) # "./checkpoint/10.pth" checkpoint = torch.load(checkpoints_dir + model_name) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) start_epoch = checkpoint['epoch']
开始训练
for epoch in range(start_epoch, epochs): # ########### 训练 ############ model.train() # 模型训练 标识 for batch_idx, (data, target) in enumerate(train_loader): data = data.to(device) # 训练数据,放到GPU上 target = target.to(device) # 训练标签,放到GPU上 # 前向传播 output = model(data) loss = criterion(output, target) # 计算损失函数 # 反向传播 optimizer.zero_grad() # 将梯度清零 loss.backward() # 反向传播 optimizer.step() # 更新参数 print('Train Epoch: {} \tLoss: {:.6f}'.format(epoch+1, loss.item())) # ########### TensorBoard可视化 summary ############ writer.add_scalar(tag="train_loss", scalar_value=loss.item(), global_step=epoch + 1) writer.flush() # ########### 测试 ############ model.eval() # 模型测试 标识 test_loss = 0 correct = 0 # 测试的时候不需要梯度 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss += criterion(output, target).item() test_loss /= len(test_loader.dataset) print('测试集: 损失: {:.4f}, 精度: {:.2f}%'.format( test_loss, 100. * correct / len(test_loader.dataset))) # ########### TensorBoard可视化 summary ############ writer.add_scalar(tag="val_loss", scalar_value=test_loss, global_step=epoch + 1) writer.flush() # ########### 保存模型 ############ # 每10个epoch保存一次模型 if (epoch + 1) % 10 == 0: checkpoint = { "model_state_dict": model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), "epoch": epoch + 1, # 'lr_schedule': lr_schedule.state_dict() } torch.save(checkpoint, '%s/%d.pth' % (checkpoints_dir, epochs))
训练过程和结果我放在里


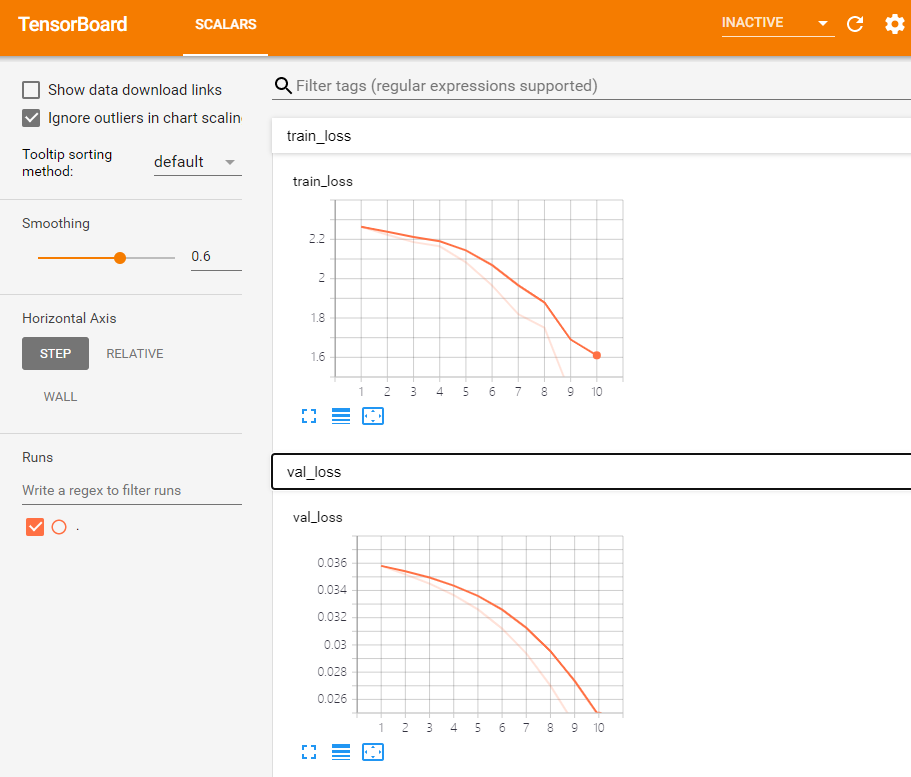
GPU是否可用: True Train Epoch: 1 Loss: 2.263870 测试集: 损失: 0.0358, 精度: 12.71% Train Epoch: 2 Loss: 2.223585 测试集: 损失: 0.0352, 精度: 36.97% Train Epoch: 3 Loss: 2.185703 测试集: 损失: 0.0345, 精度: 49.51% Train Epoch: 4 Loss: 2.164557 测试集: 损失: 0.0337, 精度: 57.56% Train Epoch: 5 Loss: 2.082955 测试集: 损失: 0.0326, 精度: 63.23% Train Epoch: 6 Loss: 1.965825 测试集: 损失: 0.0312, 精度: 66.60% Train Epoch: 7 Loss: 1.818842 测试集: 损失: 0.0294, 精度: 68.75% Train Epoch: 8 Loss: 1.750836 测试集: 损失: 0.0270, 精度: 71.13% Train Epoch: 9 Loss: 1.412864 测试集: 损失: 0.0242, 精度: 74.24% Train Epoch: 10 Loss: 1.491193 测试集: 损失: 0.0210, 精度: 77.63%
如果我们先看tensorboard的曲线,可以打开enent_file文件夹,在当前文件夹打开cmd,然后输入tensorboard --logdir "./",就可以看到

然后在浏览器中输入https://localhost:6006/ 即可显示
多GPU训练模型
加速神经网络训练最简单的办法就是上GPU,如果一块GPU还是不够,就多上几块。像BERT和GPT-2这样的大型语言模型甚至是在上百块GPU上训练的。为了实现多GPU训练,我们必须想一个办法在多个GPU上分发数据和模型,并且协调训练过程。
单机多卡的办法有很多:
- nn.DataParallel (简单方便)
- torch.distributed (进阶)
- apex (高级)
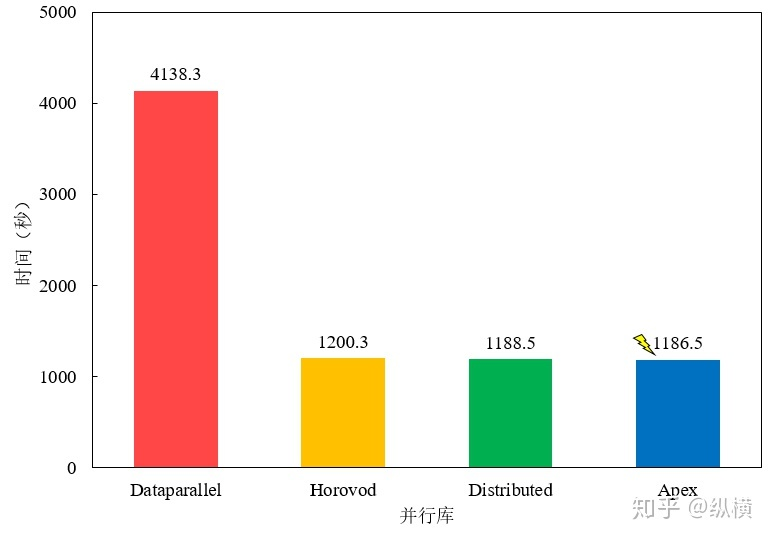
这里,记录了使用 4 块 Tesla V100-PICE 在 ImageNet 进行了运行时间的测试,测试结果发现 Apex 的加速效果最好,但与 Horovod/Distributed 差别不大,平时可以直接使用内置的 Distributed。Dataparallel 较慢,不推荐使用。
torch.nn.DataParallel
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总
- module:要并行化的模型
- device_ids:参与训练的 GPU 有哪些,(默认:所有设备)
- output_device:用于汇总梯度的 GPU 是哪个,(默认:device_ids[0])
这里需要注意,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理,否则会报错:
# main.py import os import torch from torch import nn from torch.utils.data import DataLoader os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" # 使用第一个和第二个GPU train_dataset = ... train_loader = DataLoader(train_dataset, batch_size=...) # 如果GPU可用,则环境变量CUDA_VISIBLE_DEVICES中指定的全部GPU都会被拿来使用 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 实例化模型 model = ....to(device) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") model = nn.DataParallel(model) optimizer = torch.optim.SGD(model.parameters(),lr=...) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.to(device) target = target.to(device) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
缺点:
- 在每个训练批次(batch)中,因为模型的权重都是在 一个进程上先算出来 然后再把他们分发到每个GPU上,所以网络通信就成为了一个瓶颈,而GPU使用率也通常很低。
- 除此之外,nn.DataParallel 需要所有的GPU都在一个节点(一台机器)上,且并不支持 Apex 的 混合精度训练。
nn.DataParallel 一个进程算权重使通信成为瓶颈,慢而且不支持混合精度训练
Torch.distributed
DataParallel 是单进程控制多 GPU,而 DistributedDataParallel 是多进程控制多 GPU,进程数等于GPU数,每个进程独享一个GPU,每个进程都会独立地执行代码。这意味着每个进程都独立地初始化模型、训练,当然,在每次迭代过程中会通过进程间通信共享梯度,整合梯度,然后独立地更新参数。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也推荐使用 DistributedDataParallel 。
分布式训练的具体流程:
1、pytorch 为我们提供了 torch.distributed.launch 启动器,用于在命令行分布式地执行 python 文件。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 通过参数传递给 python,我们可以这样获得当前进程的 index:
parser = argparse.ArgumentParser() parser.add_argument('--local_rank', default=-1, type=int, help='node rank for distributed training') args = parser.parse_args() print(args.local_rank)
2、初始化进程组
在使用DDP之前,需要通过 torch.distributed.init_process_group 方法初始化进程组。这个方法会设置通信的后端(如NCCL)、进程数、主机名等参数,并建立进程之间的通信通道。
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:12913', world_size=nprocs, rank=local_rank)
3、模型复制
在初始化进程组后,DDP会将模型复制到每个GPU设备上。每个GPU都会有一个独立的模型副本。
因为每个进程都会初始化一份模型,为保证模型初始化过程中生成的随机权重相同,需要设置随机种子。方法如下:
def set_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)
4、输入分割
使用 torch.utils.data.DistributedSampler 来对数据进行分布式采样,将一个epoch里面的num_step个数据分成nprocs份,每个进程只处理其中一份数据,以确保每个进程(GPU)获取到不同的数据子集。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
5、使用DDP包装模型
使用 torch.nn.parallel.DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
6、最后,把数据和模型加载到当前进程使用的 GPU 中,正常进行正反向传播:
torch.cuda.set_device(args.local_rank) model.cuda() for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
汇总一下,torch.distributed 并行训练部分主要与如下代码段有关:
import torch import argparse import torch.distributed as dist parser = argparse.ArgumentParser() # 负责创建 args.local_rank 变量,并接受 torch.distributed.launch 注入的值 parser.add_argument('--local_rank', default=-1, type=int, help='node rank for distributed training') args = parser.parse_args() # 初始化分布式环境,主要用来帮助进程间通信 dist.init_process_group(backend='nccl') # 每个进程根据自己的local_rank设置应该使用的GPU torch.cuda.set_device(args.local_rank) device = torch.device('cuda', args.local_rank) # 固定随机种子 seed = 42 random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) # 分布式数据集 train_dataset = ... train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) # 注意这里的batch_size是每个GPU上的batch_size # 分布式模型 model = ... model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank]) optimizer = optim.SGD(model.parameters()) # 只master进程做 logging,否则输出会很乱 if args.local_rank == 0: writer = SummaryWriter(comment='ddp-training') for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step() if args.local_rank == 0: writer.add_scalar(tag=, scalar_value=, global_step=) writer.flush()
在使用时,调用 torch.distributed.launch 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 train.py
参数解释:
- torch.distributed.launch:以命令行参数的方式将 args.local_rank 变量注入到每个进程中,每个进程得到的变量值都不相同。比如使用 4 个GPU的话,则 4 个进程获得的 args.local_rank 值分别为0、1、2、3
- nproc_per_node:表示每个节点需要创建多少个进程(使用几个GPU就创建几个)
- nnodes:表示使用几个节点,因为我们是做单机多核训练,所以设为1
详细代码参考:ddp_train.py、在 ImageNet 上的完整训练代码。
distributed 题外话
torch.distributed.barrier()
类似一个路障,进程会被拦住,直到所有进程都集合齐了才放行。
适合这样的场景:
- 只一个进程下载,其他进程可以使用下载好的文件;
- 只一个进程预处理数据,其他进程使用预处理且cache好的数据等。
模型保存与加载
模型的保存与加载与单GPU的方式有所不同。这里通通将参数以cpu的方式save进存储,因为如果是保存的GPU上参数,pth文件中会记录参数属于的GPU号,则加载时会加载到相应的GPU上,这样就会导致如果你GPU数目不够时会在加载模型时报错。
模型保存都是一致的,不过时刻记住你有多个进程在同时跑,所以会保存多个模型到存储上,如果使用共享存储就要注意文件名的问题,当然一般只在rank0进程上保存参数即可,因为所有进程的模型参数是同步的。
torch.save(model.module.cpu().state_dict(), "model.pth")
模型的加载:
param=torch.load("model.pth")
以下是huggingface/transformers代码中用到的模型保存代码
if torch.distributed.get_rank() == 0: model_to_save = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training model_to_save.save_pretrained(args.output_dir) tokenizer.save_pretrained(args.output_dir)
同一台机器上跑多个 ddp task
假设想在一台有4核GPU的电脑上跑两个ddp task,每个task使用两个核,很可能会需要如下错误:
RuntimeError: Address already in use RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1544081127912/work/torch/lib/c10d/ProcessGroupNCCL.cpp:260, unhandled system error
原因是两个ddp task通讯地址冲突,这时候需要显示地设置每个task的地址
# 第一个task export CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node=2 --master_addr=127.0.0.1 --master_port=29501 train.py # 第二个task export CUDA_VISIBLE_DEVICES="2,3" python -m torch.distributed.launch --nproc_per_node=2 --master_addr=127.0.0.2 --master_port=29502 train.py
torch.multiprocessing
有的同学可能比较熟悉 torch.multiprocessing,也可以手动使用 torch.multiprocessing 进行多进程控制。绕开 torch.distributed.launch 自动控制开启和退出进程的一些小毛病~
这里有一点:需要安装NCCL,如果没有安装NCCL训练起来和单卡没有区别,我就是被这一点坑了,花了好几天时间😭。
使用时,只需要调用 torch.multiprocessing.spawn,torch.multiprocessing 就会帮助我们自动创建进程。如下面的代码所示,spawn 开启了 nprocs=4 个进程,每个进程执行 main_worker 并向其中传入 local_rank(当前进程 index)和 args(即 4 和 myargs)作为参数:
import torch.multiprocessing as mp mp.spawn(main_worker, nprocs=4, args=(4, myargs))
这里,我们直接将原本需要 torch.distributed.launch 管理的执行内容,封装进 main_worker 函数中,其中 proc 对应 local_rank(当前进程 index),进程数 nproc 对应 4, args 对应 myargs:
def main_worker(proc, nproc, args): dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu) torch.cuda.set_device(args.local_rank) train_dataset = ... train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) model = ... model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank]) optimizer = optim.SGD(model.parameters()) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
在上面的代码中值得注意的是,由于没有 torch.distributed.launch 读取的默认环境变量作为配置,我们需要手动为 init_process_group 指定参数:
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)
汇总一下,添加 multiprocessing 后并行训练部分主要与如下代码段有关:
# main.py import torch import torch.distributed as dist import torch.multiprocessing as mp mp.spawn(main_worker, nprocs=4, args=(4, myargs)) def main_worker(proc, nprocs, args): dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu) torch.cuda.set_device(args.local_rank) train_dataset = ... train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) model = ... model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank]) optimizer = optim.SGD(model.parameters()) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
在使用时,直接使用 python 运行就可以了:
python main.py
在 ImageNet 上的完整训练代码,请点击Github。
使用Apex再加速
以后再补
Horovod 的优雅实现
Horovod 是 Uber 开源的深度学习工具,它的发展吸取了 Facebook "Training ImageNet In 1 Hour" 与百度 "Ring Allreduce" 的优点,可以无痛与 PyTorch/Tensorflow 等深度学习框架结合,实现并行训练。
在 API 层面,Horovod 和 torch.distributed 十分相似。在 mpirun 的基础上,Horovod 提供了自己封装的 horovodrun 作为启动器。
与 torch.distributed.launch 相似,我们只需要编写一份代码,horovodrun 启动器就会自动将其分配给$n$个进程,分别在$n$个 GPU 上运行。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 注入 hvd,我们可以这样获得当前进程的 index:
import horovod.torch as hvd hvd.local_rank()
与 init_process_group 相似,Horovod 使用 init 设置GPU 之间通信使用的后端和端口:
hvd.init()
接着,使用 DistributedSampler 对数据集进行划分。如此前我们介绍的那样,它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
之后,使用 broadcast_parameters 包装模型参数,将模型参数从编号为 root_rank 的 GPU 复制到所有其他 GPU 中:
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
然后,使用 DistributedOptimizer 包装优化器。它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值:
hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=hvd.Compression.fp16)
最后,把数据加载到当前 GPU 中。在编写代码时,我们只需要关注正常进行正向传播和反向传播:
torch.cuda.set_device(args.local_rank) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
汇总一下,Horovod 的并行训练部分主要与如下代码段有关:
# main.py import torch import horovod.torch as hvd hvd.init() torch.cuda.set_device(hvd.local_rank()) train_dataset = ... train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=hvd.size(), rank=hvd.rank()) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) model = ... model.cuda() optimizer = optim.SGD(model.parameters()) optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters()) hvd.broadcast_parameters(model.state_dict(), root_rank=0) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
在使用时,调用 horovodrun 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 horovodrun -np 4 -H localhost:4 --verbose python main.py
在 ImageNet 上的完整训练代码,请点击Github。
保存和加载模型
torch.save:保存模型,序列化对象保存到磁盘,常见的PyTorch约定是使用.pt或 .pth文件扩展名保存模型。
torch.load:加载模型,目标文件反序列化到内存中
torch.nn.Module.load_state_dict:使用反序列化的state_dict加载模型的参数字典
state_dict:python字典,包括具有可学习参数的层、每层的参数张量、优化器以及优化器超参数
为了充分了解state_dict,我们看下面例子:
import torch.nn as nn import torch.nn.functional as F from torch import optim class TheModelClass(nn.Module): def __init__(self): super(TheModelClass, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x model = TheModelClass() # 初始化模型 optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 初始化optimizer print("Model的state_dict:") for param_tensor in model.state_dict(): print(param_tensor, "\t", model.state_dict()[param_tensor].size()) print("Optimizer的state_dict:") for var_name in optimizer.state_dict(): print(var_name, "\t", optimizer.state_dict()[var_name]) # Model的state_dict: # conv1.weight torch.Size([6, 3, 5, 5]) # conv1.bias torch.Size([6]) # conv2.weight torch.Size([16, 6, 5, 5]) # conv2.bias torch.Size([16]) # fc1.weight torch.Size([120, 400]) # fc1.bias torch.Size([120]) # fc2.weight torch.Size([84, 120]) # fc2.bias torch.Size([84]) # fc3.weight torch.Size([10, 84]) # fc3.bias torch.Size([10]) # Optimizer的state_dict: # state {} # param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [3251954079208, 3251954079280, 3251954079352, 3251954079424, 3251954079496, 3251954079568, 3251954079640, 3251954079712, 3251954079784, 3251954079856]}]
保存
torch.save(model.state_dict(), PATH) # 保存模型的参数 torch.save(model, PATH) # 保存整个模型
加载
model.load_state_dict(torch.load(PATH)) # 加载模型的参数 model = torch.load(PATH) # 加载整个模型
继续训练
保存
checkpoint = { 'epoch': epoch, 'model_state_dict': model.state_dict(), # 模型参数 'optimizer_state_dict': optimizer.state_dict(), # 优化器参数 'loss': loss, ... } PATH = './checkpoint/ckpt_best_%s.pth' %(str(epoch)) # path中要包含.pth torch.save(checkpoint, PATH)
加载
model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss'] model.eval() # 或 model.train()
参考
【知乎】PyTorch实现断点继续训练
简单易上手的PyTorch中文文档:https://github.com/fendouai/pytorch1.0-cn
单机多卡
- 【知乎】PyTorch 21.单机多卡操作(分布式DataParallel,混合精度,Horovod)
- 【GitHub】PyTorch 单机多GPU 训练方法与原理整理★
- 【GitHub】pytorch-distributed(tczhangzhi)
- 【Github】pytorch-distributed-training(rentainhe)
- 【GitHub】horovod
- 【GitHub】apex
- 【GitHub】distribuuuu
- 【CSDN】Pytorch 保存加载模型时的坑
horovod安装
- 【CSCD】ubuntu16.04 安装horovod
- 【CSCD】Horovod安装和使用
- 【知乎】安装horovod(环境)的正确姿势
【文档】
【视频】
- 莫烦pytorch
- [晓唦带你读]《动手学深度学习》(PyTorch版)完结!4万播放
- pytorch 入门学习(目前见过最好的pytorch学习视频)12万播放
- 《PyTorch深度学习实践》完结合集 4万播放

 浙公网安备 33010602011771号
浙公网安备 33010602011771号