Python简介和入门
Python的前世今生
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python 和 C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
Python的种类
- Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。 - RubyPython、Brython ...
以上除PyPy之外,其他的Python的对应关系和执行流程如下:

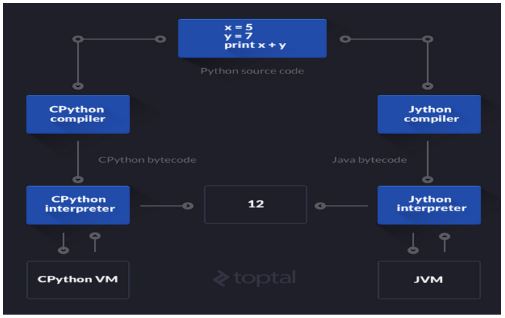
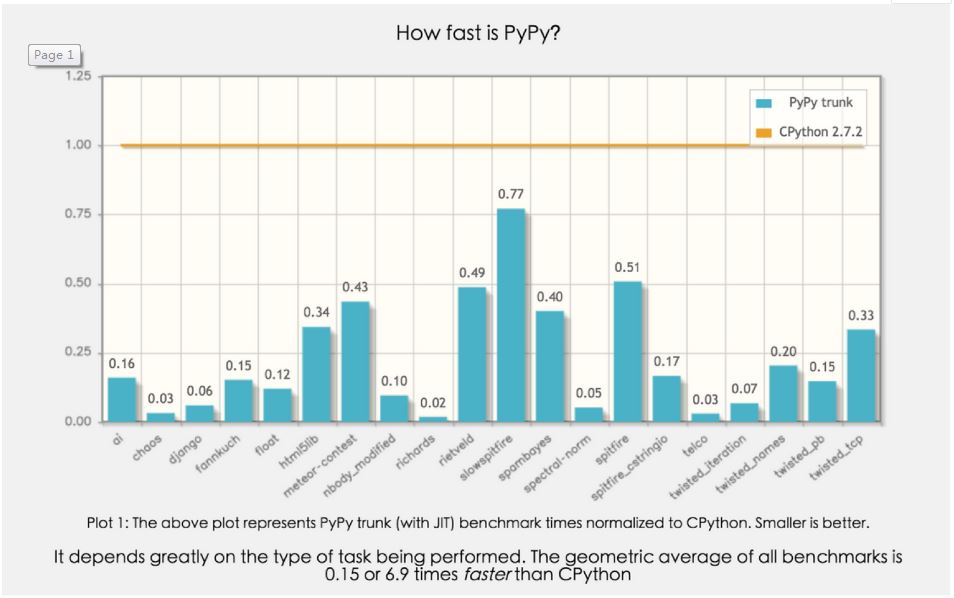
PyPy,在Python的基础上对Python的字节码进一步处理,从而提升执行速度!
Python环境
1 windows: 2 3 1、下载安装包 4 https://www.python.org/downloads/ 5 2、安装 6 默认安装路径:C:\python27 7 3、配置环境变量 8 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 9 如:原来的值;C:\python27,切记前面有分号
安装Python (推荐用3.x系列了,改了很多,也更方便,在编码方面不需要设置用什么编码了)
1 linux: 2 3 无需安装,原装Python环境 4 5 ps:如果自带2.6,请更新至2.7
更新Python
1 windows: 3 卸载重装即可 4 linux: 5 6 Linux的yum依赖自带Python,为防止错误,此处更新其实就是再安装一个Python 7 8 查看默认Python版本 9 10 python -V 11 12 1、安装gcc,用于编译Python源码 13 yum install gcc 14 2、下载源码包,https://www.python.org/ftp/python/ 15 3、解压并进入源码文件 16 4、编译安装 17 ./configure 18 make all 19 make install 20 5、查看版本 21 /usr/local/bin/python2.7 -V 22 6、修改默认Python版本 23 mv /usr/bin/python /usr/bin/python2.6 24 ln -s /usr/local/bin/python2.7 /usr/bin/python 25 7、防止yum执行异常,修改yum使用的Python版本 26 vi /usr/bin/yum 27 将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
Python 入门
所有代码都以Pycharm演示
一、输出第一句Python代码
#以下是print输出的三种格式
1 print('hello world')#单引号 2 print("hello world")#双引号 3 print('''hello world''')#多引号,
run:
C:\Python\python.exe C:/Python/leetcode/1.py
hello world
hello world
hello world
Process finished with exit code 0
单双引号其实并无区别,多引号用于多行输出
print('''hello world 1234567890 sdfghjkl qazwsxc''')
run:
C:\Python\python.exe C:/Python/leetcode/1.py
hello world
1234567890
sdfghjkl
qazwsxc
Process finished with exit code 0
python内部执行过程如下:
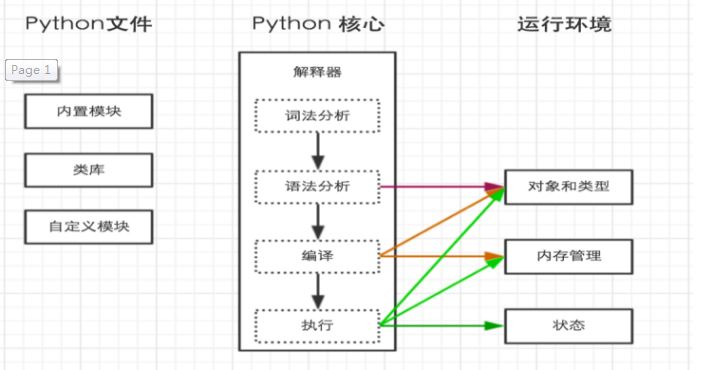
二、解释器
在Pycharm中也是要有解释器的,需要先进行下载,记录好安装路径,就是里面有一个python.exe的路径。
然后在Pycharm中按照file>>settings>>project xxx(你的项目名字)>>project interpreter,进入下图

在蓝色标记里选择自己之前安装的python.exe的路径。
三、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
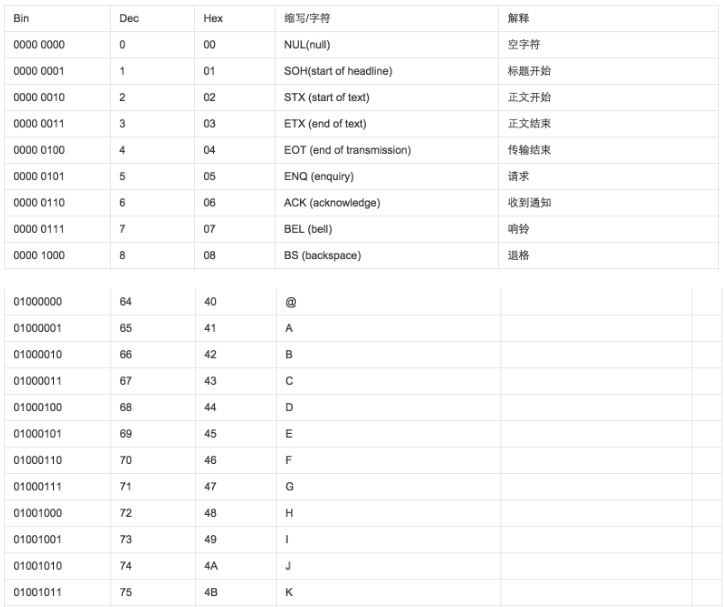
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
#所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话: #报错:ascii码无法表示中文 #!/usr/bin/env python print "你好,世界" #改正:应该显示的告诉python解释器,用什么编码来执行源代码,即: #!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
注意,以上出现的编码错误在3.x系列里已经没有了,所以如果用的3.x系列完全不用考虑这个问题,其默认是utf-8
四、注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
五、执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys print sys.argv
六、 pyc 文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
所以,说Python 是解释性语言也有问题,否则,为什么会生产.pyc文件?这明明是一种类似编译之后得到的字节码文件!
解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
Python到底是什么语言
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
七、变量
1、声明变量
#!/usr/bin/env python # -*- coding: utf-8 -*- name = "vhiv"
上述代码声明了一个变量,变量名为: name,变量name的值为:"vhiv"
变量的作用:昵称,其代指内存里某个地址中保存的内容
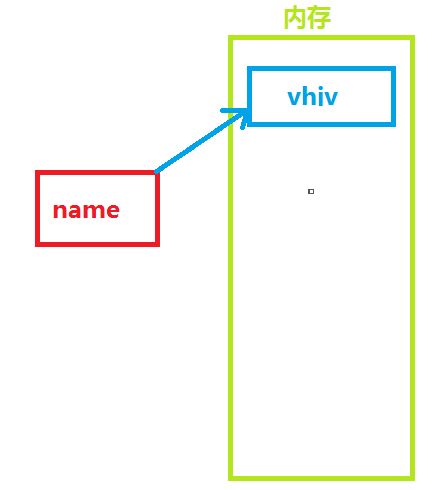
变量定义的规则:
变量名只能是 字母、数字或下划线的任意组合 变量名的第一个字符不能是数字 以下关键字不能声明为变量名 ['and', 'as', 'assert', 'break', 'class', 'continue',
'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for',
'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass',
'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
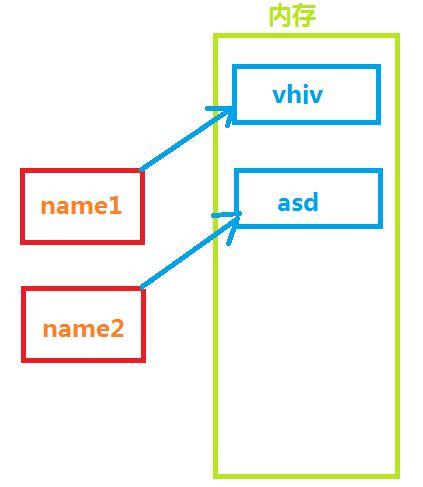
2、变量的赋值
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "vhiv" name2 = "asd"
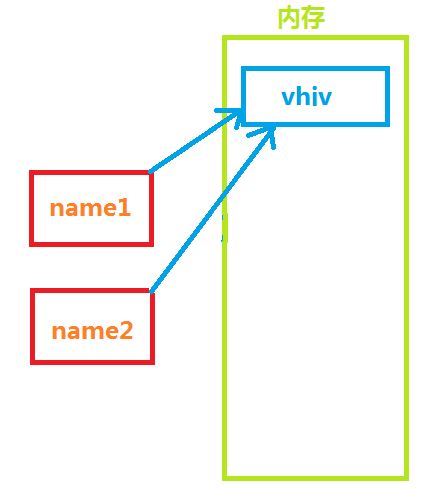
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "vhiv" name2 = name1
八、输入
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 将用户输入的内容赋值给 name 变量
name = input("请输入用户名:")
# 打印输入的内容
print (name)
run:
C:\Python\python.exe C:/Python/leetcode/1.py
请输入用户名:NBA
NBA
Process finished with exit code 0
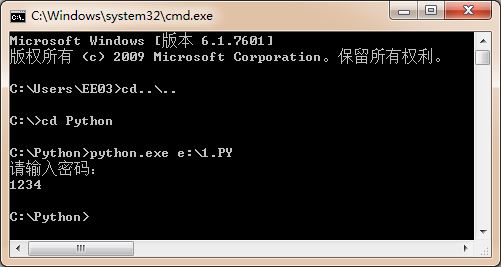
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即: 注,此模块在pycharm中无法使用,以下在notepad++中演示
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 pwd 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print (pwd)
九、表达式 if ....else
需求一、用户登陆验证
1 # 提示输入用户名和密码 2 3 # 验证用户名和密码 4 # 如果错误,则输出用户名或密码错误 5 # 如果成功,则输出 欢迎,XXX!


import getpass name = input('请输入用户名:') pwd = getpass.getpass('请输入密码:') if name == "123" and pwd == "123": print ("欢迎,123!") else: print ("用户名和密码错误")
需求二、根据用户输入内容输出其权限
1 # 根据用户输入内容打印其权限 2 3 # alex --> 超级管理员 4 # eric --> 普通管理员 5 # tony --> 业务主管 6 # 其他 --> 普通用户
1 name = input('请输入用户名:') 2 if name == "a": 3 print("超级管理员") 4 elif name == "b": 5 print("普通管理员") 6 elif name == "c": 7 print("业务主管") 8 else: 9 print("普通用户")
外层变量,可以被内层代码使用
内层变量,不应被外层代码使用
十、for 循环
1、最简单的循环10次
1 for i in range(10):# 2 print("loop:", i )
输出:
C:\Python\python.exe C:/Python/leetcode/1.py loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 loop: 6 loop: 7 loop: 8 loop: 9 Process finished with exit code 0
需求一:还是上面的程序,但是遇到小于5的循环次数就不走了,直接跳入下一次循环
1 for i in range(10): 2 if i<5: 3 continue #不往下走了,直接进入下一次loop 4 print("loop:", i )
输出:
C:\Python\python.exe C:/Python/leetcode/1.py loop: 5 loop: 6 loop: 7 loop: 8 loop: 9 Process finished with exit code 0
需求二:还是上面的程序,但是遇到大于5的循环次数就不走了,直接退出
1 for i in range(10): 2 if i>5: 3 break #不往下走了,直接跳出整个loop 4 print("loop:", i )
输出:
C:\Python\python.exe C:/Python/leetcode/1.py loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 Process finished with exit code 0
十一、while 循环
循环100次退出吧!
1 count = 0 2 while True: 3 print("你是风儿我是沙,缠缠绵绵到天涯...",count) 4 count +=1 5 if count == 100: 6 print("去你妈的风和沙,你们这些脱了裤子是人,穿上裤子是鬼的臭男人..") 7 break
输出:
............................
如何实现让用户不断的猜年龄,但只给最多3次机会,再猜不对就退出程序
1 my_age = 28 2 count = 0 3 while count < 3: 4 user_input = int(input("input your guess num:")) 5 6 if user_input == my_age: 7 print("Congratulations, you got it !") 8 break 9 elif user_input < my_age: 10 print("Oops,think bigger!") 11 else: 12 print("think smaller!") 13 count += 1 # 每次loop 计数器+1 14 else: 15 print("猜这么多次都不对,你个笨蛋.")
十二、初识基本数据类型
1、数字
1 2 是一个整数的例子。 2 长整数 不过是大一些的整数。 3 3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。 4 (-5+4j)和(2.3-4.6j)是复数的例子。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
真或假
1 或 0
True or False
3、字符串
"hello world"
万恶的字符串拼接: python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,
万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化:
1 name = "alex" 2 print ("i am %s " %name)
3 4 #输出: i am alex
PS: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
- 移除空白
- 分割
- 长度
- 索引
- 切片
4、列表
创建列表:
1 name_list = ['asd', 'fgh', 'eqwe'] 2 或 3 name_list = list(['jhg', 'scde', 'eric'])
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
5、元祖
创建元祖:
1 ages = (11, 22, 33, 44, 55) 2 或 3 ages = tuple((11, 22, 33, 44, 55))
基本操作:
- 索引
- 切片
- 循环
- 长度
- 包含
6、字典(无序)
1 person = {"name": "mr.wu", 'age': 18} 2 或 3 person = dict({"name": "mr.wu", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
PS:循环,range,continue 和 break
十三、运算
1、算数运算符
以下假设变量: a=10,b=20:
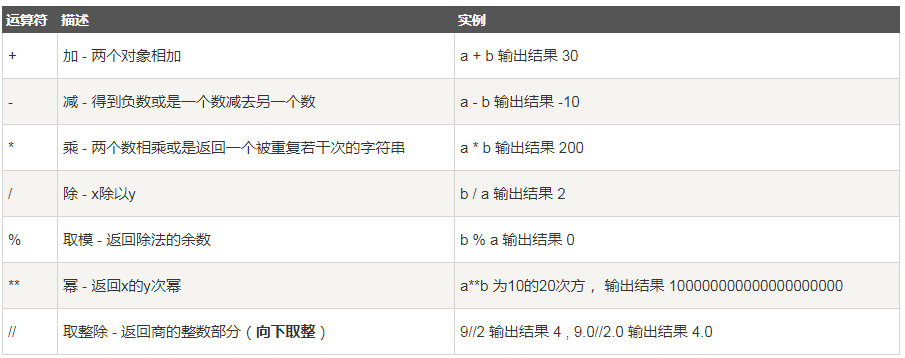
2、比较运算符
以下假设变量a为10,变量b为20:

3、赋值运算符
以下假设变量a为10,变量b为20:
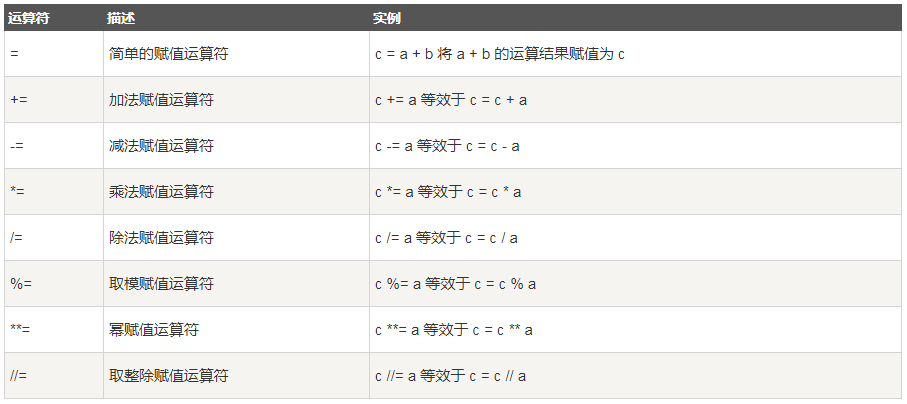
4、位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:
a = 0011 1100 b = 0000 1101 ----------------- a&b = 0000 1100 a|b = 0011 1101 a^b = 0011 0001 ~a = 1100 0011
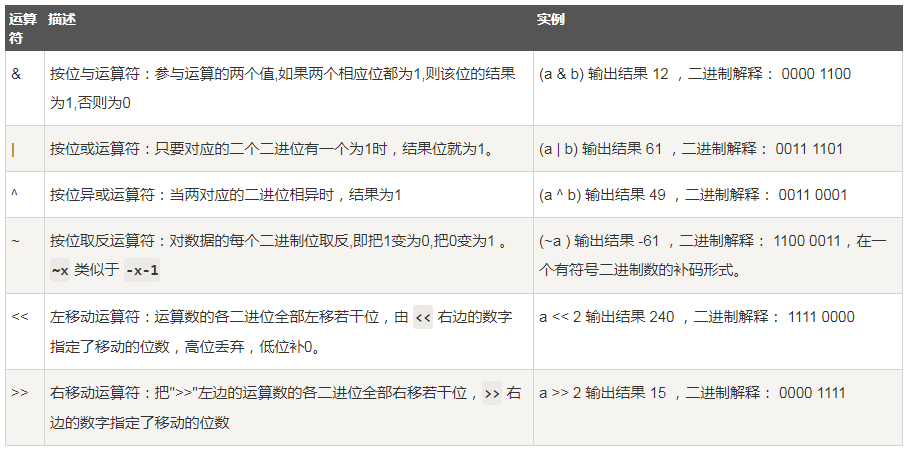
5、逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:

6、成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号