深度学习中的Normalization方法
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更新。为了训练好模型,我们需要谨慎初始化网络权重,调整学习率等。
本篇博客总结几种Normalization办法,并给出相应计算公式和代码。
将输入的feature map shape记为[Batch(N), Channel, Height, Width],这几个方法主要的区别就是在于:
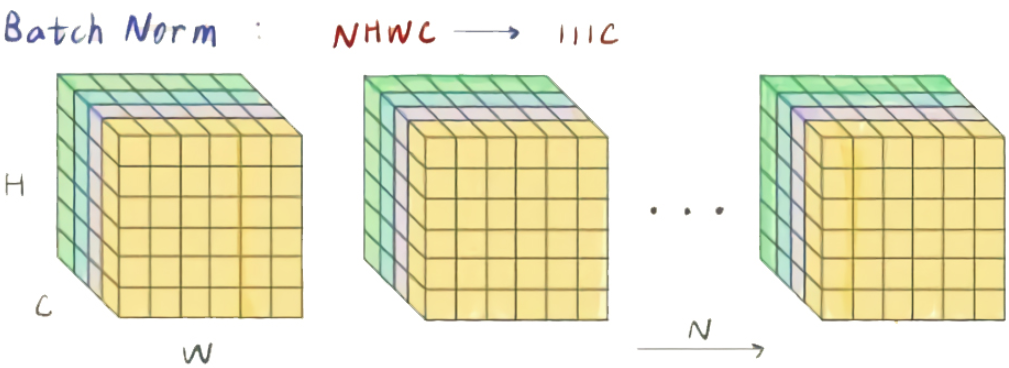
Batch Normalization(BN,2015年):沿batch方向上,对 (N、H、W) 做归一化,保留通道C的维度,
- 优点:适用于CNN
- 缺点:对较小的batch size效果不好,不适用于RNN
Layer Normalization(LN,2016年):沿Channel方向上,对 (C、H、W) 做归一化,保留通道N的维度
- 优点:适用序列模型,如:RNN
- 缺点:不适应输入变化很大的数据,大Batch较差
Instance Normalization(IN,2017年):在图像像素上,对 (H、W) 做归一化
- 优点:适用图像风格迁移
- 缺点:不适应通道之间的相关性较强数据
Group Normalization(GN,2018年):将channel分组,对 (C/G、H、W) 做归一化,在不同的Batch Size下具有较大的稳定性,而GN在中、大Batch Size下的性能略差于BN。
- 优点:不同Batch Size下具有较大的稳定性
- 缺点:在大Batch 下性能略差于BN
Switchable Normalization(SN,2018年):将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
- 优点:集BN、IN、LN优点于一身
- 缺点:训练复杂
Positional Normalization(PN,2019年):提出了位置归一化算法来计算生成网络沿信道维数的统计量;
- 优点:在生成网络中表现较好
- 缺点:不适应视觉任务
Batch Group Normalization(BGN,2020年):
- 优点:解决Batch Size退化和饱和的问题
- 缺点:暂不清楚
FRN(2020)
- 优点:不受batch size的影响。
- 缺点:暂不清楚
SaBN(2021)
- 优点:解决多类别不平衡问题
- 缺点:小批量它的性能会下降

立方体shape为(N, H, W, C)的像素点,N为batch size轴,C为通道轴。蓝色的像素群表示 使用这些像素值来计算平均值和方差进行归一化
Batch Normalization
提出原因
1、在训练神经网络过程中,通常输入batch个数据进行训练,这样每个batch具有不同的分布,使模型训练起来相对困难。
2、Internal Covariate Shift (ICS) 问题:在训练深层网络时,激活函数会改变各层数据的分布以及量级,随着网络的加深,这种改变会越来越大,模型不稳定不容易收敛,甚至可能出现梯度消失的问题。
那我们就看看下面的两个动图, 这就是在每层神经网络有无 batch normalization 的区别
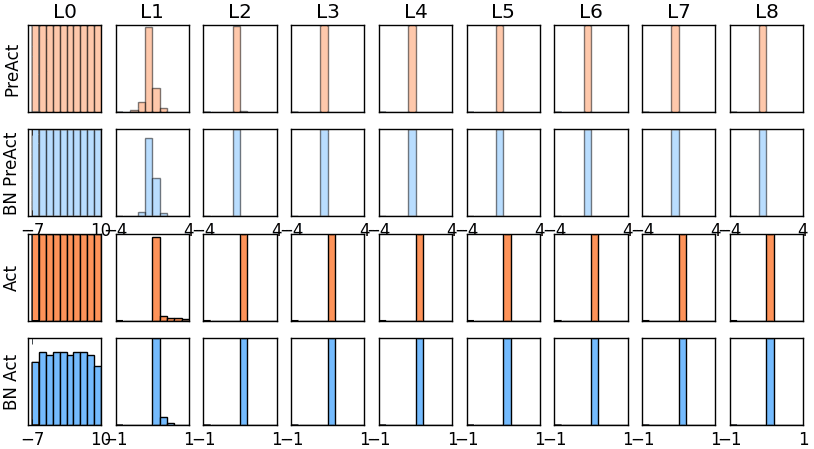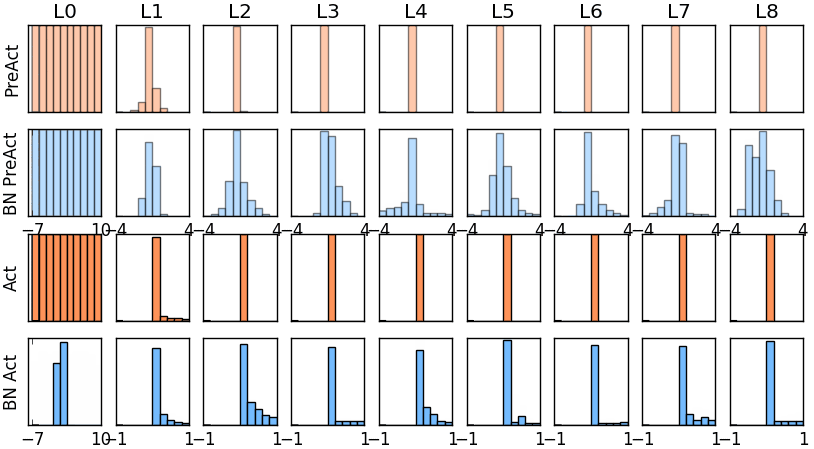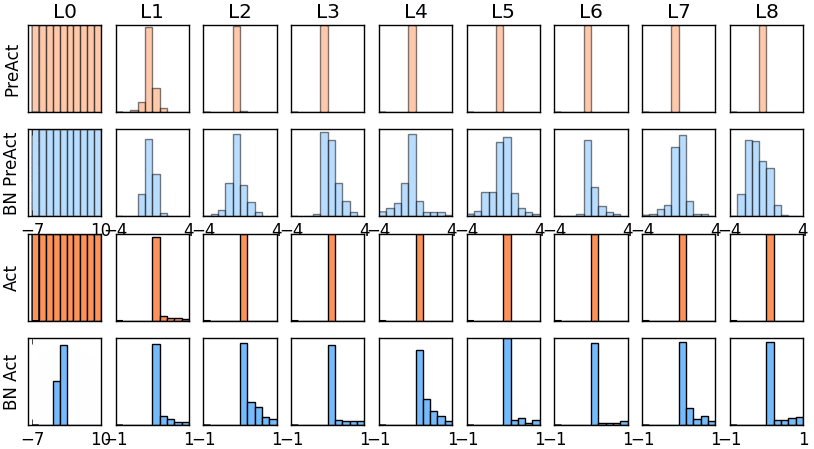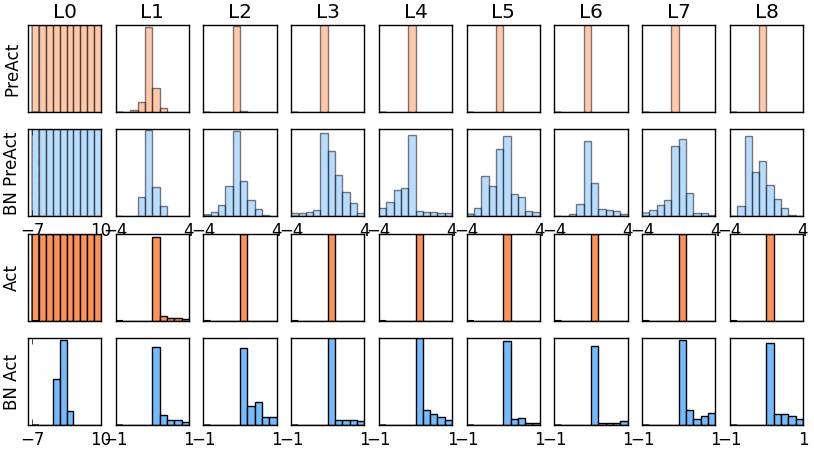
图* 没有BN的模型权值分布
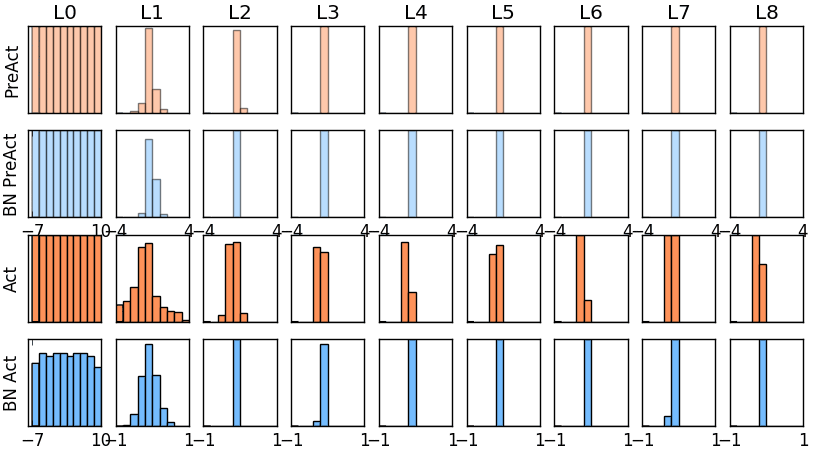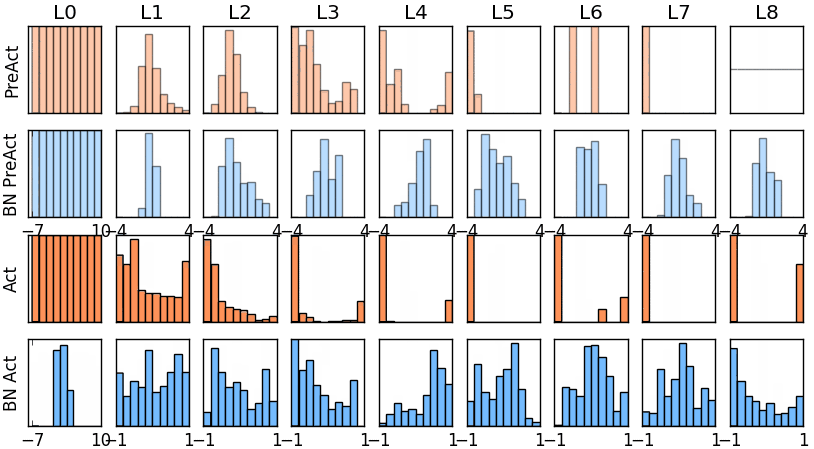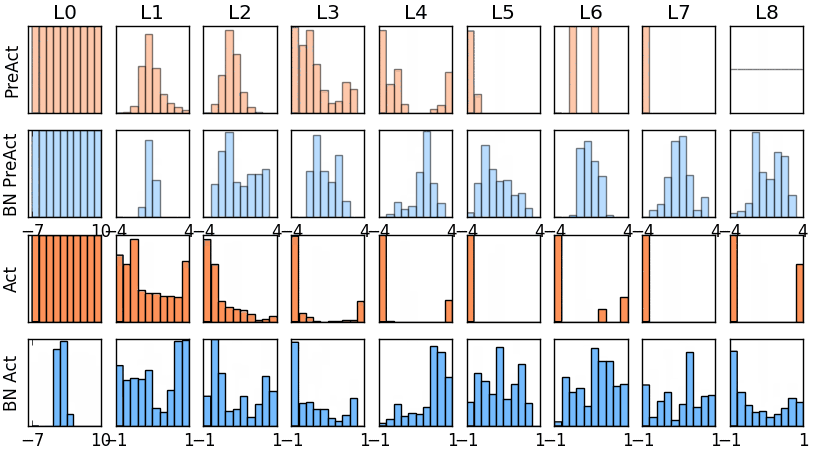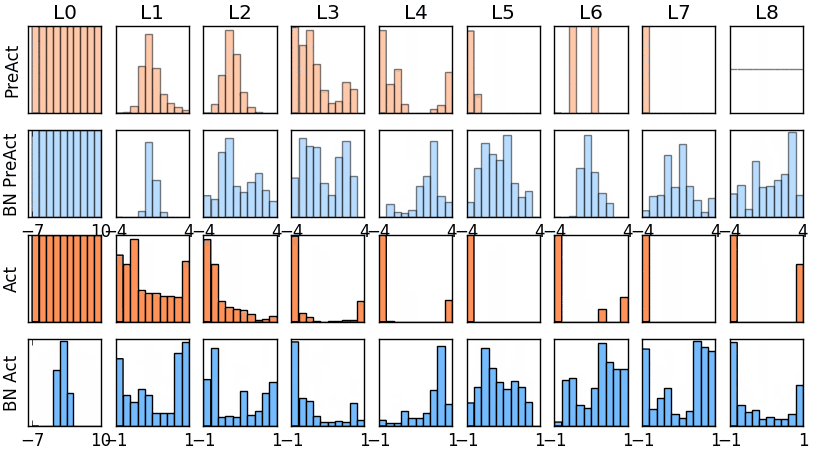
图* 使用BN的模型权值分布
没有normalization 的输出数据很多都等于0,导致后面的神经元“死掉”,起不到任何作用。
原理
BN的主要思想:沿着通道维度,在batch维度上,计算(N, H, W)均值和方差,然后对feature map进行归一化,这样不仅数据分布一致,而且避免发生梯度消失。保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。

其操作可以分成2步,
- Standardization:首先对$m$个$x$进行 Standardization,得到 zero mean unit variance的分布$\hat{x}$。
- scale and shift:然后再对$\hat{x}$进行scale and shift,缩放并平移到新的分布y,具有新的均值β方差γ。
假设BN层有d个输入节点,则x可构成d*m大小的矩阵X,BN层相当于通过行操作将其映射为另一个d*m大小的矩阵Y,如下所示
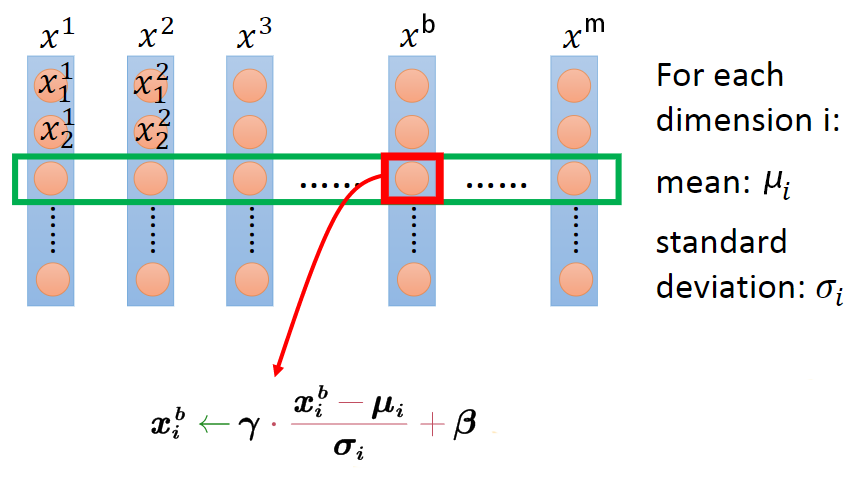
- $\mu$和$\delta $为当前行的均值和方差
- $\gamma $和$\beta$为可学习的scale和shift参数,用于控制$y_i$的方差和均值,在pytorch中由affine控制。
- BN层中,$x_i$和$x_j$之间不存在信息交流($i \neq j$)
$\epsilon $是一个很小的值,防止被除0。可见,无论原本的均值和方差是多少,通过BatchNorm后其均值和方差分别变为待学习的$\gamma $和$\beta$。
BN的使用:
BN的一个问题是训练时batch size一般较大,但是测试时batch size一般为1,而均值和方差的计算依赖batch,这将导致训练和测试不一致。BN的解决方案是在训练时候使用 移动平均用于估计全局均值和方差,以便在推理(测试)阶段使用。因为,在推理阶段,我们希望使用整个数据集的全局均值和方差,而不是某个特定mini-batch的统计量。
移动平均的计算方式: 移动平均通过以下公式更新全局均值和方差:
$$\hat{x}_{\text{new}} = (1 - \text{momentum}) \times \hat{x} + \text{momentum} \times x_t$$
- $x_t$:是当前min_batch的统计量
- $\hat{x}$:是当前移动平均的统计量
- momentum:动量参数,通常取值在0.01到0.1之间,用于控制移动平均的更新速度。注:torch的momentum等于tensorflow的1-momentum
BN的使用位置:激活函数之前,ResNet V1:conv>BN>Relu结构;resnet v2采用BN>Relu>conv结构。但无论如何都是在激活前使用BN。
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None) # 1维 torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None) # 2维
优点
- BN使得网络中每层输入数据的分布相对稳定,不仅极大提升了训练速度,收敛过程大大加快;
- BN使得模型对网络中的参数不那么敏感,减弱对初始化的强依赖性,简化调参过程,使得网络学习更加稳定
- BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
- 允许较大的学习率
- 有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout),能缓解 过拟合:深层网络容易过拟合,有时候dropout可能也解决不了。所以有时候BN可以替代dropout
缺点
1、如果Batch Size太小,则BN效果明显下降。
如果batch size太小,则计算的均值、方差不足以代表整个数据分布。小的 bath size 引入的随机性更大,难以达到收敛。对于一个比较大的模型,由于显存限制,batch size难以很大,比如目标检测模型,这时候BN层可能会成为一种限制。
2、如果batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;深度学习的优化(training loss降不下去)和泛化(generalization gap很大)都会出问题。可能会出现局部最优的情况
3、RNN等动态网络使用BN效果不佳且使用起来不方便
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于固定深度的前向神经网络(DNN,CNN)使用BN,很方便;
对于RNN来说,尽管其结构看上去是个静态网络,但在实际运行展开时是个动态网络结构,因为输入的Sequence序列是不定长的,这源自同一个Mini-Batch中的训练实例有长有短。对于类似RNN这种动态网络结构,BN使用起来不方便,因为要应用BN,那么RNN的每个时间步需要维护各自的统计量,而Mini-Batch中的训练实例长短不一,这意味着RNN不同时间步的隐层会看到不同数量的输入数据,而这会给BN的正确使用带来问题。假设Mini-Batch中只有个别特别长的例子,那么对较深时间步深度的RNN网络隐层来说,其统计量不方便统计而且其统计有效性也非常值得怀疑。另外,如果在推理阶段遇到长度特别长的例子,也许根本在训练阶段都无法获得深层网络的统计量。综上,在RNN这种动态网络中使用BN很不方便,而且很多改进版本的BN应用在RNN效果也一般。
4、例如图像分割这类任务,可能 batch size 只能是个位数,再大显存就不够用了。而当 batch size 是个位数时,BN 的表现很差,因为没办法通过几个样本的数据量,来近似总体的均值和标准差。GN 也是不依赖于batch。
5、对于有些像素级图片生成任务来说,BN效果不佳;
对于图片分类等任务,只要能够找出关键特征,就能正确分类,这算是一种粗粒度的任务,在这种情形下通常BN是有积极效果的。但是对于有些输入输出都是图片的像素级别图片生成任务,比如图片风格转换等应用场景,使用BN会带来负面效果,这很可能是因为在Mini-Batch内多张无关的图片之间计算统计量,弱化了单张图片本身特有的一些细节信息。
Layer Normalizaiton
Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
提出原因
前面介绍了Batch Normalization的原理,我们知道,BN层在CNN中可以加速模型的训练,并防止模型过拟合和梯度消失。但是,如果将BN层直接应用在RNN中可不可行呢,原则上也是可以的,但是会出现一些问题,因为我们知道Batch Normalization是基于mini batch进行标准化,在文本任务中(NLP),不同的样本其长度往往是不一样的,因此,如果在每一个时间步也采用Batch Normalization时,则在不同的时间步其规范化会强行对每个文本都执行,因此,这是不大合理的,另外,在测试时,如果一个测试文本比训练时的文本长度长时,此时Batch Normalization也会出现问题。因此,在RNN中,我们一般比较少使用Batch Normalization,但是我们会使用一种非常类似的做法,即Layer Normalization。
原理
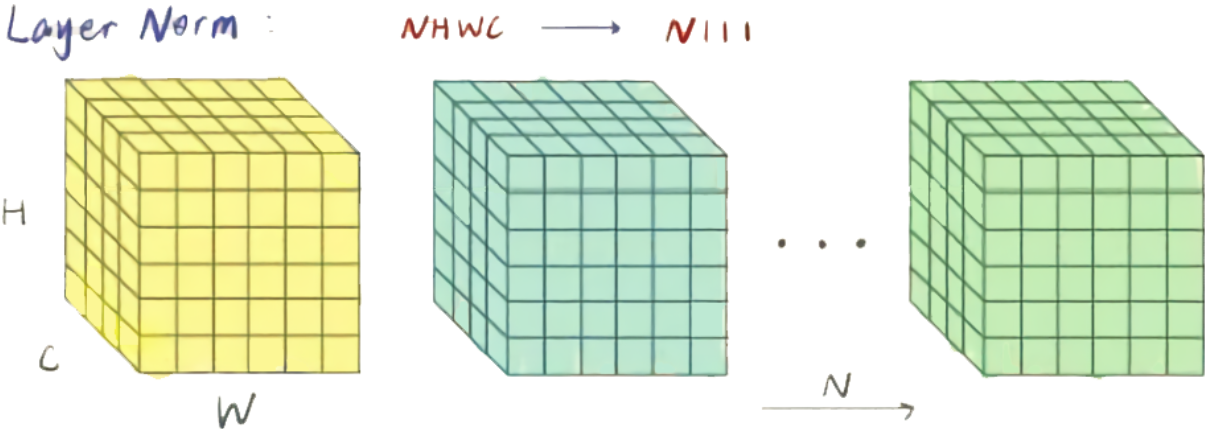
Layer Normalization的思想与Batch Normalization非常类似,只是Batch Normalization是在每个神经元对一个mini batch大小的样本进行规范化,而Layer Normalization则是在每一层对单个样本的所有神经元节点进行规范化,即C,W,H维度求均值方差进行归一化(当前层一共会求batch size个均值和方差,每个batch size分别规范化)。 LN 不需要批训练,在单条数据内部就能归一化。
计算过程:
- 沿着batch方向计算每个通道(C, H, W)的均值$\mu^l$和方差$\sigma ^l$
- 做归一化
- 加入缩放$\gamma$和平移$\beta$ 可学习变量
$$\mu_{n}(x)=\frac{1}{C H W} \sum_{c=1}^{C} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{n c h w}$$
$$\sigma_{n}(x)=\sqrt{\frac{1}{C H W} \sum_{c=1}^{C} \sum_{h=1}^{H} \sum_{w=1}^{W}\left(x_{n c h w}-\mu_{n}(x)\right)^{2}+\epsilon}$$
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)
优点
LN的一个优势就说不需要批训练。在单条数据内部就能完成归一化操作,因此可以用于batch_size=1和RNN训练中,在RNN中,使用Layer Normalization的效果要比Batch Normalization更优,不同的输入样本有不同的均值和方差,可以更快、更好地达到最优效果。LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
缺点
LN与batch size无关,在小batchsize上效果可能会比BN好,但是大batch size的话还是BN效果好。LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
Instance Normalization
提出原因
BN注重对batch size数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对HW维度进行归一化。
原理
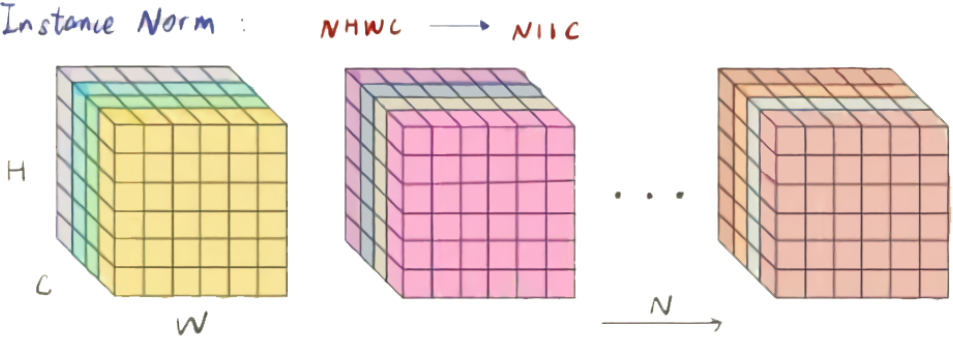
IN保留了N、C的维度,只在Channel内部对于H和W进行求均值和标准差的操作。
计算过程:
- 对于$x\in R^{N*C*H*W}$,IN 只对每个样本的 H、W 维度的数据求均值$\mu^l$和方差$\sigma ^l$,保留 N 、C 维度
- 做归一化
- 加入缩放$\gamma$和平移$\beta$ 可学习变量
$$\mu_{HW}=\frac{1}{H W} \sum_{l=1}^{W} \sum_{m=1}^{H} x$$
$$\sigma_{{HW}}^{2}=\frac{1}{H W} \sum_{l=1}^{W} \sum_{m=1}^{H}\left(x-\mu_{HW}\right)^{2}$$
$$y=\frac{x-\mu_{HW}}{\sqrt{\sigma_{HW}^{2}+\epsilon}}$$
优点
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个Batch进行Normalization操作并不适合图像风格化的任务,在风格迁移中适用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batch size 的影响
缺点
如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Group Normalization
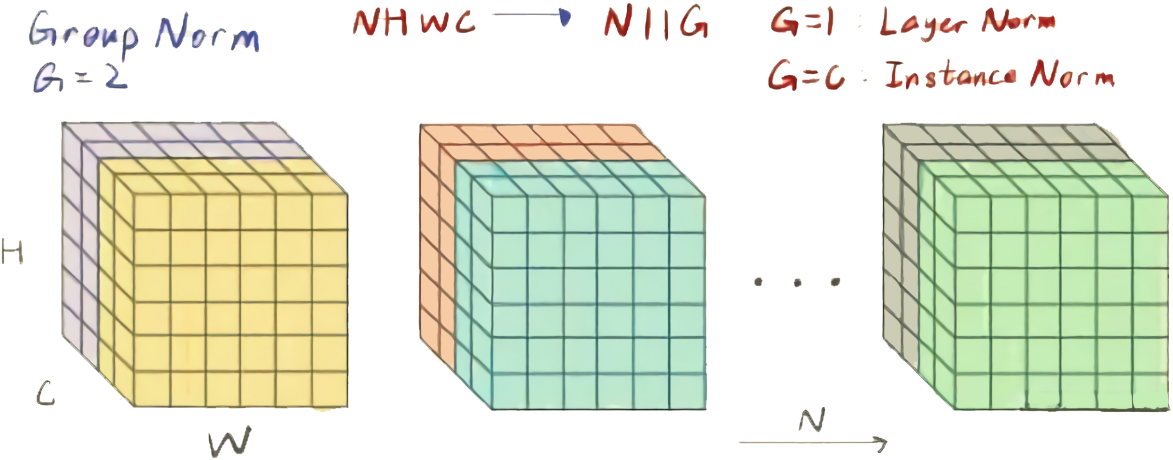
提出原因
GN是为了解决BN对较小的batch size效果差的问题。LN虽然不依赖batch size,但是在CNN中直接对当前层所有通道数据进行规范化也不太好。
BN在在batch上进行归一化时维度并不是固定不变的,就比如在训练时,它是通过在训练集上计算好归一化的值,而在测试时则会直接使用,但是训练集和测试集的数据分布存在偏差,就会存在不一致?GN计算步骤与BN一样,只不过与batch size大小无关。
论文中作者在ImageNet数据集上设置batch size为32和GN进行对比,结果发现在训练时候GN的表现要优于BN,但是在验证时却要比BN差一些。
原理
Group Normalization 将 channel 分成 num_groups组,每组包含channel / num_groups通道,则feature map变为(N, G, C//G, H, W),然后计算每组 (C//G, H, W)维度平均值和标准差。这样就与batch size无关,不受其约束。事实上,GN的极端情况就是LN和I N,分别对应G等于C和G等于1。
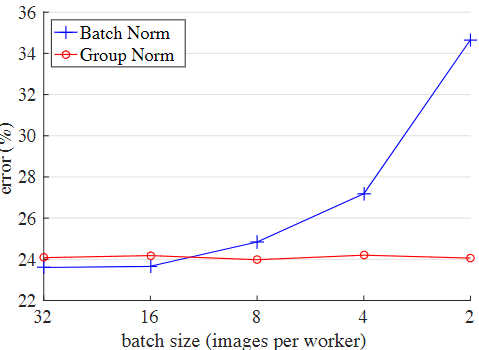
计算过程:
- 计算每组 (C//G, H, W)维度 均值$\mu^l$和方差$\sigma ^l$
- 做归一化
- 加入缩放$\gamma$和平移$\beta$ 可学习变量
$$\mu_{n g}(x)=\frac{1}{(C / G) H W} \sum_{c=g C / G}^{(g+1) C / G} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{n c h w}$$
$$\sigma_{n g}(x)=\sqrt{\frac{1}{(C / G) H W} \sum_{c=g C / G}^{(g+1) C / G} \sum_{h=1}^{H} \sum_{w=1}^{W}\left(x_{n c h w}-\mu_{n g}(x)\right)^{2}+\epsilon}$$
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True, device=None, dtype=None) def GroupNorm(x, gamma, beta, G, eps=1e-5): # x:input features with shape [N,C,H,W] # gamma,beta:scale and offset,with shape [1,C,1,1] # G:number of groups for GN N, C, H, W = x.shape x = tf.reshape(x, [N, G, C / G, H, W]) mean, var = tf.nn.moments(x, [2, 3, 4], keep_dims=True) x = (x - mean) / tf.sqrt(var + eps) x = tf.reshape(x, [N, C, H, W]) return x, gamma, beta
优点
GN不依赖Batch Size,同时还带来依然令人惊奇的效果。GN是在channel维度上进行的norm,可以很好适用于RNN,这是GN的巨大优势。虽然文中没做关于RNN的实验,但这无疑提供了一条新思路。
缺点
GN对比的BN并不是BN最强的状态。旷视科技提出的MegDet用了一种超大的batch size=256,BN效果比batch_size=32的时候好很多,并且顺便拿下COCO2017检测的冠军。
Switchable Normalization
Luo P, Ren J, Peng Z, et al. Differentiable learning-to-normalize via switchable normalization[J]. arXiv preprint arXiv:1806.10779, 2018.
提出原因
- 第一,归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
- 第二,一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
原理
SN使用可微分学习,将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
$$\hat{h}_{hcij}=\gamma \frac{h_{hcij}-\sum_{k\epsilon \Omega W_k\mu_k}}{\sqrt {\sum_{k\epsilon \Omega}w'_k\sigma _k^2+\epsilon }}+\beta $$
$$w_k=\frac{e^{\lambda _k}}{\sum_{z\epsilon \{in,ln,bn\}e^{\lambda _z}}},\quad k\in \{in,ln,bn\}$$
$$\mu_{in}=\frac{1}{HW}\sum_{i,j}^{H,W}h_{ncij},\quad \sigma ^2=\frac{1}{HW}\sum_{i,j}^{H,W}(h_{ncij}-\mu_{in})^2$$
$$\mu_{ln}=\frac{1}{C}\sum_{c=1}^{C}\mu_{in},\quad \sigma ^2_{ln}=\frac{1}{C}\sum_{c=1}^{C}(\sigma^2 _{in} +\mu ^2_{in})-\mu^2_{ln}$$
$$\mu_{bn}=\frac{1}{N}\sum_{n=1}^{N}\mu_{in},\quad \sigma ^2=\frac{1}{N}\sum_{n=1}^{N}(\sigma _{in}^2+\mu_{in}^2)-\mu_{bn}^2$$


def SwitchableNorm(x, gamma, beta, w_mean, w_var): # x_shape:[B, C, H, W] results = 0. eps = 1e-5 mean_in = np.mean(x, axis=(2, 3), keepdims=True) var_in = np.var(x, axis=(2, 3), keepdims=True) mean_ln = np.mean(x, axis=(1, 2, 3), keepdims=True) var_ln = np.var(x, axis=(1, 2, 3), keepdims=True) mean_bn = np.mean(x, axis=(0, 2, 3), keepdims=True) var_bn = np.var(x, axis=(0, 2, 3), keepdims=True) mean = w_mean[0] * mean_in + w_mean[1] * mean_ln + w_mean[2] * mean_bn var = w_var[0] * var_in + w_var[1] * var_ln + w_var[2] * var_bn x_normalized = (x - mean) / np.sqrt(var + eps) results = gamma * x_normalized + beta return results
结果比较
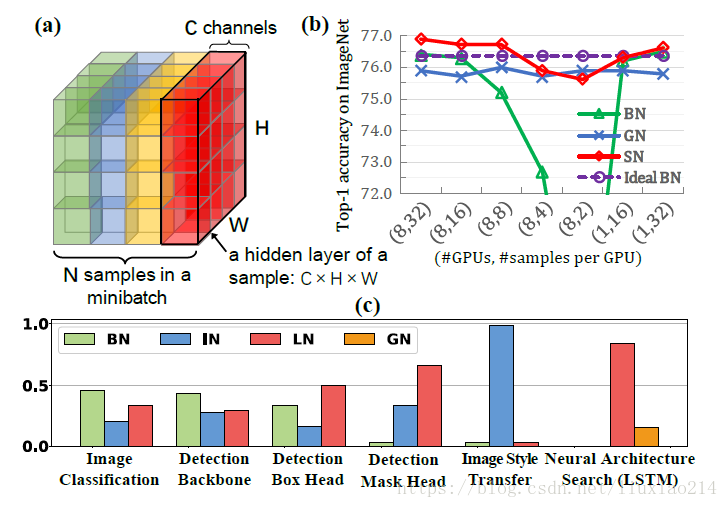
优点
SN是一种覆盖特征图张量各个维度来计算统计信息的归一化方法,不依赖batch size的同时对各个维度统计有很好的鲁棒性。 SN是一种能够有效适应不同任务地归一化方式。因此它同样适用于图像风格迁移、RNN、对抗生成网路。
缺点
集万千宠爱于一身,但训练复杂。
Positional Normalization
提出原因
作者提出,当前的BatchNorm, GroupNorm, InstanceNorm在空间层面归一化信息,同时丢弃了统计值。作者认为这些统计信息中包含重要的信息,如果有效利用,可以提高GAN和分类网络的性能。
原理
提出一种与众不同的跨通道的规范化方法 Positional Normalization (PONO),正如上面图中所示,提取到的均值和标准差能够捕获粗糙的结构信息。在生成模型的情况下, 这些信息必须在解码器中重新学习。相反, 建议直接将这两个矩信息 (均值和标准差) 注入到网络的后续层中,作者称之为矩捷径 (Moment Shortcut, MS) 连接。根据不同的规范化方案, 计算出其对应的 μ 和 σ,对X进行标准化,然后再应用仿射变换(其参数为 γ , β ) 得到后规范化 (post-normalized) 特征。 仿射变换的目的是保证每一次数据经过标准化后还保留原有学习来的特征,同时又能完成规范化操作,加速训练,并且这两个参数也是需要学习的。
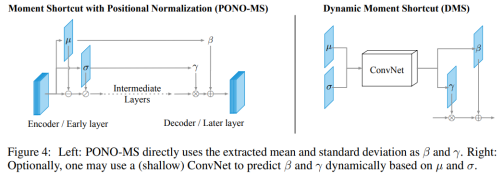
优点
用于数据增强,生成网络(GAN,图像去雾等),语义分割,图像分类等应用当中。
缺点
在视觉任务中表现较差
Batch Group Normalization
Zhou X Y, Sun J, Ye N, et al. Batch Group Normalization[J]. arXiv preprint arXiv:2012.02782, 2020.
提出原因
在以往的归一化方法中,批处理归一化(BN)在大、中批量处理中表现良好,对多个视觉任务具有很好的通用性,但在小批量处理中,其性能下降明显。作者实验发现在超大Batch下BN会出现饱和(比如,Batch为128),并提出在小/超大Batch下BN的退化/饱和是由噪声/混淆的统计计算引起的。
因此 作者在不增加新训练参数和引入额外计算的情况下,通过引入通道、高度和宽度维度来补偿,解决了批量标准化(BGN)在小/超大Batch下BN的噪声/混淆统计计算问题。
原理
BGN将通道通道、高度和宽度维度重新组合为一个维度,然后于batch维度重组特征组,计算各个特征组的均值和方差统计量,利用计算出的特征统计量对各特征组进行归一化,最后对归一化特征图进行重新缩放和位移,保持原来的特征形式。
参考:全面超越BN/GN/LN/IN!归一化新方法BGN,解决因Batch Size大小带来的训练不稳定问题
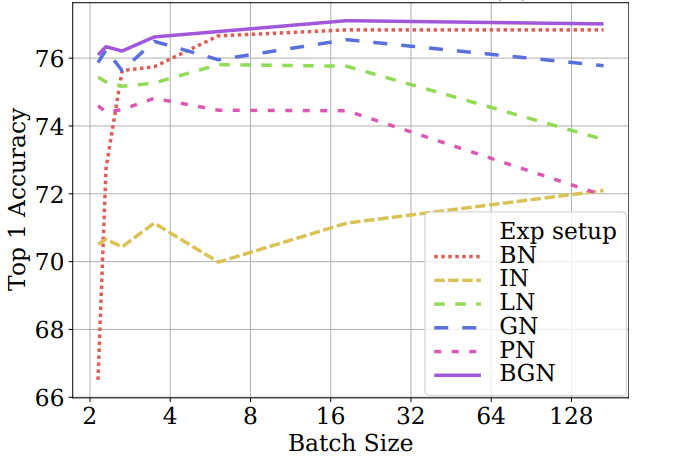
优点
解决Batch Size退化和饱和的问题。
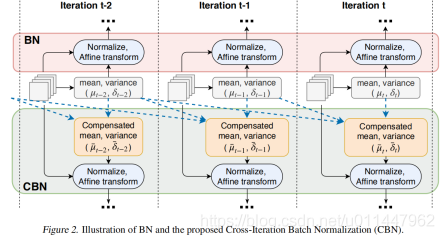
Cross-iteration BatchNorm
提出原因
随着BN的提出,现有的网络基本都在使用。但是在显存有限或者某些任务不允许大batch(比如检测或者分割任务相比分类任务训练时的batchsize一般会小很多)的情况下,BN效果就会差很多。为了改善小batch情况下网络性能下降的问题,有各种新的normalize方法被提出来了(LN、IN、GN),详情请看文章GN-Group Normalization。上述不同的normalize方式适用于不同的任务,其中GN就是为检测任务设计的,但是它会降低推断时的速度。
CBN原理
其思想其实很简单,既然从空间维度不好做,那么就从时间维度进行,通过以前算好的BN参数用来计算更新新的BN参数,从而改善网络性能,由于梯度迭代的属性,网络权重在一轮轮的迭代过程中缓慢改变,所以根据泰勒展开式可以估计出BN参数。
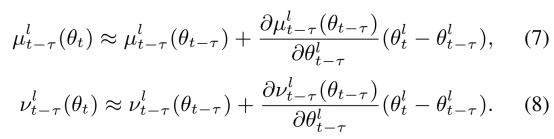
优点
CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销。目前广泛用于目标检测中效果较好,如yolov4。
缺点
模型训练的时候会慢一些,比GN还慢。
Filter Response Normalization
提出原因
目前主流的深度学习模型都会采用BN层(Batch Normalization)来加速模型训练以及提升模型效果,对于CNN模型,BN层已经上成为了标配。但是BN层在训练过程中需要在batch上计算中间统计量,这使得BN层严重依赖batch,造成训练和测试的不一致性,当训练batch size较小,往往会恶化性能。GN(Group Normalization)通过将特征在channel维度分组来解决这一问题,GN在batch size不同时性能是一致的,但对于大batch size,GN仍然难以匹敌BN。
原理
FRN旨在于消除batch size对于归一化的影响,但是不能牺牲BN在大的batch size上所获得性能。谷歌的提出的FRN层包括归一化层FRN(Filter Response Normalization)和激活层TLU(Thresholded Linear Unit),如下图所示。FRN层不仅消除了模型训练过程中对batch的依赖,而且当batch size较大时性能优于BN。
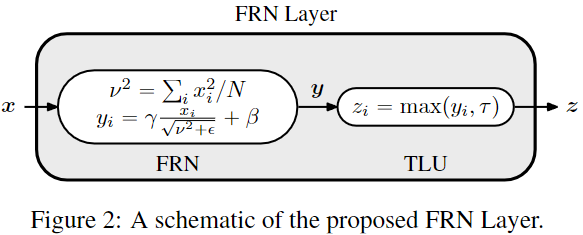
其中FRN的操作是(H, W)维度上的,即对每个样例的每个channel单独进行归一化,这里 x 就是一个N维度(HxW)的向量,所以FRN没有BN层对batch依赖的问题。BN层采用归一化方法是减去均值然后除以标准差,而FRN却不同,这里没有减去均值操作,公式中的 是x 的二次范数的平均值。这种归一化方式类似BN可以用来消除中间操作(卷积和非线性激活)带来的尺度问题,有助于模型训练。 公式里的epsilon是一个很小的正常量,以防止除0。
归一化之后同样需要进行缩放和平移变换,这里的gama和beta也是可学习的参数(参数大小为C)。FRN缺少去均值的操作,这可能使得归一化的结果任意地偏移0,如果FRN之后是ReLU激活层,可能产生很多0值,这对于模型训练和性能是不利的。为了解决这个问题,FRN之后采用的阈值化的ReLU,即TLU:
$$z=max(t,\tau)=ReLU(y-\tau)+\tau$$
这里的$\tau$是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的。

FRN优点
可以将TLU模型任意插入到其他归一化方法当中,且效果有明显的提升。不受batch size的影响。
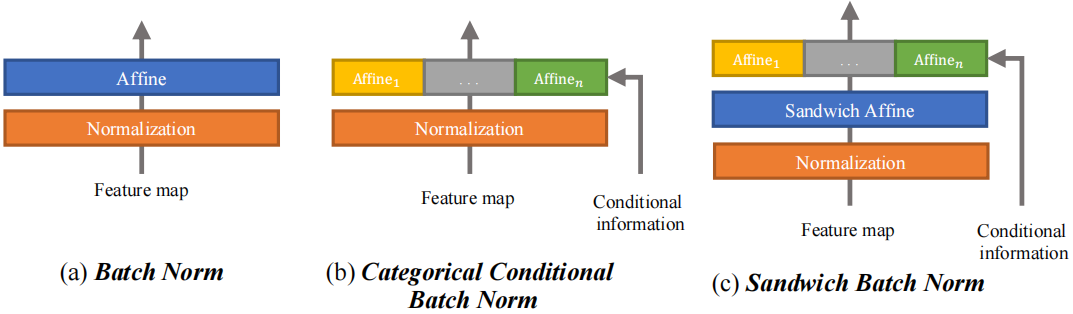
Sandwich Batch Normalization
Gong X, Chen W, Chen T, et al. Sandwich Batch Normalization[J]. 2020.
提出原因
- 一个 batch 里面不同类别的训练数据,放在一起做 Batch Normalization 不太妥当。因为不同类别的数据理应对应不同的均值和方差,其归一化、放缩、偏置也应该不同。
- 由于训练数据的每个类别变化很大,若单独/拆分特征层,会导致训练不平衡。降低收敛速度,阻碍整个网络训练。
原理
在BN的基础上加入分类的条件信息。对BN后的每个特征层通过多层感知机进行放射变换。其变换因子是由输入特征决定的,不同BN学习到的。
$$\mathbf{h}=\gamma_{i}\left(\gamma_{s a}\left(\frac{\mathbf{x}-\mu(\mathbf{x})}{\sigma(\mathbf{x})}\right)+\boldsymbol{\beta}_{s a}\right)+\boldsymbol{\beta}_{i}, i=1, \ldots, C$$
其它方法
EvalNorm、Moving Average BN、Adaptive Normalization、Square LN、Decorrelated BN、Spectral Normalization、BatchInstance Normalization(BIN)、Meta Normalization、Kalman Normalization(KN)、Categorical Conditional Batch Normalization(CCN)
Weight Normalization
原理
权重归一化(Weight Normalization)是将权值$W$分为一个方向分$v$量和一个范数分量$g$,使用优化器分别优化这两个参数。
$$w=\frac{g}{||v||}v$$
其中$v$是与$w$同维度的向量, $||v||$是欧氏范数,因此$v$是单位向量,决定了$w$的方向;$g$是标量,决定了$w$的长度。由于$||w||=|g|$,因此这一权重分解的方式将权重向量的欧氏范数进行了固定,从而实现了正则化的效果。
1)优化v(方向向量)。将 g 固定设为 ||w|| ,故这个向量和原来 w 范数相同但方向不同,方向是优化的对象,具体更新过程为:
$$\bigtriangledown _gL=\bigtriangledown _wL\frac{v}{||v||}$$
2)优化g(范数分量),将 v 固定,于是这个向量和原来 w 范数不同但方向相同,范数成为优化的对象,具体更新过程为:
$$\nabla_{v} L=\nabla_{w} L \cdot\left(\frac{g \cdot\|v\|}{\|v\|^{2}}-\frac{g v}{\|v\|^{2}} \cdot \frac{v}{\|v\|}\right)=\nabla_{w} L \cdot \frac{g}{\|v\|}-\nabla_{g} L \frac{g \cdot v}{\|v\|^{2}}$$
其中$\bigtriangledown_v||v||=\frac{v}{||v||}$,且没有引入超参数。
torch.nn.utils.weight_norm(module, name='weight', dim=0)
优点
WN的归一化操作作用在了权值矩阵之上。从其计算方法上来看,WN完全不像是一个归一化方法,更像是基于矩阵分解的一种优化策略,它带来的好处有:
- 更快的收敛速度;
- 更强的学习率鲁棒性;
- 可以应用在RNN等动态网络中;
- WN也是和样本量无关的,所以可以使用较小的batch size
- WN 的规范化不直接使用输入数据的统计量,因此避免了 BN 过于依赖 mini-batch 的不足,以及 LN 每层唯一转换器的限制,
- 另外BN使用的基于mini-batch的归一化统计量代替全局统计量,相当于在梯度计算中引入了噪声。而WN则没有这个问题,所以在生成模型,强化学习等噪声敏感的环境中WN的效果也要优于BN。
- WN没有一如额外参数,这样更节约显存。同时WN的计算效率也要优于要计算归一化统计量的BN。
缺点
说WN不像归一化的原因是它并没有对得到的特征范围进行约束的功能,所以WN依旧对参数的初始值非常敏感,这也是WN一个比较严重的问题
总结
BN通常可以在中、大批量中取得良好的性能。然而在小批量他的性能会下降比较多;GN在不同Batch Size下具有较大的稳定性,而GN在中、大Batch Size下性能略差于BN。IN、LN、PN、CBN在特定任务中表现良好,例如:IN在图像风格迁移中表现较好,LN在RNN中表现较好,PN在生成网络中表现较好,CBN在目标检测任务中较好,但这几个在其他视觉任务中泛化性能较差。SN集万千宠爱为一身,但训练过于复杂。FRN和BGN比其他归一化方法占据明显优势,但是目前还没大范围采用。
在这些归一化方法中,BN通常可以在中、大批量中取得良好的性能。然而,在小批量它的性能便会下降比较多;GN在不同的Batch Size下具有较大的稳定性,而GN在中、大Batch Size下的性能略差于BN。其他归一化方法,包括IN、LN和PN在特定任务中表现良好,但在其他视觉任务中泛化性比较差。
BGN:超大Batch下BN会出现饱和(比如,Batch为128),并提出在小/超大Batch下BN的退化/饱和是由噪声/混淆的统计计算引起的。因此,在不增加新训练参数和引入额外计算的情况下,通过引入通道、高度和宽度维度来补偿,解决了批量标准化在小/超大Batch下BN的噪声/混淆统计计算问题。
参考
【CSDN】BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
【CSDN】深度学习中的归一化方法总结(BN、LN、IN、GN、SN、PN、BGN、CBN、FRN、SaBN)
【深度学习技术前沿】常用 Normalization 方法总结与思考:BN、LN、IN、GN
【AI算法修炼营】来聊聊批归一化BN(Batch Normalization)层
【机器学习算法与自然语言处理】详解深度学习中的Normalization,BN/LN/WN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号