编码与乱码
一、各个计量单位
- 1B(Byte 字节) = 8bit(位):bit是表示信息的最小单位,只有两种状态:0和1。RGB图一个像素24bit,即3个字节一个像素。
- 1KB(千字节) = 1024B :一个Byte可以代表一个字元(A~Z)、数字(0~9)、符号(,。?!%&+-*/),是记忆体存储资料的基本单位,每个中文需要2个Byte。
- 1MB(兆字节)= 1024KB ;
- 1GB(吉字节)= 1024MB ;
- 1TB(太字节)= 1024GB ;
二、编码方式的区别(ASCII、Unicode、UTF-8)
- ASCII码一共定义了128个字符编码,主要利用指定的7位二进制数组合表示128种可能的字符,最前面的一位统一规定为0。比如A是65(01000001)
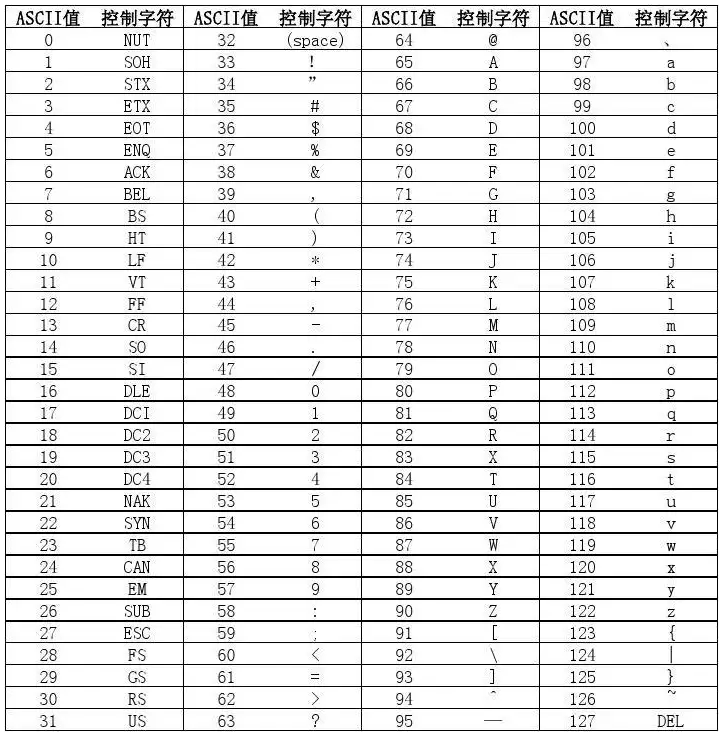
- GBK编码:
- 由于ASCII编码不支持中文,所以国人定义了一套编码规则:当字符小于127位时,与ASCII的字符相同,但当两个大于127的字符连接在一起时,就代表一个汉字,这个规则叫做GB2312。
- 但是由于中国汉字很多,有些字无法表示,于是重新定义了规则:不再要求低字节一定是127之后的编码,只要高字节是大于127,就固定表示这是一个汉字的开始。这种扩展之后的编码方案称之为GB18030。
- Unicode编码:
- 是为了解决不同国家的编码冲突,最常用的是用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。但是问题在于,原本用一个字节存储的英文字母在Unicode里面必须存两个字节,这就产生了浪费。
- UTF-8编码:是一种既能消除乱码,又能避免浪费的编码方式。
- 它是一种变长的的编码方式,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。当字符在ASCII码的范围时,就用一个字节表示。
- 值得注意的是Unicode编码中一个中文字符占2个字节,而UTF-8中一个中文字符占3个字节。从Unicode到UTF-8不是直接的对应,而是要用一些算法和规则来转换。
- 不同编程语言的编程方式不同,以下是一些常见编程语言的编码方式:
- C/C++:默认使用ASCII编码方式;
- C#:默认使用Unicode编码方式;
- Java:默认使用UTF-8编码方式;
- Python:默认使用UTF-8编码方式;
- JavaScript:默认使用UTF-8编码方式;
- Ruby:默认使用UTF-8编码方式;
-
- PHP:默认使用ISO-8859-1编码方式,但可以通过设置修改为其他编码方式;
三、乱码问题
- 出现古文夹杂日韩文,以GBK读取UTF-8编码
- 出现方块形,以UTF-8读取GBK
- 各种符号,以ISO8859-1方式读取UTF-8
- 拼音码,带声调的字母,以ISO8859-1方式读取GBK
- 长度为奇数时,最后的字符变成问号,以GBK读取UTF-8编码,再用UTF-8格式再次读取。
- 大部分文字为锟斤拷,以UTF-8方式读取GBK码,再次用GBK格式再次读取。

四、高字节与低字节
- 假如定义一个变量的地址是0x1234 5678,占用0x1234 5678与0x1234 5679两个字节存储空间,其中0x1234 5678是低字节,0x1234 5679是高字节。
- 一个16进制数有两个字节组成,如A9:高字节就是指16进制数的前8位(A),低字节就是指16进制的后8位(9)。
五、字符串与字节数组互转
1 string str = "你好,:。【】"+"Hello123"; 2 byte[] byteArray = System.Text.Encoding.UTF8.GetBytes(str); //将字符串转成字节数组 3 string strEncoding =4 Console.WriteLine("strEncoding = " + strEncoding); // strEncoding = 你好,:。【】"+"Hello123
注意:想要编码之后解码正确,需要确保编码方式一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号