词频统计
词频统计
一.中文词频统计
代码:
import jieba
f = open(r'C:\Users\Administrator\Desktop\Markdown文档\110.txt', 'r')
data = f.read()
print(data)
data_jieba = jieba.lcut(data)
print(data_jieba)
count_dict = {}
for word in data_jieba:
if len(word) == 1:
continue
if word in {"将军", "却说", "荆州", "二人", "不可", "不能", "如此", "商议"}:
continue
if word == '孔明曰':
word = '孔明'
elif word == '玄德曰':
word = '玄德'
if '曰' in word:
word = word.replace('曰', '')
if word in count_dict:
count_dict[word] += 1
else:
count_dict[word] = 1
def func(i):
return i[1]
data_list = list(count_dict.items())
data_list.sort(key=func)
data_list.reverse()
print(data_list)
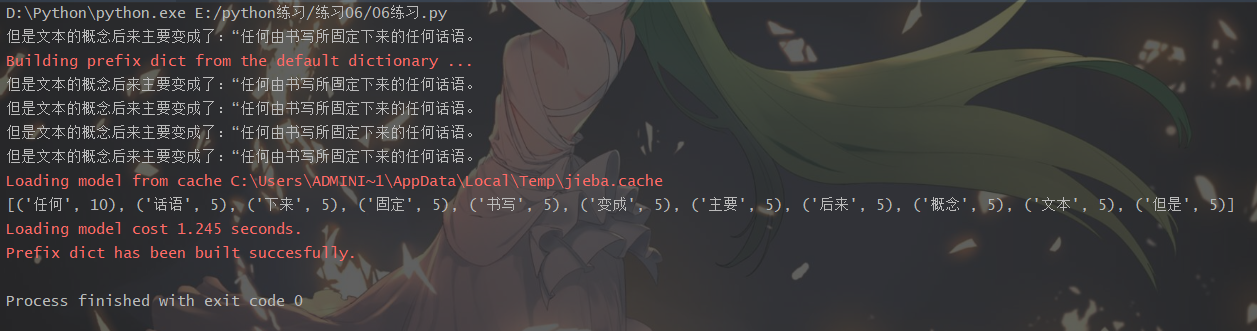
效果:
二.英文词频统计
代码:
f = open(r'C:\Users\Administrator\Desktop\Markdown文档\120.txt','r',encoding='utf8')
data = f.read()
print(data)
data_split = data.split(' ')
count_dict = {}
for word in data_split:
if word not in count_dict:
count_dict[word] = 1
else:
count_dict[word] += 1
# print(count_dict)
def func(i):
return i[1]
#
lt = list(count_dict.items())
lt.sort(key=func)
lt.reverse()
lt.reverse()
for i in lt[0:10]:
print(f'{i[0]:^15}{i[1]:^2}')
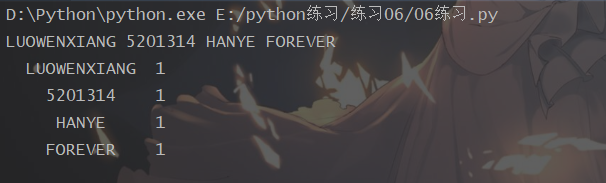
效果:
作者:罗文祥
来源:祥SHAO
原文:https://www.cnblogs.com/LWX-YEER/p/11215490.html
版权声明:本文为博主原创文章,转载请附上博文链接!
