论文翻译:2017_Audio super resolution using neural networks
论文地址:使用神经网络的音频超分辨率
作者:Volodymyr Kuleshov, S. Zayd Enam, and Stefano Ermon
论文:Audio Super Resolution with Neural Networks
论文主页:https://kuleshov.github.io/audio-super-res/
代码: Github
博客作者:你逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/10592127.html
摘要
我们介绍了一种新的音频处理技术,该技术使用深度卷积神经网络来提高语音或音乐等信号的采样率。我们的模型在低质量和高质量音频对上训练;在测试时,他会预测低分辨率语音信号插值的过程中缺失的采样,就像图像超分辨率那样。我们的方法很简单,不涉及专门的音频处理技术;在我们的实验中,它在缩放比例2x、4x、6x处胜过标准语音和音乐测定基准的基线。该方法在电话、压缩和文本到语音生成方面具有实际应用价值;它证实了卷积架构在音频生成任务中的有效性。
1、引言
音频信号的生成建模是信号处理与机器学习交叉的一个基本问题;最近基于学习的算法使得语音识别(Hinton et al., 2012)、音频合成(van den Oord et al.,2016;Mehri et al.,2016)、音乐推荐系统(Coviello et al., 2012;Wang & Wang, 2014;Liang et al,2015),以及其他许多领域(Acevedo et al,2009)取得了进步。音频处理也提出了与时间序列和生成模型相关的基本研究问题(Haykin & Chen, 2005;Bilmes, 2004)。
基于机器学习的音频处理最重要的最新进展之一是能够利用神经网络直接对原始信号进行时域建模(van den Oord et al,2016;Mehri et al,2016)。尽管这为我们提供了最大的建模灵活性,但它的计算成本依然很高,要求我们每秒处理超过10000个音频样本。
在本文中,我们探索了一个新的轻量级音频建模算法。特别是,我们关注一个被称为带宽扩展的特定音频生成问题,其中的任务是从低质量音频重建高质量音频,下采样输入仅包含原始音频样本的一小部分(15-50%)。针对这一问题,我们引入了一种新的基于神经网络的技术,即激励图像超分辨率算法(Dong et al,2016),该算法使用机器学习技术将低分辨率图像插值为高分辨率图像。在这种情况下,基于学习的方法通常比一般用途的插值方案(如样条曲线)表现得更好,因为它们利用了自然信号出现的复杂特定域模型。
在图像超分辨率方面,我们的模型是对低质量和高质量的样本对进行训练的;在测试时,它预测低分辨率输入信号的缺失样本。与目前用于生成原始音频的神经网络不同,我们的模型是完全前馈的,可以实时运行。除了具有多种实际应用之外,我们的方法还提出了改进现有音频生成模型的新方法。
1.1 贡献
从实践的角度来看,我们的技术在电话、压缩、文本到语音生成、法医鉴定分析以及其他领域都有应用。它胜过在2x、4x和6x upscaling比例的基线,同时也比以前的方法简单得多。虽然大多数现有的音频增强方法都充分利用了信号处理理论,但我们的方法在概念上非常简单,不需要专门的知识来实现。我们的神经网络经过简单训练,可以将一个音频时间序列映射到另一个音频时间序列。我们的方法也是第一个使用卷积结构进行带宽扩展的方法;因此,相对于当前的替代方法,它可以更好地扩展数据集大小和计算资源。
从生成建模的角度来看,我们的工作证明了在非离散输出空间中运行的纯前馈架构可以在一个重要的音频生成任务上获得良好的性能。这暗示了设计改进的音频生成模型的可能性,结合前馈和递归组件。
2 设置与背景
音频处理:我们把音频信号表示为一个函数$s(t):[0,T]\rightarrow R$,其中T为信号的持续时间(秒),$s(t)$为$t$时刻的振幅,对$s$进行数字化测量需要将连续函数$s(t)$离散化成向量$x(t):\{\frac{1}{R},\frac{2}{R},...,\frac{RT}{R}\}\rightarrow R$。我们称$R$为$x$的采样率(Hz)。采样率从$4KHz$(低质量电话语音)到$44KHz$(高保真音乐)不等。
在这项工作中,我们把$R$解释为$x$的分辨率;我们的目标是通过从$\{\frac{1}{R},\frac{2}{R},...,\frac{RT}{R}\}$采集的样本中预测$x$来提高音频样本的分辨率。注意,根据基本信号处理理论,这相当于预测x的更高频率。
频带扩展:音频上采样是音频处理领域在“带宽扩展”下进行的一项研究(Ekstrand,2002;Larsen & Aarts,2005)。提出了几种基于学习的方法,包括高斯混合模型(Cheng et al,1994;Park & Kim,2000)和神经网络(Li et al,2015)。这些方法通常涉及手工制作的特征,并使用相对简单的模型(例如,具有最多2-3个紧密连接层的神经网络),这些模型通常是更大、更复杂系统的一部分。相比之下,我们的方法概念简单(直接在原始音频信号进行操作)、可扩展(我们的神经网络是完全卷积和完全前馈的)、更准确,而且也是少数在非语音音频上进行测试的方法之一。
3 方法
3.1 设置
给出一个低分辨率信号$x=\{{x_1}/{R_1},...,x_{R_1T_1/R_1}\}$采样率为$R_1$,我们的目标是重建高分辨率版本$y=\{y_1/R_2,...t_{R_2T_2/R_2}\}$的x,其采样率$R_2>R_1$。例如$x$可以是通过$4KHz$标准电话连接传输的语音信号。$y$是高分辨率$16KHz$重建。我们使用$r=R_2/R_1$表示两个信号的上采样率,在我们的工作中等于$r=2,4,6$。因此,我们期望$y_{rt/R_2}\approx x_{t/R_1}$,其中$t=1,2,...T_1R_1$。
为了恢复未定义的信号,我们学习了一个高分辨率$y$的模型$p(y|x)$,条件是它的低分辨率实例化$x$。我们假设时间序列x,y之间的关系遵循方程$y=f_\theta (x)+\epsilon$,其中$\epsilon \sim N(0,1)$是高斯噪声,$f_\theta$是由$\theta$参数化的模型。我们的框架还扩展到更复杂的噪声模型,用户可以将其作为先验模型提供,也可以由模型参数化。(类似于变分自动编码器中正态分布的参数化方法)。
上述公式自然会导致一个均方误差(MSE)目标:
$$l(D)=\frac{1}{n}\sqrt{\sum_{i=1}^n||y_i-f_\theta (x_i)||_2^2}$$
根据源/目标时间序列的数据集$D=\{x_i,y_i\}_{i=1}^n$确定参数$\theta$,由于我的模型是完全卷积的,我们可以将$x_i,y_i$作为全时间序列采样的小补丁。
3.2 模型架构
利用残差连接网络的深卷积神经网络对函数$f$进行参数化;我们的神经网络架构基于Shi等人的想法(2016),Dong等人(2016)和Isola等人(2016),如图1所示。我们在下面重点介绍它的主要特点。
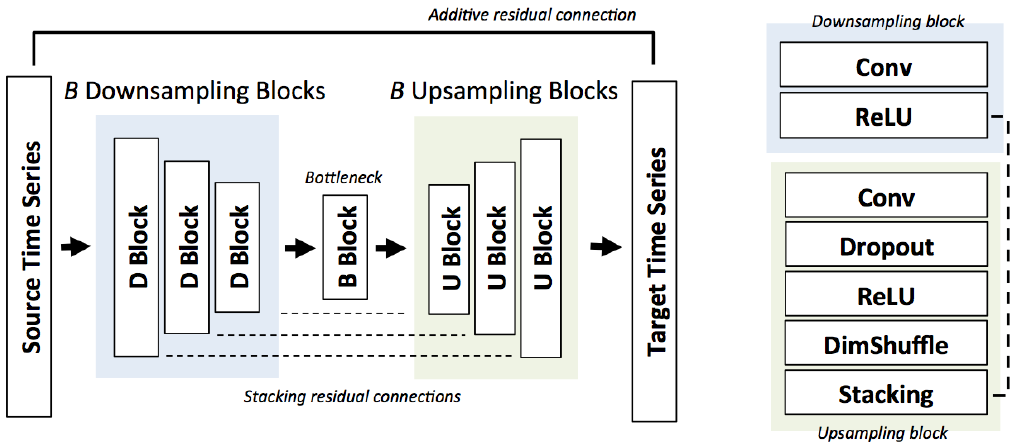
图1:用于音频超分辨率的深度残差网络。通过$B$个残差块提取特征;upscaling是通过堆叠的子像素(SubPixel)层完成的。

图2:使用频谱图可视化音频超分辨率。一个高质量的语音信号(最左边)在r=4时被下采样,导致高频丢失(从左边第二个)。我们使用经过训练的神经网络(最右边)来恢复丢失的信号,大大超过了三次样条插值基线(从右边数第二次)。
Bottleneck architecture(瓶颈结构).我们的模型包含B个连续的下采样和上采样块:每个块执行卷积、批处理归一化,并应用ReLu非线性激活函数。下采样块$b=1,2,...B$包含最大$(2^{2+b},512)$最小$(2^{7-b}+1,9)$length的卷积滤波器,步长为2。上采样块B的最大$(2^{7+(B-b+1)},512)$最小$(2^{7-(B-b+1)}+1,9)$length的卷积滤波器。
在下采样过程中,我们将feature map dimension减半,将滤波器size尺寸增加一倍;在上采样过程中,feature map维度扩大一倍,滤波器大小减小一半。这个瓶颈架构是受自动编码器的启发,并且众所周知,它鼓励模型学习层次特征。例如,在音频任务中,底层特征通常对应wavelet-style(小波风格) features, 高层特征对应phonemes(音素)(Aytar等人(2016))。注意,该模型是完全卷积的,可以在任意长度的输入序列上运行。
Skip connections(跳过连接).当源序列$x$与目标$y$相似时,下采样特性对向上采样也很有用(Isola et al., 2016)。因此,我们添加了额外的跳跃连接,将第b次下采样特征的张量与第(B-b+1)次上采样特征的张量叠加在一起。我们还添加了从输入到最终输出的附加残差连接:因此模型只需要学习y-x,这在实践中加快了训练速度。
Subpixel shuffling layer(子像素变换层).为了在upscaing过程中增加时间维度,我们实现了Shi等人(2016)的子像素层的一维版本。已经证明不太容易产生人工制品。
上采样块卷积将维度为$F x d$的输入张量映射成大小为$F/2 * d$的张量。子像素层将这个$F/2*d$张量重新洗牌(reshuffles)成另一个大小为$F/4*2d$大小的张量(同时保持Tensor项的完整性);这些特征与下采样阶段的F/4特征相连接,最终输出size尺寸为$F/2*2d$。因此,我们将滤波器数量减半,并将空间维度增加了一倍。
4 实验
数据集.我们使用VCTK数据集(Yamagishi),其中包含来自108个不同说话人的44小时数据和Mehri等人(2016)的钢琴数据集。(贝多芬奏鸣曲10小时)。我们通过应用8阶切比雪夫I型低通滤波器从16 kHz原始信号中生成低分辨率音频信号,然后再按期望的比例对信号进行二次采样。
我们在三种情况下评估我们的方法。单说话人任务在VCTK Speaker 1的前223段录音(约30分钟)上训练模型,并在最后8段录音上进行测试。多说话人任务我们对前99个VCTK说话人进行训练,并对剩下的8个说话人的语音进行测试;我们的录音具有不同的声音和口音(苏格兰、印度等),最后,钢琴任务将音频超分辨率扩展到非声乐数据;我们使用标准88%-6%-6%的数据分割。
方法.我们将我们的方法与两个基线进行了比较:一个三次B样条(对应于图像超分辨率中使用的双三次上采样基线)和 LI等人(2015)的最新神经网络技术。
后一种方法将输入的短时傅立叶变换(STFT)作为输入,利用具有三个隐藏层(尺寸2048)和非线性激活函数ReLU的密集神经网络直接预测高频分量的相位和幅度。Li等人(2015)的研究表明,在84%的用户研究中该方法优于高斯混合模型。该模型要求缩放比率为2的幂,因此当r=6时不适用。
我们用B=4 blocks 来实例化我们的模型,并使用学习率为$10^{-4}$的Adam优化器在长度为6000(在高分辨率空间)的patch补丁上训练它400个epoch周期。为了确保源/目标序列的长度相同,源输入将通过cubic upscaling向上缩放进行预处理。我们不与先前提出的矩阵分解技术进行比较(Bansal等人,2005;Liang等人,2013),因为他们通常是在<10个输入示例上训练的(Sun & Mazumder,2013)(由于联合分解大量矩阵的成本),并且不会扩展到我们数据集的大小。
度量
给定参考信号y和近似x,信噪比(SNR)定义为
$$SNR(x,y)=10\log \frac{||y||_2^2}{||x-y||_2^2}$$
信噪比是信号处理文献中常用的一种标准度量。对数谱距离(LSD) (Gray & Markel, 1976)测量单个频率的重建质量如下:
$$LSD(x,y)=\frac{1}{L}\sqrt{\frac{1}{K}\sum_{k=1}^K(X(l,k)-\hat{x}(l,k))^2}$$
其中$X$和$\hat{X}$分别为$y$和$x$的对数谱功率大小。这些定义为$X=\log |S|^2$,其中S是信号的短时傅里叶变换(STFT)。我们分别使用$l$和$k$索引帧和频率;在我们的实验中,我们使用了长度为2048的帧。
评估
我们的实验结果总结在表2中。我们的客观指标显示基线相比,有1-5dB的改善,在更高的上缩放因子下,改善幅度更大。虽然样条基线具有较高的信噪比,但其信号往往缺乏较高的频率;LSD度量可以的更好在识别这个问题。我们的技术也超过了DNN基线;我们的卷积体系结构似乎比密集的神经网络更有效地利用我们的建模能力,我们预计这种体系结构将很快在音频生成任务中得到更广泛的应用。

表2:在upscaling 比率 r=2,4,6的情况下,三种超分辨率任务中每种超分辨率方法的精度评估(单位:dB)
接下来,我们通过一项研究确认了我们的客观实验,在这项研究中,要求人类评分员使用MUSHRA(隐藏参考的多频刺激与和锚定)测试评估超分辨率音频的质量。对于每个试验都使用不同的技术对音频样本进行unscaled上缩放。我们从多说话人测试集收集了四个VCTK说话人录音的音频样本。对于每一段录音,我们收集原始的话语,一个$r=4$的下采样版本,以及使用样条、DNN和我们的模型(总共六个版本)超分辨率的信号。我们招募了10名评估者,并通过一项在线调查要求每个受试者按照0(非常差)到100(优秀)的重建范围给每个样本进行评分。实验结果如表1所示。我们的方法是为三种upscaling技术中最好的。
| 多说话人样本 | |||||
| 1 | 2 | 3 | 4 | Average | |
| ours | 69 | 75 | 64 | 37 | 61.3 |
| DNN | 51 | 55 | 66 | 53 | 56.3 |
| Spline | 31 | 25 | 38 | 47 | 25.3 |
表一:MUSHRA用户调研分数,我们显示每个样本的得分,每个用户的平均得分,还显示了所有样本的平均值
领域自适应:领域自适应(Domain Adaptation)是迁移学习中的一种代表性方法,指的是利用信息丰富的源域样本来提升目标域模型的性能。我们通过一个音频超分辨率实验测试了我们的方法对失配输入的敏感性,在这个实验中,训练集不使用低通滤波器,而测试集使用低通滤波器,反之亦然。我们专注于钢琴任务令r=2。模型的输出比预期更嘈杂,这表明泛化是一个重要的实际问题。我们怀疑这种行为可能在超分辨率算法中很常见,但尚未被广泛记载。一个潜在的解决方案是在 使用多种技术生成的数据 上进行训练。
此外,我们还检验了我们的模型从语音到音乐的泛化能力,反之亦然。我们发现交换域产生嘈杂的输出,这再次强调了模型的专门化。

表3:模型对低分辨率音频是否受低通滤波器(LPF)影响的灵敏度(单位:dB)
架构分析:我们通过使用$r=4$的upscaling比对多说话人音频超分辨率任务进行烧蚀分析,研究了各种架构设计选择的重要性。旁边的图形显示了结果:绿线显示原模型在验证集上随时间的$l_2$损失;黄线剔除了附加残差连接;绿色曲线进一步删除了附加的跳跃连接(同时保留相同的滤波器总数)。这表明,对称跳跃连接是获得良好性能的关键;附加连接增加了额外小的但可察觉的改进。

图3:r=4时,多说话人音频超分辨率模型ablation分析
计算性能:我们的模型计算效率高,可以实时运行。在钢琴任务中(所有输入信号的长度都是12秒),我们的方法在Titan X GPU上平均以0.11秒的速度处理一秒钟的音频。然而,训练我们的模型需要大约2天的时间来完成多说话人的任务。与序列到序列体系结构不同,我们的模型不需要完整的输入序列来开始生成输出序列。
4.1 局限性
最后,为了探索我们的方法的局限性,我们在MagnaTagATune数据集上评估了我们的方法,该数据集包含来自188种不同音乐流派的约200小时的音乐。这个数据集比我们目前所考虑的数据集更大、更多样化。我们发现我们的模型对数据集的拟合不足,训练误差几乎没有减少,也没有改善样条基线。其他基于学习的基线也有类似的结果。然而,我们期望使用更大的模型和更多的计算资源来改进结果。
5 前期工作与讨论
时间序列模型:在机器学习文献中,时间序列信号通常是用自回归模型建模的,其中循环网络的变体是一种特殊情况(Gers等人,2001;Maas等人,2012;mehri等人,2016)。相反,我们的方法概括了计算机视觉中用于图像超分辨率等任务的条件建模思想(Dong等人,2016;Ledig等人,2016)或图像着色(Zhang等人,2016)。
我们确定了一类广泛的条件时间序列建模问题,这些问题出现在信号处理、生物医学和其他领域,其特征是源/目标序列对之间的自然对齐,以及由局部转换很好地表示的差异。针对这些问题,我们提出了一种通用的体系结构,并表明它在不同的领域中都能很好地工作。
频带扩展:现有的基于学习的方法包括高斯混合模型(Cheng等人,1994;Park&Kim,2000;Pulakka等人,2011)、线性预测编码(Bradbury,2000)和神经网络(Li等人,2015)。我们的工作提出了第一个卷积体系结构,我们发现它可以更好地利用数据集大小进行扩展,并且优于近代的专门方法。此外,虽然现有的技术涉及许多手工制作的特征(参见Pulakka等人(2011);我们的方法完全与领域无关。
音频应用:在电话方面,商业化努力正在进行,以更高的速率(通常为16千赫)在特定的手机上传输语音;音频超级分辨率是在软件中重现这种体验的一个步骤。类似的应用可以在压缩、文本到语音生成和法医分析中找到。更一般地说,我们的工作证明了前馈卷积结构在音频生成任务上的有效性。
6 总结
基于深度神经网络的机器学习技术已经成功地解决了信号处理中的待定义问题,如图像的超分辨率、着色、绘画等。基于学习的方法在这种情况下往往比通用算法表现得更好,它们利用复杂的领域特有的自然信号模型。
在这项工作中,我们提出了新的技术,利用这种洞察力来上采样音频信号。我们的技术将之前的图像超分辨率工作扩展到音频领域;它在语音和非声乐方面都优于以前的带宽扩展方法。我们的方法快速和简单的实现,并且在电话、压缩和文本到语音生成方面有应用。它还证明了前馈结构对一个重要的音频生成任务的有效性,为生成音频建模提供了新的方向。
参考文献
1、Miguel A Acevedo, Carlos J Corrada-Bravo, H´ector Corrada-Bravo, Luis J Villanueva-Rivera, and T Mitchell Aide. Automated classification of bird and amphibian calls using machine learning: A comparison of methods. Ecological Informatics, 4(4):206–214, 2009.
2、Yusuf Aytar, Carl Vondrick, and Antonio Torralba. Soundnet: Learning sound representations from unlabeled video. In Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10,2016, Barcelona, Spain, pp. 892–900, 2016. URL http://papers.nips.cc/paper/6146-soundnet-learning-sound-representations-from-unlabeled-video.
3、Dhananjay Bansal, Bhiksha Raj, and Paris Smaragdis. Bandwidth expansion of narrowband speech using non-negative matrix factorization. In in Proc. Interspeech, 2005.Jeffrey A Bilmes. Graphical models and automatic speech recognition. In Mathematical foundations of speech and language processing, pp. 191–245. Springer, 2004.
4、Jeremy Bradbury. Linear predictive coding. Mc G. Hill, 2000.
5、Yan Ming Cheng, Douglas O’Shaughnessy, and Paul Mermelstein. Statistical recovery of wideband speech from narrowband speech. IEEE Transactions on Speech and Audio Processing, 2(4):544–548, 1994.
6、Emanuele Coviello, Yonatan Vaizman, Antoni B Chan, and Gert RG Lanckriet. Multivariate autoregressive mixture models for music auto-tagging. In ISMIR, pp. 547–552, 2012.
7、Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell., 38(2):295–307, February 2016.ISSN 0162-8828. doi: 10.1109/TPAMI.2015.2439281. URL http://dx.doi.org/10.1109/TPAMI.2015.2439281.
8、Per Ekstrand. Bandwidth extension of audio signals by spectral band replication. In in Proceedings of the 1st IEEE Benelux Workshop on Model Based Processing and Coding of Audio (MPCA02.Citeseer, 2002.
9、Felix A Gers, Douglas Eck, and J¨urgen Schmidhuber. Applying lstm to time series predictable through time-window approaches. In International Conference on Artificial Neural Networks, pp.669–676. Springer, 2001.
10、Augustine Gray and John Markel. Distance measures for speech processing. IEEE Transactions on Acoustics, Speech, and Signal Processing, 24(5):380–391, 1976.
11、Simon Haykin and Zhe Chen. The cocktail party problem. Neural computation, 17(9):1875–1902,2005.
12、Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly,Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine, 29(6):82–97, 2012.
13、Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
14、Erik Larsen and Ronald M Aarts. Audio bandwidth extension: application of psychoacoustics, signal processing and loudspeaker design. John Wiley & Sons, 2005.
15、Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew P. Aitken, Alykhan Tejani,Johannes Totz, ZehanWang, andWenzhe Shi. Photo-realistic single image super-resolution using a generative adversarial network. CoRR, abs/1609.04802, 2016. URL http://arxiv.org/abs/1609.04802.
16、Kehuang Li, Zhen Huang, Yong Xu, and Chin-Hui Lee. Dnn-based speech bandwidth expansion and its application to adding high-frequency missing features for automatic speech recognition of narrowband speech. In Sixteenth Annual Conference of the International Speech Communication Association, 2015.
17、Dawen Liang, Matthew D. Hoffman, and Daniel P. W. Ellis. Beta process sparse nonnegative matrix factorization for music. In Alceu de Souza Britto Jr., Fabien Gouyon, and Simon Dixon (eds.), Proceedings of the 14th International Society for Music Information Retrieval Conference, ISMIR 2013, Curitiba, Brazil, November 4-8, 2013, pp. 375–380,2013. ISBN 978-0-615-90065-0. URL http://www.ppgia.pucpr.br/ismir2013/wp-content/uploads/2013/09/229_Paper.pdf.
18、Dawen Liang, Minshu Zhan, and Daniel PW Ellis. Content-aware collaborative music recommendation using pre-trained neural networks. In ISMIR, pp. 295–301, 2015.
19、Andrew Maas, Quoc V. Le, Tyler M. ONeil, Oriol Vinyals, Patrick Nguyen, and Andrew Y. Ng.Recurrent neural networks for noise reduction in robust asr. In INTERSPEECH, 2012.
20、Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo,Aaron Courville, and Yoshua Bengio. Samplernn: An unconditional end-to-end neural audio generation model, 2016. URL http://arxiv.org/abs/1612.07837. cite arxiv:1612.07837.
21、Augustus Odena, Vincent Dumoulin, and Chris Olah. Deconvolution and checkerboard artifacts.Distill, 2016. doi: 10.23915/distill.00003. URL http://distill.pub/2016/deconv-checkerboard.
22、Kun-Youl Park and Hyung Soon Kim. Narrowband to wideband conversion of speech using gmm based transformation. In Acoustics, Speech, and Signal Processing, 2000. ICASSP’00. Proceedings.2000 IEEE International Conference on, volume 3, pp. 1843–1846. IEEE, 2000.
23、Hannu Pulakka, Ulpu Remes, Kalle Palom¨aki, Mikko Kurimo, and Paavo Alku. Speech bandwidth extension using gaussian mixture model-based estimation of the highband mel spectrum.In Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on,pp. 5100–5103. IEEE, 2011.
24、Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. pp. 1874–1883, 2016. doi: 10.1109/CVPR.2016.207.URL http://dx.doi.org/10.1109/CVPR.2016.207.
25、Dennis L. Sun and Rahul Mazumder. Non-negative matrix completion for bandwidth extension: A convex optimization approach. In IEEE International Workshop on Machine Learning for Signal Processing, MLSP 2013, Southampton, United Kingdom, September 22-25, 2013, pp. 1–6. IEEE,2013. doi: 10.1109/MLSP.2013.6661924. URL http://dx.doi.org/10.1109/MLSP.2013.6661924.
26、A¨aron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves,Nal Kalchbrenner, AndrewW. Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. CoRR, abs/1609.03499, 2016. URL http://arxiv.org/abs/1609.03499.
27、Xinxi Wang and Ye Wang. Improving content-based and hybrid music recommendation using deep learning. In Proceedings of the 22nd ACM international conference on Multimedia, pp. 627–636.ACM, 2014.
28、Junichi Yamagishi. English multi-speaker corpus for cstr voice cloning toolkit, 2012. URL http://homepages. inf. ed. ac.uk/jyamagis/page3/page58/page58. html.
29、Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. ECCV, 2016.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号