Part C
Part C 主要实现的是持久化,raft有三个persistent state:currentTerm,votedFor,log。这几个是无法再次重新计算出来,所以说它们是必须落盘的。
volatile state有nextIndex,matchIndex,lastApplied,commitIndex。这几个状态可以在此计算出来,就不需要落盘。
所以Part C只需要在persistent的三个state改变后及时落盘就行了,就是加上rf.persist()。persist()的实现就是按顺序将persistent state序列化落盘即可。
代码实现如下:
package raft
//
// this is an outline of the API that raft must expose to
// the service (or tester). see comments below for
// each of these functions for more details.
//
// rf = Make(...)
// create a new Raft server.
// rf.Start(command interface{}) (index, term, isleader)
// start agreement on a new log entry
// rf.GetState() (term, isLeader)
// ask a Raft for its current term, and whether it thinks it is leader
// ApplyMsg
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester)
// in the same server.
//
import (
"bytes"
"math"
"math/rand"
"sync"
"time"
)
import "sync/atomic"
import "../labrpc"
import "../labgob"
const (
Follower = iota
Candidate
Leader
ResetTimer
FlushState
)
//The tester requires that the leader send heartbeat RPCs no more than ten times per second.
const HeartBeatTimeout = time.Duration(100) * time.Millisecond
//
// as each Raft peer becomes aware that successive log entries are
// committed, the peer should send an ApplyMsg to the service (or
// tester) on the same server, via the applyCh passed to Make(). set
// CommandValid to true to indicate that the ApplyMsg contains a newly
// committed log entry.
//
// in Lab 3 you'll want to send other kinds of messages (e.g.,
// snapshots) on the applyCh; at that point you can add fields to
// ApplyMsg, but set CommandValid to false for these other uses.
//
type ApplyMsg struct {
CommandValid bool
Command interface{}
CommandIndex int
}
type Entry struct {
Term int
Command interface{}
}
//
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
majority int32
state int
flushCh chan int
// Persistent state on all servers
votedFor int
currentTerm int
log []Entry
// Volatile state on all servers
lastApplied int
commitIndex int
// Volatile state on leader
nextIndex []int
matchIndex []int
// tester commit channel
applyCh chan ApplyMsg
}
// return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isleader = rf.state == Leader
return term, isleader
}
//
// save Raft's persistent state to stable storage,
// where it can later be retrieved after a crash and restart.
// see paper's Figure 2 for a description of what should be persistent.
//
func (rf *Raft) persist() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
_ = e.Encode(rf.currentTerm)
_ = e.Encode(rf.votedFor)
_ = e.Encode(rf.log)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var log []Entry
if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil ||
d.Decode(&log) != nil {
} else {
rf.mu.Lock()
rf.currentTerm,rf.votedFor,rf.log = currentTerm,votedFor,log
rf.mu.Unlock()
}
}
type RequestVoteArgs struct {
Term int
CandidateId int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
Term int
VoteGranted bool
}
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.VoteGranted = false
if rf.currentTerm > args.Term {
//DPrintf("%d refuse RV from %d",rf.me,args.CandidateId)
return
}
if rf.currentTerm < args.Term {
rf.beFollower(args.Term)
}
// If votedFor is null or candidateId, and candidate’s log is at
// least as up-to-date as receiver’s log, grant vote
flag := args.LastLogTerm < rf.getLastLogTerm() || (args.LastLogTerm == rf.getLastLogTerm() && args.LastLogIndex < rf.getLastLogIdx())
if (rf.votedFor == -1 || rf.votedFor == args.CandidateId) && flag == false {
rf.votedFor = args.CandidateId
reply.VoteGranted = true
rf.state = Follower
rf.persist()
//vote granted reset timer
rf.flush(ResetTimer)
}
}
//
// example code to send a RequestVote RPC to a server.
// server is the index of the target server in rf.peers[].
// expects RPC arguments in args.
// fills in *reply with RPC reply, so caller should
// pass &reply.
// the types of the args and reply passed to Call() must be
// the same as the types of the arguments declared in the
// handler function (including whether they are pointers).
//
// The labrpc package simulates a lossy network, in which servers
// may be unreachable, and in which requests and replies may be lost.
// Call() sends a request and waits for a reply. If a reply arrives
// within a timeout interval, Call() returns true; otherwise
// Call() returns false. Thus Call() may not return for a while.
// A false return can be caused by a dead server, a live server that
// can't be reached, a lost request, or a lost reply.
//
// Call() is guaranteed to return (perhaps after a delay) *except* if the
// handler function on the server side does not return. Thus there
// is no need to implement your own timeouts around Call().
//
// look at the comments in ../labrpc/labrpc.go for more details.
//
// if you're having trouble getting RPC to work, check that you've
// capitalized all field names in structs passed over RPC, and
// that the caller passes the address of the reply struct with &, not
// the struct itself.
//
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []Entry
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
//The first index of the entry that conflicting
//with leader's log in a specific term
ConflictIndex int
//The term of such conflicting entries
ConflictTerm int
}
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.Success = false
reply.ConflictIndex = 0
reply.ConflictTerm = -1
if rf.currentTerm > args.Term {
//DPrintf("%d refuse AE from %d",rf.me,args.LeaderId)
return
}
if rf.currentTerm < args.Term {
rf.beFollower(args.Term)
}
prevLogTerm := -1
if args.PrevLogIndex >= 0 && args.PrevLogIndex < len(rf.log) {
prevLogTerm = rf.log[args.PrevLogIndex].Term
}
if prevLogTerm != args.PrevLogTerm {
reply.ConflictIndex = len(rf.log)
if prevLogTerm != -1 {
reply.ConflictTerm = prevLogTerm
for i:=0 ;i < len(rf.log);i++ {
if rf.log[i].Term == reply.ConflictTerm {
reply.ConflictIndex = i
break
}
}
}
rf.flush(ResetTimer)
return
}
//nextIndex match this server,start replicate log
index := args.PrevLogIndex
for i:=0 ;i < len(args.Entries);i++ {
index++
if index < len(rf.log) {
if rf.log[index].Term == args.Entries[i].Term {
continue
} else {
//If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it.
//The if here is crucial. If the follower has all the entries the leader sent, the follower MUST NOT truncate its log.
//Any elements following the entries sent by the leader MUST be kept. This is because we could be receiving an outdated AppendEntries RPC from the leader,
//and truncating the log would mean “taking back” entries that we may have already told the leader that we have in our log.
rf.log = rf.log[:index]
}
}
rf.log = append(rf.log,args.Entries[i:]...)
rf.persist()
break
}
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = int(math.Min(float64(args.LeaderCommit), float64(rf.getLastLogIdx())))
rf.applyMessage()
}
reply.Success = true
//DPrintf("%d accept AE from %d",rf.me,args.LeaderId)
rf.flush(ResetTimer)
}
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
//DPrintf("%d send AE to %d",rf.me,server)
return ok
}
//
// the service using Raft (e.g. a k/v server) wants to start
// agreement on the next command to be appended to Raft's log. if this
// server isn't the leader, returns false. otherwise start the
// agreement and return immediately. there is no guarantee that this
// command will ever be committed to the Raft log, since the leader
// may fail or lose an election. even if the Raft instance has been killed,
// this function should return gracefully.
//
// the first return value is the index that the command will appear at
// if it's ever committed. the second return value is the current
// term. the third return value is true if this server believes it is
// the leader.
//
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
index := -1
term := rf.currentTerm
isLeader := rf.state == Leader
if isLeader {
index = rf.getLastLogIdx() + 1
entry := Entry{
rf.currentTerm,
command,
}
rf.log = append(rf.log, entry)
rf.persist()
rf.matchIndex[rf.me] = rf.getLastLogIdx()
}
return index, term, isLeader
}
//
// the tester doesn't halt goroutines created by Raft after each test,
// but it does call the Kill() method. your code can use killed() to
// check whether Kill() has been called. the use of atomic avoids the
// need for a lock.
//
// the issue is that long-running goroutines use memory and may chew
// up CPU time, perhaps causing later tests to fail and generating
// confusing debug output. any goroutine with a long-running loop
// should call killed() to check whether it should stop.
//
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
}
func (rf *Raft) killed() bool {
z := atomic.LoadInt32(&rf.dead)
return z == 1
}
//Mass RPC to AppendEntries
func (rf *Raft) groupAppendLog() {
for pid := range rf.peers {
if pid != rf.me {
go func(idx int) {
for {
rf.mu.Lock()
if rf.state != Leader {
rf.mu.Unlock()
return
}
args := &AppendEntriesArgs{
rf.currentTerm,
rf.me,
rf.getPrevLogIdx(idx),
rf.getPrevLogTerm(idx),
append(make([]Entry, 0), rf.log[rf.nextIndex[idx]:]...),
rf.commitIndex,
}
//should not holding the lock while calling RPC
rf.mu.Unlock()
reply := &AppendEntriesReply{}
ok := rf.sendAppendEntries(idx, args, reply)
rf.mu.Lock()
//Term change or RPC fail, return
if !ok || rf.state != Leader || rf.currentTerm != args.Term {
rf.mu.Unlock()
return
}
//If RPC request or response contains term T > currentTerm
//set currentTerm = T,convert to follower
if reply.Term > rf.currentTerm {
rf.beFollower(reply.Term)
rf.mu.Unlock()
return
}
if reply.Success {
//Append Entries success, update the matchIndex and nextIndex for the follower
rf.matchIndex[idx] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[idx] = rf.matchIndex[idx] + 1
rf.checkCommit(idx)
rf.mu.Unlock()
return
} else {
shouldMoveTo := reply.ConflictIndex
if reply.ConflictTerm != -1 {
for i:= 0; i < len(rf.log); i++ {
if rf.log[i].Term != reply.ConflictTerm {
continue
}
for i < len(rf.log) && rf.log[i].Term == reply.ConflictTerm {
i++
}
shouldMoveTo = i
}
}
rf.nextIndex[idx] = shouldMoveTo
rf.mu.Unlock()
//should not return here,wait for next reply
//to ensure follower was replicated successfully
}
}
}(pid)
}
}
}
//Mass RPC to RequestVote
func (rf *Raft) kickoffElection(args *RequestVoteArgs) {
//vote counter,start from 1
var votes int32 = 1
for pid := range rf.peers {
if pid != rf.me {
go func(idx int) {
reply := &RequestVoteReply{}
ret := rf.sendRequestVote(idx, args, reply)
if ret {
rf.mu.Lock()
defer rf.mu.Unlock()
//If RPC request or response contains term T > currentTerm
//set currentTerm = T, convert to follower
if reply.Term > rf.currentTerm {
rf.beFollower(reply.Term)
return
}
if rf.state != Candidate || rf.currentTerm != args.Term {
return
}
if reply.VoteGranted {
atomic.AddInt32(&votes, 1)
if atomic.LoadInt32(&votes) > rf.majority {
rf.beLeader()
//DPrintf("%d step into leader" ,rf.me)
//be leader,flush state and start heartbeat
rf.flush(FlushState)
}
}
}
}(pid)
}
}
}
func (rf *Raft) beFollower(term int) {
rf.state = Follower
rf.votedFor = -1
rf.currentTerm = term
rf.persist()
//DPrintf("%d convert to follower",rf.me)
}
func (rf *Raft) beCandidate() {
rf.state = Candidate
rf.currentTerm++
rf.votedFor = rf.me
rf.persist()
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: rf.getLastLogIdx(),
LastLogTerm: rf.getLastLogTerm(),
}
go rf.kickoffElection(&args)
}
func (rf *Raft) beLeader() {
//weather it still candidate
if rf.state != Candidate {
return
}
rf.state = Leader
rf.nextIndex = make([]int, len(rf.peers))
rf.matchIndex = make([]int, len(rf.peers))
for i := 0;i < len(rf.nextIndex);i++ {
rf.nextIndex[i] = len(rf.log)
}
}
//case 1:receive AppendEntries RPC from current leader or granting vote to candidate,reset timer
//case 2:step into leader and start heartbeat,jump out of select section in ticker() to flush leader state
func (rf *Raft) flush(behaviour int) {
select {
case <- rf.flushCh:
default:
}
rf.flushCh <- behaviour
//DPrintf("%d reset",rf.me)
}
//helper function
func (rf *Raft) getLastLogIdx() int {
return len(rf.log) - 1
}
func (rf *Raft) getLastLogTerm() int {
index := rf.getLastLogIdx()
if index < 0 {
return -1
}
return rf.log[index].Term
}
func (rf *Raft) getPrevLogIdx(idx int) int {
return rf.nextIndex[idx] - 1
}
func (rf *Raft) getPrevLogTerm(idx int) int {
prevLogIndex := rf.getPrevLogIdx(idx)
if prevLogIndex < 0 {
return -1
}
return rf.log[prevLogIndex].Term
}
func (rf *Raft)applyMessage() {
for rf.lastApplied < rf.commitIndex {
rf.lastApplied++
msg := ApplyMsg {
true,
rf.log[rf.lastApplied].Command,
rf.lastApplied,
}
rf.applyCh <- msg
}
}
//If there exists an N such that N > commitIndex
//a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N
func (rf *Raft) checkCommit(server int) {
N := rf.matchIndex[server]
if N > rf.commitIndex {
var cnt int32 = 0
for _,m := range rf.matchIndex {
if m >= N {
cnt++
}
}
if cnt > rf.majority && rf.log[N].Term == rf.currentTerm {
rf.commitIndex = N
//apply to tester
rf.applyMessage()
}
}
}
func (rf *Raft) ticker() {
for !rf.killed() {
electionTimeout := rand.Intn(150) + 350 //election timeout between 350-500 ms
rf.mu.Lock()
state := rf.state
rf.mu.Unlock()
switch state {
case Follower, Candidate:
select {
case <-time.After(time.Duration(electionTimeout) * time.Millisecond):
rf.mu.Lock()
//out of time,kick off election
rf.beCandidate()
//DPrintf("%d kick off election",rf.me)
rf.mu.Unlock()
case <-rf.flushCh:
//case 1:receive heartBeat or replicated log or vote for candidate,reset timer
//case 2:be leader and start heartbeat,jump out of select section in ticker() to flush state
}
case Leader:
rf.groupAppendLog()
time.Sleep(HeartBeatTimeout)
}
}
}
//
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
rf.majority = int32(len(rf.peers) / 2)
rf.flushCh = make(chan int, 1)
rf.votedFor = -1
rf.currentTerm = 0
rf.state = Follower
rf.log = make([]Entry, 1)
rf.applyCh = applyCh
rf.commitIndex = 0
rf.lastApplied = 0
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
//timer start
go rf.ticker()
return rf
}
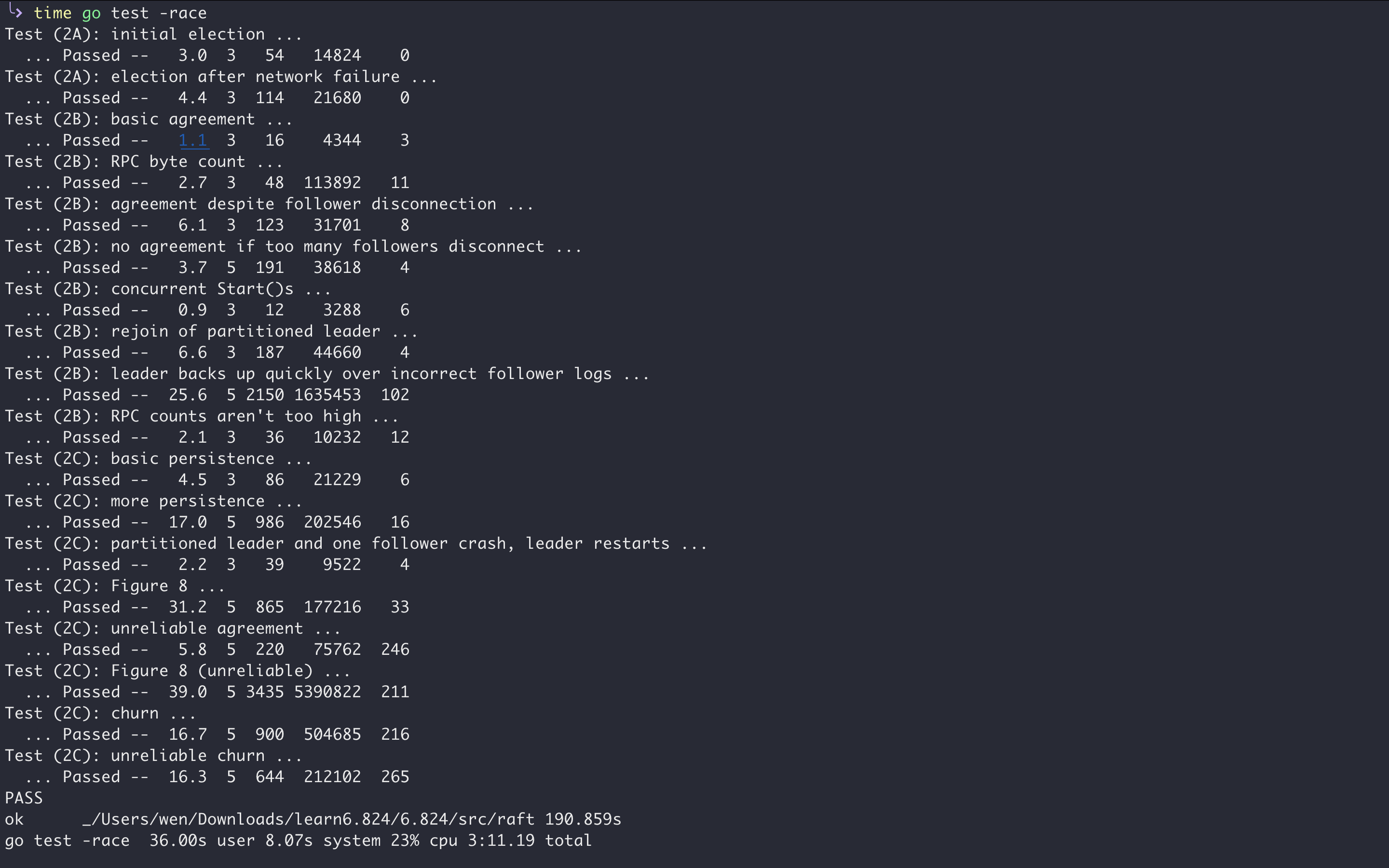
完整测试
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号