Python-模块导入-63
模块导入:
# 内置模块 # 扩展的 django # 自定义的 # 文件 # import demo # def read(): # print('my read func') # demo.read() # print(demo.money) # 先从sys.modules里查看是否已经被导入 # 如果没有被导入,就依据sys.path路径取寻找模块 # 找到了就导入 # 创建这个模块的命名空间 # 执行文件,把文件中的名字都放到命名空间里
import sys print(sys.modules.keys()) # print(sys.path)
import time as t # 给一个模块起别名 print(t.time()) oracle # mysql # if 数据库 == ‘oracle’: # import oracle as db # elif 数据库 == ‘mysql’: # import mysql as db # # 连接数据库 db.connect # # 登录认证 # # 增删改查 # # 关闭数据库
3.1 import
示例文件:自定义模块my_module.py,文件名my_module.py,模块名my_module
#my_module.py print('from the my_module.py') money=1000 def read1(): print('my_module->read1->money',money) def read2(): print('my_module->read2 calling read1') read1() def change(): global money money=0 my_module模块
3.1.1
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句),如下
#demo.py import my_module #只在第一次导入时才执行my_module.py内代码,此处的显式效果是只打印一次'from the my_module.py',当然其他的顶级代码也都被执行了,只不过没有显示效果. import my_module import my_module import my_module ''' 执行结果: from the my_module.py ''' demo.py
我们可以从sys.modules中找到当前已经加载的模块,sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
3.1.2
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
#测试一:money与my_module.money不冲突 #demo.py import my_module money=10 print(my_module.money) ''' 执行结果: from the my_module.py ''' 测试一:money与my_module.money不冲突
#测试二:read1与my_module.read1不冲突 #demo.py import my_module def read1(): print('========') my_module.read1() ''' 执行结果: from the my_module.py my_module->read1->money 1000 ''' 测试二:read1与my_module.read1不冲突
#测试三:执行my_module.change()操作的全局变量money仍然是my_module中的 #demo.py import my_module money=1 my_module.change() print(money) ''' 执行结果: from the my_module.py ''' 测试三:执行my_module.change()操作的全局变量money仍然是my_module中的
3.1.3
总结:首次导入模块my_module时会做三件事:
1.为源文件(my_module模块)创建新的名称空间,在my_module中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2.在新创建的命名空间中执行模块中包含的代码,见初始导入import my_module

1 提示:导入模块时到底执行了什么? 2 3 In fact function definitions are also ‘statements’ that are ‘executed’; the execution of a module-level function definition enters the function name in the module’s global symbol table. 4 事实上函数定义也是“被执行”的语句,模块级别函数定义的执行将函数名放入模块全局名称空间表,用globals()可以查看
3.创建名字my_module来引用该命名空间
1 这个名字和变量名没什么区别,都是‘第一类的’,且使用my_module.名字的方式可以访问my_module.py文件中定义的名字,my_module.名字与test.py中的名字来自两个完全不同的地方。
3.1.4
为模块名起别名,相当于m1=1;m2=m1
1 import my_module as sm 2 print(sm.money)
示范用法一:
有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
#mysql.py def sqlparse(): print('from mysql sqlparse') #oracle.py def sqlparse(): print('from oracle sqlparse') #test.py db_type=input('>>: ') if db_type == 'mysql': import mysql as db elif db_type == 'oracle': import oracle as db db.sqlparse() 复制代码 示例用法1
示范用法二:
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如
if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date(filename) 示例用法2
3.1.5
在一行导入多个模块
1 import sys,os,re
导入模块的顺序:
# 内置模块
# 扩展的 django
# 自定义的
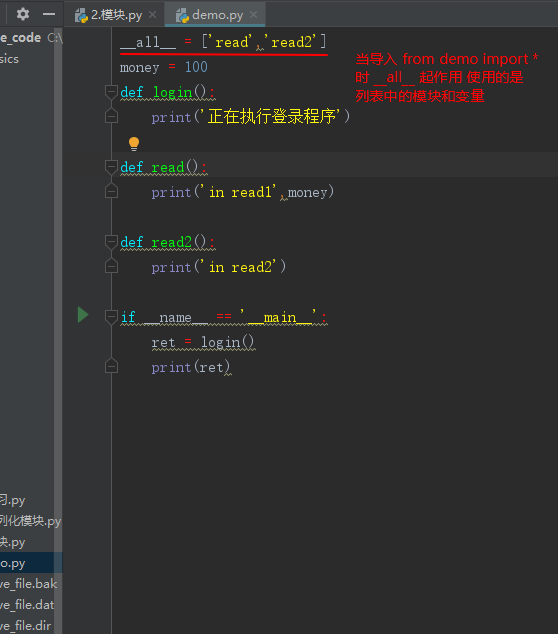
# import time,sys,os # from time import sleep # from demo import read # def read() : # print('my read') # read() # import demo # from demo import 变量名 # from demo import money,read # # print(money) # # read() # money = 200 # read() # from demo import money,read # # print(money) # # read() # money = 200 # read() # from time import * # # sleep = 10 # sleep(1) # from math import pi # print(pi) # pi = 3 # print(pi) # from demo import * # print(money) # read() # import demo # print(demo.money) # 所有的模块导入都应该尽量往上写 # 内置模块 # 扩展模块 # 自定义模块 # 模块不会重复被导入 : sys.moudles # 从哪儿导入模块 : sys.path #import # import 模块名 # 模块名.变量名 和本文件中的变量名完全不冲突 # import 模块名 as 重命名的模块名 : 提高代码的兼容性 # import 模块1,模块2 #from import # from 模块名 import 变量名 #直接使用 变量名 就可以完成操作 #如果本文件中有相同的变量名会发生冲突 # from 模块名 import 变量名字 as 重命名变量名 # from 模块名 import 变量名1,变量名2 # from 模块名 import * # 将模块中的所有变量名都放到内存中 # 如果本文件中有相同的变量名会发生冲突 # from 模块名 import * 和 __all__ 是一对 # 没有这个变量,就会导入所有的名字 # 如果有all 只导入all列表中的名字 # __name__ # 在模块中 有一个变量__name__, # 当我们直接执行这个模块的时候,__name__ == '__main__' # 当我们执行其他模块,在其他模块中引用这个模块的时候,这个模块中的__name__ == '模块的名字' # 绿茶 : 龙井 碧螺春 竹叶青 信阳毛尖 六安瓜片 太平猴魁 安吉白茶 # 白茶 : 福鼎白茶 银针(100%芽) 白牡丹(一芽一叶) 贡眉(一芽两叶) 寿眉(一芽三叶) # 黄茶 : 黄山毛峰 霍山黄芽 # 青茶 : # 乌龙茶 :铁观音,大红袍 # 包种 : 台湾包种 福建包种 # 红茶 : # 闵红 三功夫一小种 # 正山小种 : 金骏眉,银骏眉 # 政和功夫 # 坦洋功夫 # 白琳功夫 # 祁红 # 滇红 # 黑茶 : # 普洱 —— 云南 # 安化黑茶 —— 安徽
请你一定不要停下来 成为你想成为的人
感谢您的阅读,我是LXL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号