基于MFCC的语音数据特征提取概述
1. 概述
语音是人类之间沟通交流的最直接也是最快捷方便的一种手段,而实现人类与计算机之间畅通无阻的语音交流,一直是人类追求的一个梦想。
伴随着移动智能设备的普及,各家移动设备的厂家也开始在自家的设备上集成了语音识别系统,像Apple Siri、Microsoft Cortana、Google Now等语音助手的出现,使得人们在使用移动设备的同时,也能够进行语音交流,极大的方便了人们的生活。但是此类助手也存在一些尴尬的瞬间,例如在一些工作场合或者聚会的场合,某人的一句“Hey Siri”就可能唤醒多台苹果设备,使用者难免尴尬困惑。
而此类予语音助手背后,均是一种被称作“闻声识人”的计算机技术,称为语音识别。语音识别技术属于生物认证技术,而其中的说话人识别(speaker recognize,SR)是其中的一种,该技术通常也被称为声纹识别技术,该技术是一项通过语音波形中反映说话人生理特征和行为特征的一组语音参数,自动识别说话人身份的技术。其核心是通过预先录入说话人的声音样本,提取出说话人独一无二的语音特征并存入数据库,应用的时候将待验证的语音进行特征提取并与数据库中的特征进行匹配,以确定说话人的身份。
1.1 什么是声纹?
声纹(voiceprint)是用电声学仪器显示的携带者言语信息的声波频谱,是由波长、频率以及强度等百余种特征维度组成的生物特征,具有稳定性、可测量性以及唯一性等特点。
人类语言的产生是由人体语言中枢与发生器官之间进行的一个复杂的生物物理反应过程。发声器官如舌头、牙齿、喉咙、肺、鼻子在尺寸和形态上因人而异,所有任何两个人的声波图谱都有一定的差异性。
每个人的语音声学特征既有相对稳定性,又有个体差异性。这种差异可能来自生理、病理、心理、模拟、伪装等,也可能会周围环境的干扰相关。
由于每个人的发生器官都有其独特性,因此在一般情况下,人们仍然能区别不同的人的声音或者判断是否是同一个人的声音。
声纹不像图像那样的直观,在实际的分析中,可以通过波形图和语谱图进行绘制展现,例如下图是一段从1到10的读数语音文件对应的波形图和语谱图(上部分为声音波形图,下部分为声音语谱图):
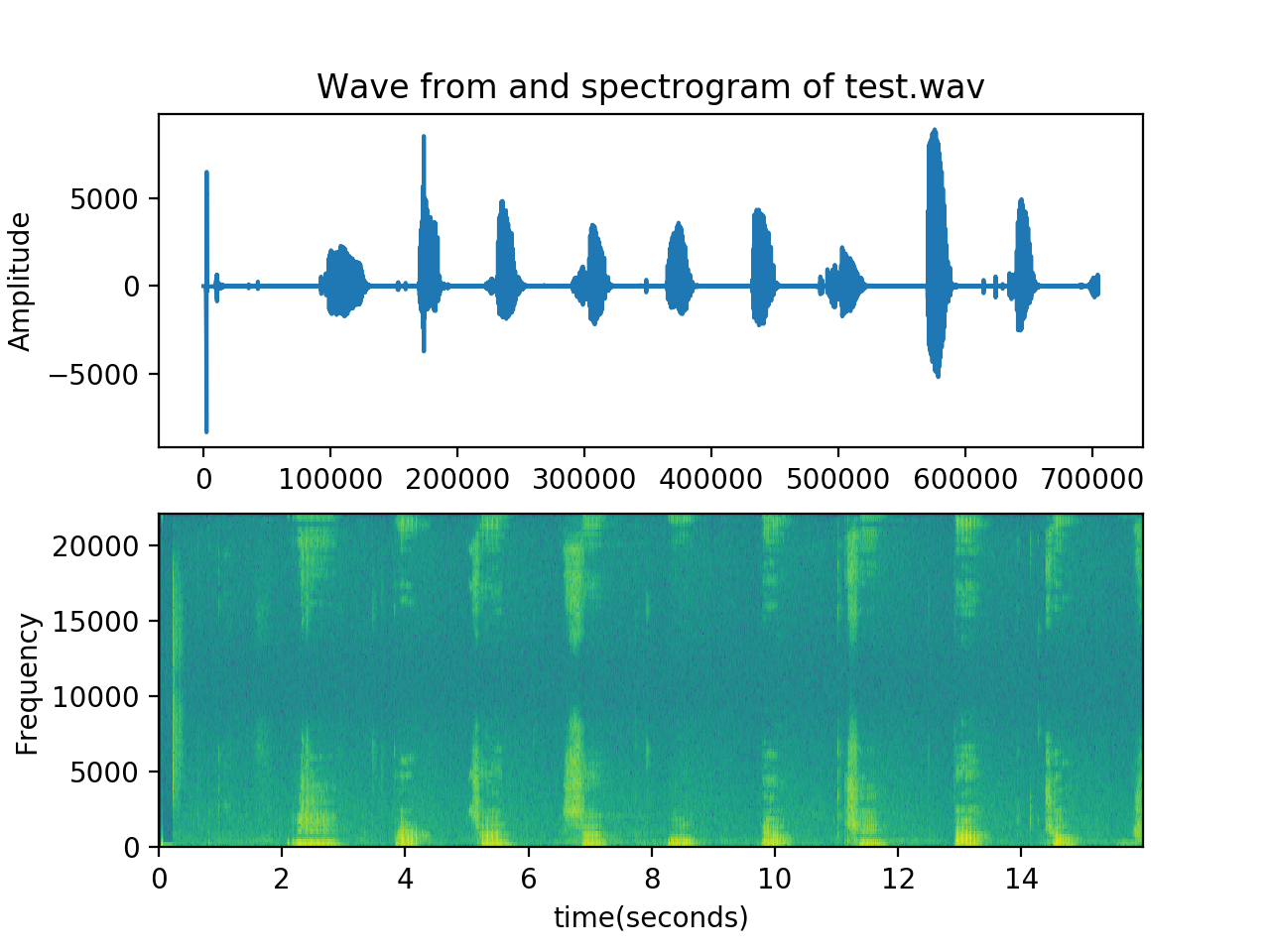
import wave import numpy as np import matplotlib.pyplot as plt fw = wave.open('test.wav','r') soundInfo = fw.readframes(-1) soundInfo = np.fromstring(soundInfo,np.int16) f = fw.getframerate() fw.close() plt.subplot(211) plt.plot(soundInfo) plt.ylabel('Amplitude') plt.title('Wave from and spectrogram of test.wav') plt.subplot(212) plt.specgram(soundInfo,Fs = f, scale_by_freq = True, sides = 'default') plt.ylabel('Frequency') plt.xlabel('time(seconds)') plt.show()
- 语谱图更简单的绘制方法,可参考 scipy.signal.spectrogram。
- 语谱图绘制的原理,可参考 Create audio spectrograms with Python。
与其他的生物认证技术如指纹识别、人脸识别、虹膜识别等相同,声纹识别具有不会遗忘、无需记忆和使用方便等优点。在生物认证技术领域,说话人识别技术以其独特的方便性、经济性和准确性收到人们的广泛关注,并日益成为人们日常生活和工作中重要且普及的安全认证方式。
但是,说话人识别有着其他生物认证技术所不具有的优势:
用户接受度高:以声音作为识别特征,因其非接触性和自然醒,用户易接受。用户不用刻意的用手指触摸相应的传感器上,也不用将眼睛凑向摄像头,只需要简单的说一两句话即可完成识别认证。
设备成本低:对输入设备如麦克风,摄像头等没有特别的要求,特征提取,模型训练和匹配只需要普通的计算机即可完成。
其他生物认证特征技术各有其劣势:指纹识别需要特殊的传感器芯片,虹膜识别精确度较高,但是设备较为昂贵。
在远程应用和移动互联网环境下优势明显:通过电话、移动设备进行身份认证,声音是最具优势的生物特征,语音控制也逐渐成为流行的交互形式,以声音为特征的身份鉴别技术也越发重要。
1.2 声纹识别技术的历史
声纹识别技术的研究始于20世纪30年代,早期的工作主要集中于人耳听辨实验和探讨听音识别的可能性方面。随着研究手段和计算机技术的发展,研究工作逐渐脱离了单纯的人耳听辨,使得通过机器自动识别人的声音称为可能。在这个过程中也出现了很多不同的计算机技术,从早期的模板匹配到最新的深度学习技术,均在不断的刷新着语音识别技术手段。整体来看,声纹识别技术的发展经历了七个技术演进之路,详见下图(下图来自speakin):
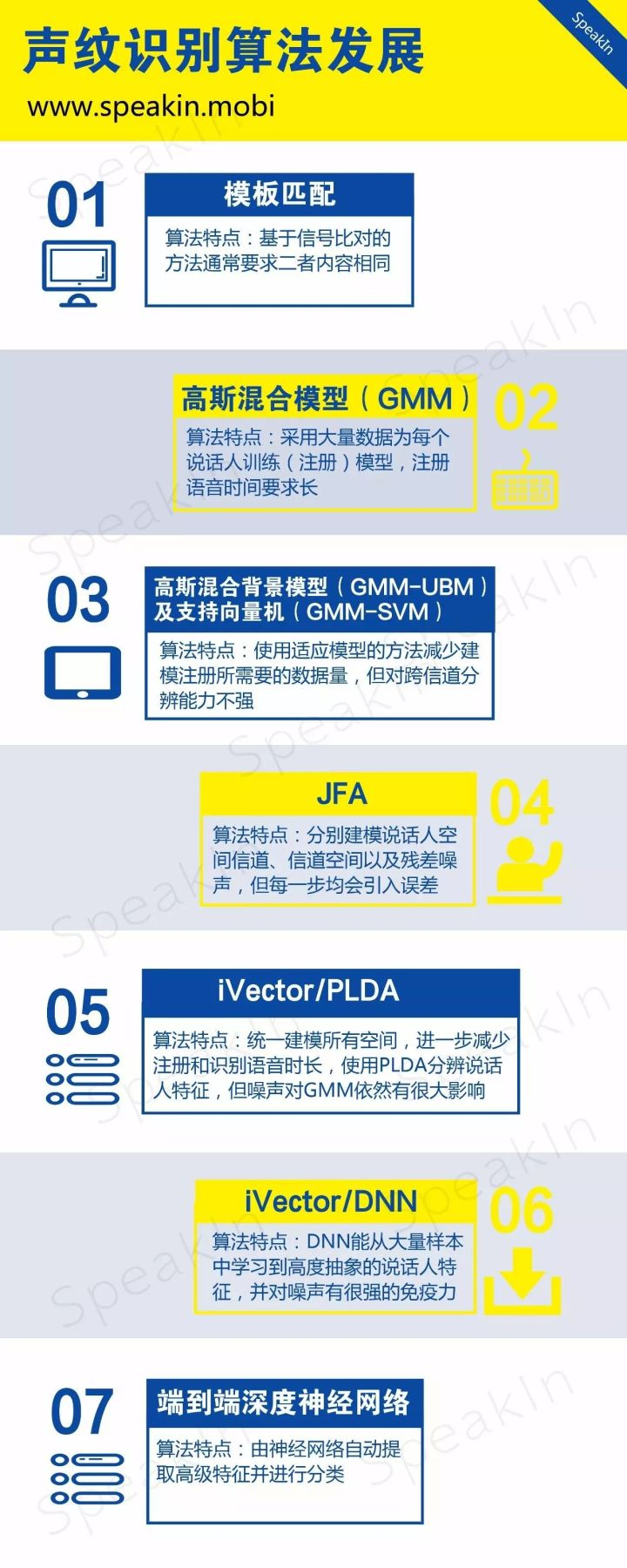
1.3 声纹识别的种类
声纹识别根据实际应用的范畴可以分为 1:1识别 和 1:N识别两种:
- 1:1识别:指确定待识别的一段语音是否来自其所声明的目标说话人,即确认目标说话人是目标说话人的过程。通常应用于电子支付、智能硬件、银行证券交易等。1:1识别有两个系统的性能评价参量,分别为
- 错误接受率(False Acceptation Rate, FAR):将非目标说话人判别为目标说话人造成的错误率
- 错误拒绝率(False Rejection Rate, FRR):将目标说话人误识成非目标说话人造成的错误率
- 对安全性要求越高,则设定阈值越高,此时接受目标说话人的条件越严格,即FRR越高,FAR越低;对用户体验要求越高,则设定阈值越低,此时接受目标说话人的条件越宽松,即FAR越高,FRR越低。在声纹系统中,可以通过设定不同的阈值来平衡FAR和FRR。
- 1:N识别:指判定待识别语音属于目标说话人模型集合中的哪一个人,即在N个人中找到目标说话人的过程。通常应用于公安司法、军队国防等。
2. 语音的特征提取方法概述
语音是一种数字信号,其数字⾳频的采样率为44100Hz(根据乃奎斯特取样定理得出的结果,在模拟讯号数字化的过程中,如果保证取样频率大于模拟讯号最高频率的2倍,就能100%精确地再还原出原始的模拟讯息。音频的最高频率为20kHz,所以取样率至少应该大于40kHz,为了留一点安全系数,再考虑到工程上的习惯,最终选择了44.1kHz这个数值)。通常情况下使用傅里叶变换将信号在时域与频域之间进行转换,而频谱图可以显示傅里叶变换后的振幅与时间和频率的对应关系。
2.1 特征提取方法
对于语音识别系统而言,所提取的特征参数需要能够反映特定发信的信息,在说话人无关的系统中,更要求参数能够反映不同说话人相同发音的信息,要求说话人的特征参数要能够代表特定的说话人,能够区分不同说话人相同语音之间的差异,最好能够做到与具体的发音内容无关,也称为文本无关。
在语音特征参数提取技术的发展历程中,线性预测编码(Linear Predictive Coding, LPC)被广泛应用于语音特征参数的提取,其中包括LPC系数、反射LPC系数、面积函数和LPC倒谱系数,能够很好的反映语音的声道特征,但是却对语音的其他特征无能为力。
不同于LPC等通过对人的发声机理进行研究而得到的声学特征,Mel倒谱系数MFCC是受人的听觉系统研究成果推出而导出的声学特征。根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉灵敏度。从200Hz到5000Hz的语音信号对语音的清晰度影响最大。人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种参数比基于声道模型的LPC相比具有更好的鲁棒性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
MFCC(MeI-Freguency CeptraI Coefficients)是需要语音特征参数提取方法之一,因其独特的基于倒谱的提取方式,更加的符合人类的听觉原理,因而也是最为普遍、最有效的语音特征提取算法。MFCC是在Mel标度频率域提取出来的倒谱系数,Mel标度描述了人耳对频率感知的非线性特性。
2.2 MFCC语音特征提取
MFCC 语音特征的提取过程,如下图:
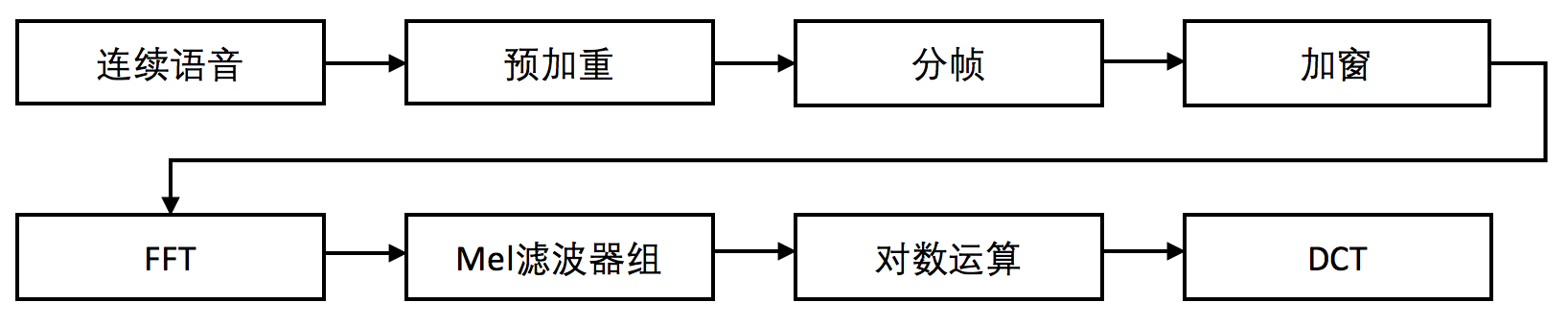
需要对语音信号进行预加重、分帧、加窗等等处理,而这些处理的方式均是为了能够最大化语音信号的某些信息,以达到最好特征参数的提取。
2.2.1 预加重
预加重其实就是将语音信号通过一个高通滤波器,来增强语音信号中的高频部分,并保持在低频到高频的整个频段中,能够使用同样的信噪比求频谱。在本实验中,选取的高通滤波器传递函数为: 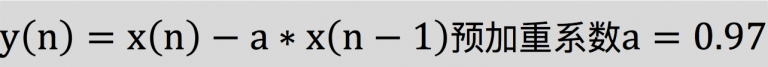
式中a的值介于0.9-1.0之间,我们通常取0.97。同时,预加重也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
def pre_emphasis(signal, coefficient=0.97): '''对信号进行预加重''' return numpy.append(signal[0], signal[1:] - coefficient * signal[:-1])
2.2.2 分帧
分帧是指在跟定的音频样本文件中,按照某一个固定的时间长度分割,分割后的每一片样本,称之为一帧,这里需要区分时域波形中的帧,分割后的一帧是分析提取MFCC的样本,而时域波形中的帧是时域尺度上对音频的采样而取到的样本。
分帧是先将N个采样点集合成一个观测单位,也就是分割后的帧。通常情况下N的取值为512或256,涵盖的时间约为20-30ms。也可以根据特定的需要进行N值和窗口间隔的调整。为了避免相邻两帧的变化过大,会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,一般M的值约为N的1/2或1/3。
语音识别中所采用的信号采样频率一般为8kHz或16kHz。以8kHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。本次实验中所使用的采样率(Frames Per Second)16kHz,窗长25ms(400个采样点),窗间隔为10ms(160个采样点)。
def audio2frame(signal, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))): '''分帧''' signal_length = len(signal) frame_length = int(round(frame_length)) frame_step = int(round(frame_step)) if signal_length <= frame_length: frames_num = 1 else: frames_num = 1 + int(math.ceil((1.0 * signal_length - frame_length) / frame_step)) pad_length = int((frames_num - 1) * frame_step + frame_length) zeros = numpy.zeros((pad_length - signal_length,)) pad_signal = numpy.concatenate((signal, zeros)) indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T indices = numpy.array(indices, dtype=numpy.int32) frames = pad_signal[indices] win = numpy.tile(winfunc(frame_length), (frames_num, 1)) return frames * win
2.2.3 加窗
在对音频进行分帧之后,需要对每一帧进行加窗,以增加帧左端和右端的连续性,减少频谱泄漏。在提取MFCC的时候,比较常用的窗口函数为Hamming窗。
假设分帧后的信号为 S(n),n=0,1,2…,N-1,其中N为帧的大小,那么进行加窗的处理则为:
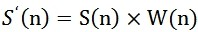
W(n)的形式如下:
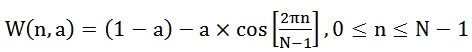
不同的a值会产生不同的汉明窗,一般情况下a取值0.46。进行值替换后,W(n)则为:

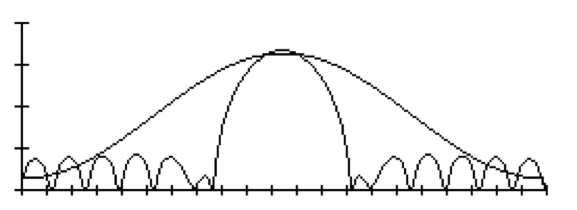
对应的汉明窗时域波形类似下图:
def deframesignal(frames, signal_length, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))): '''加窗''' signal_length = round(signal_length) frame_length = round(frame_length) frames_num = numpy.shape(frames)[0] assert numpy.shape(frames)[1] == frame_length, '"frames"矩阵大小不正确,它的列数应该等于一帧长度' indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T indices = numpy.array(indices, dtype=numpy.int32) pad_length = (frames_num - 1) * frame_step + frame_length if signal_length <= 0: signal_length = pad_length recalc_signal = numpy.zeros((pad_length,)) window_correction = numpy.zeros((pad_length, 1)) win = winfunc(frame_length) for i in range(0, frames_num): window_correction[indices[i, :]] = window_correction[indices[i, :]] + win + 1e-15 recalc_signal[indices[i, :]] = recalc_signal[indices[i, :]] + frames[i, :] recalc_signal = recalc_signal / window_correction return recalc_signal[0:signal_length]
2.2.4 对信号进行离散傅立叶变换 (DFT)
由于信号在时域上的变换通常很难看出信号的特性,所有通常将它转换为频域上的能量分布来观察,不同的能量分布,代表不同语音的特性。所以在进行了加窗处理后,还需要再经过离散傅里叶变换以得到频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。设语音信号的DFT为: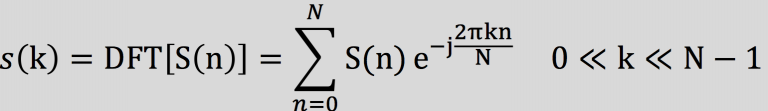
能量的分布为:
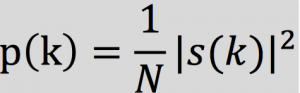
在本次实验中,采用DFT长度 N=512,结果值保留前257个系数。
def deframesignal(frames, signal_length, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))): '''加窗''' signal_length = round(signal_length) frame_length = round(frame_length) frames_num = numpy.shape(frames)[0] assert numpy.shape(frames)[1] == frame_length, '"frames"矩阵大小不正确,它的列数应该等于一帧长度' indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T indices = numpy.array(indices, dtype=numpy.int32) pad_length = (frames_num - 1) * frame_step + frame_length if signal_length <= 0: signal_length = pad_length recalc_signal = numpy.zeros((pad_length,)) window_correction = numpy.zeros((pad_length, 1)) win = winfunc(frame_length) for i in range(0, frames_num): window_correction[indices[i, :]] = window_correction[indices[i, :]] + win + 1e-15 recalc_signal[indices[i, :]] = recalc_signal[indices[i, :]] + frames[i, :] recalc_signal = recalc_signal / window_correction return recalc_signal[0:signal_length]
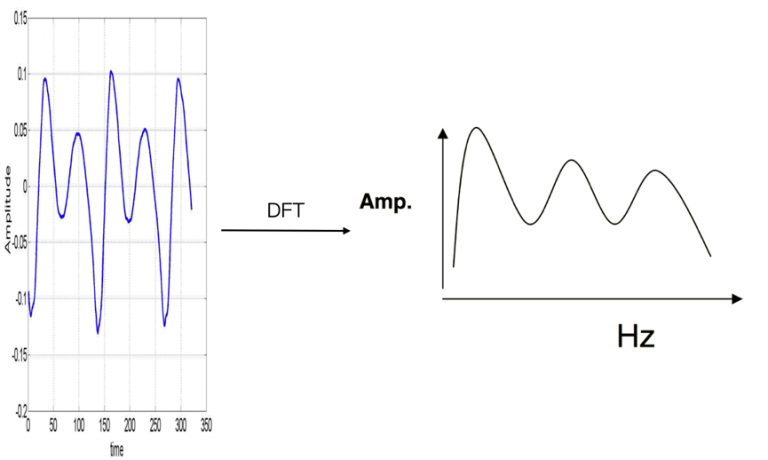
下图是有频谱到功率谱的转换结果示意图:
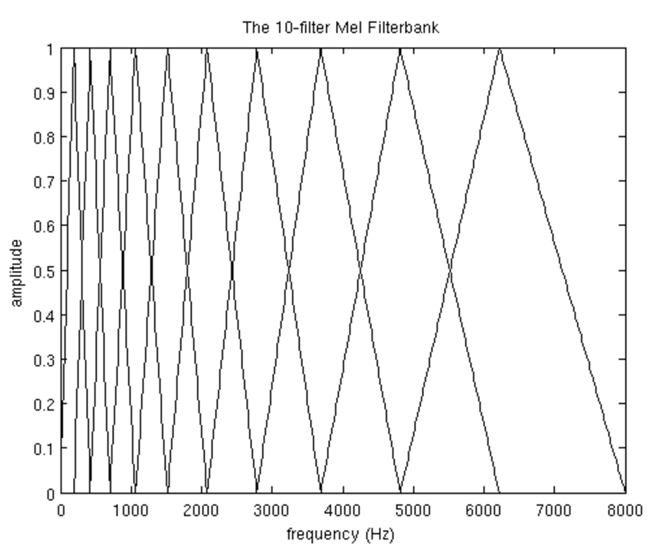
2.2.5 应用梅尔滤波器 (Mel Filterbank)
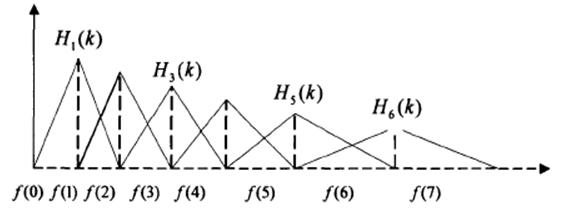
MFCC考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。 在Mel频域内,人对音调的感知度为线性关系。举例来说,如果两段语音的Mel频率相差两倍,则人耳听起来两者的音调也相差两倍。Mel滤波器的本质其实是一个尺度规则,通常是将能量通过一组Mel尺度的三角形滤波器组,如定义有M个滤波器的滤波器组,采用的滤波器为三角滤波器,中心频率为 f(m),m=1,2…M,M通常取22-26。f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图所示:
从频率到Mel频率的转换公式为:
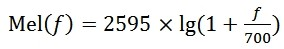
其中 f 为语音信号的频率,单位赫兹(Hz)。
def hz2mel(hz): '''把频率hz转化为梅尔频率''' return 2595 * numpy.log10(1 + hz / 700.0) def mel2hz(mel): '''把梅尔频率转化为hz''' return 700 * (10 ** (mel / 2595.0) - 1)
假如有10个Mel滤波器(在实际应用中通常一组Mel滤波器组有26个滤波器。),首先要选择一个最高频率和最低频率,通常最高频率为8000Hz,最低频率为300Hz。使用从频率转换为Mel频率的公式将300Hz转换为401.25Mels,8000Hz转换为2834.99Mels,由于有10个滤波器,每个滤波器针对两个频率的样点,样点之间会进行重叠处理,因此需要12个点,意味着需要在401.25和2834.99之间再线性间隔出10个附加点,如:
$$m(i) = 401.25,622.50,843.75,1065.00,1286.25,1507.50, 1728.74,1949.99,2171.24,2392.49,2613.74,2834.99$$
现在使用从Mel频率转换为频率的公式将它们转换回赫兹:
$$h(i) = 300,517.33,781.90,1103.97,1496.04,1973.32,2554.33, 3261.62,4122.63,5170.76,6446.70,8000$$
将频率映射到最接近的DFT频率: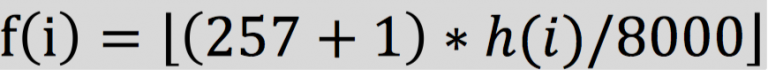
$$f(i) = 9,16,25,35,47,63,81,104,132,165,206,256$$
于是,我们得到了一个由10个Mel滤波器构成的Mel滤波器组。
def get_filter_banks(filters_num=20, NFFT=512, samplerate=16000, low_freq=0, high_freq=None): '''计算梅尔三角间距滤波器,该滤波器在第一个频率和第三个频率处为0,在第二个频率处为1''' low_mel = hz2mel(low_freq) high_mel = hz2mel(high_freq) mel_points = numpy.linspace(low_mel, high_mel, filters_num + 2) hz_points = mel2hz(mel_points) bin = numpy.floor((NFFT + 1) * hz_points / samplerate) fbank = numpy.zeros([filters_num, NFFT / 2 + 1]) for j in xrange(0, filters_num): for i in xrange(int(bin[j]), int(bin[j + 1])): fbank[j, i] = (i - bin[j]) / (bin[j + 1] - bin[j]) for i in xrange(int(bin[j + 1]), int(bin[j + 2])): fbank[j, i] = (bin[j + 2] - i) / (bin[j + 2] - bin[j + 1]) return fbank
2.2.6 对频谱进行离散余弦变换 (DCT)
在上一步的基础上使⽤离散余弦变换,即进⾏了⼀个傅⽴叶变换的逆变换,得到倒谱系数。
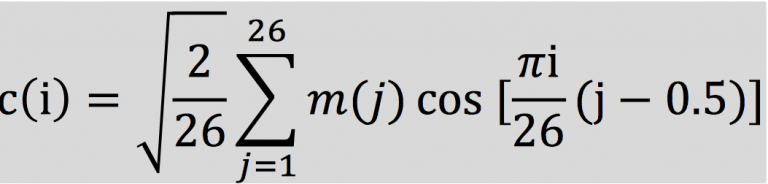
由此可以得到26个倒谱系数。只取其[2:13]个系数,第1个用能量的对数替代,这13个值即为所需的13个MFCC倒谱系数。
def lifter(cepstra, L=22): '''升倒谱函数''' if L > 0: nframes, ncoeff = numpy.shape(cepstra) n = numpy.arange(ncoeff) lift = 1 + (L / 2) * numpy.sin(numpy.pi * n / L) return lift * cepstra else: return cepstra
2.2.7 动态差分参数的提取(包括一阶微分系数和加速系数)
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。通常会把动、静态特征结合起来以有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
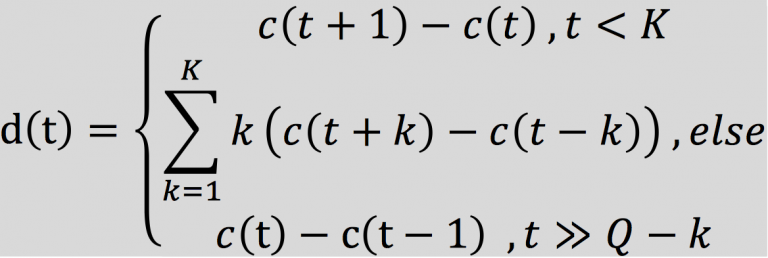
上式中,d(t)表示第t个一阶微分,c(t)表示第t个倒谱系数,Q表示倒谱系数的阶数,K表示一阶导数的时间差,可取1或2。将上式的结果再代入就可以得到加速系数。
⾄此,我们计算到了了⾳频⽂件每⼀帧的39个Mel频率倒谱系数(13个MFCC+13个一阶微分系数+13个加速系数),这些即为一个语音文件的特征数据,这些特征数据可以运用在之后的分类中。
def derivate(feat, big_theta=2, cep_num=13): '''计算一阶系数或者加速系数的一般变换公式''' result = numpy.zeros(feat.shape) denominator = 0 for theta in numpy.linspace(1, big_theta, big_theta): denominator = denominator + theta ** 2 denominator = denominator * 2 for row in numpy.linspace(0, feat.shape[0] - 1, feat.shape[0]): tmp = numpy.zeros((cep_num,)) numerator = numpy.zeros((cep_num,)) for t in numpy.linspace(1, cep_num, cep_num): a = 0 b = 0 s = 0 for theta in numpy.linspace(1, big_theta, big_theta): if (t + theta) > cep_num: a = 0 else: a = feat[row][t + theta - 1] if (t - theta) < 1: b = 0 else: b = feat[row][t - theta - 1] s += theta * (a - b) numerator[t - 1] = s tmp = numerator * 1.0 / denominator result[row] = tmp return result
3. 总结
本文针对语音数据的特征提取方法—MFCC进行了简单的概述和实践,MFCC是音频特征处理中比较常用而且很有效的方法。当特征数据提取出来之后,就可以进一步的进行数据的归一化、标准化,然后应用于机器学习、神经网络等等模型训练算法中,以得到能够识别语音类别的模型。在实际的应用中,可能还需要考虑很多的其他因素,例如源语音数据的采集方法、采集时长、模型的构建方式、模型的部署方式等等因素,因此需要根据业务的具体场景,来进行平衡取舍,以达到识别的时效性、准确性等。
目前关于语音识别相关的研究还在持续中,目标是能够最小化成本的在移动端部署语音识别相关的功能,提高SDK在人工智能方便的能力等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号