梯度下降算法
梯度下降算法详解
介绍
如果说在机器学习领域有哪个优化算法最广为认知,用途最广,非梯度下降算法莫属。梯度下降算法是一种非常经典的求极小值的算法,比如在线性回归里我们可以用最小二乘法去解析最优解,但是其中会涉及到对矩阵求逆,由于多重共线性问题的存在是很让人难受的,无论进行L1正则化的Lasso回归还是L2正则化的岭回归,其实并不让人满意,因为它们的产生是为了修复此漏洞,而不是为了提升模型效果,甚至使模型效果下降。但是换一种思路,比如用梯度下降算法去优化线性回归的损失函数,完全就可以不用考虑多重共线性带来的问题。其实不仅是线性回归,逻辑回归同样是可以用梯度下降进行优化,因为这两个算法的损失函数都是严格意义上的凸函数,即存在全局唯一极小值,较小的学习率和足够的迭代次数,一定可以达到最小值附近,满足精度要求是完全没有问题的。并且随着特征数目的增多(列如100000),梯度下降的效率将远高于去解析标准方程的逆矩阵。神经网络中的后向传播算法其实就是在进行梯度下降,GDBT(梯度提升树)每增加一个弱学习器(CART回归树),近似于进行一次梯度下降,因为每一棵回归树的目的都是去拟合此时损失函数的负梯度,这也可以说明为什么GDBT往往没XGBoost的效率高,因为它没办法拟合真正的负梯度,而Xgboost 的每增加的一个弱学习器是使得损失函数下降最快的解析解。总之梯度下降算法的用处十分广泛,我们有必要对它进行更加深入的理解。
关于梯度下降算法的直观理解

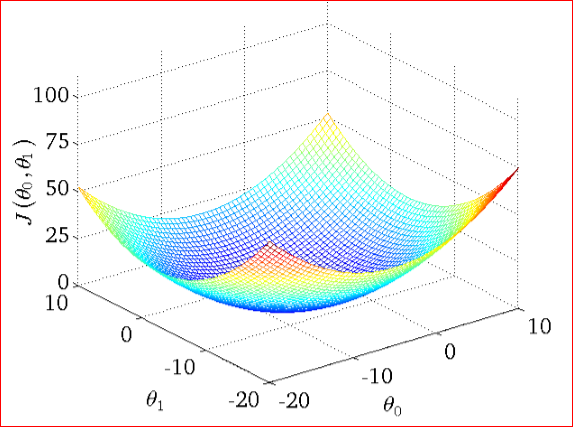
关于梯度下降算法的直观理解,我们以一个人下山为例。比如刚开始的初始位置是在红色的山顶位置,那么现在的问题是该如何达到蓝色的山底呢?按照梯度下降算法的思想,它将按如下操作达到最低点:
第一步,明确自己现在所处的位置
第二步,找到相对于该位置而言下降最快的方向
第三步, 沿着第二步找到的方向走一小步,到达一个新的位置,此时的位置肯定比原来低
第四部, 回到第一步
第五步,终止于最低点
按照以上5步,最终达到最低点,这就是梯度下降的完整流程。当然你可能会说,上图不是有不同的路径吗?是的,因为上图并不是标准的凸函数,往往不能找到最小值,只能找到局部极小值。所以你可以用不同的初始位置进行梯度下降,来寻找更小的极小值点,当然如果损失函数是凸函数就没必要了,开开心心的进行梯度下降吧!比如下面这种:
问题是,如何用数学语言去描述以上5步呢?
梯度下降算法的理论推导
一元函数
一元函数的导数我相信大家都学过,其几何意义是某点切线的斜率,除此之外它还能表示函数在该点的变化率,导数越大,说明函数在该点的变化越大。
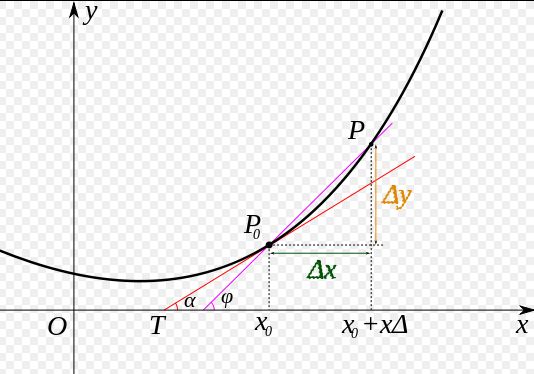
则导函数本身则代表着函数沿着x方向的变化率
二元函数
对于二元函数,z=f(x,y),它对x和y的偏导数分别表示如下:
函数在y方向不变的情况下,函数值沿x方向的变化率
函数在x方向不变的情况下,函数值沿y方向的变化率
有了以上的了解,我们分别知道了函数在单独在x和y方向上的变化率
现在有一个问题,我想知道函数在其他方向上的变化率怎么办?
比如下图中的u方向上:
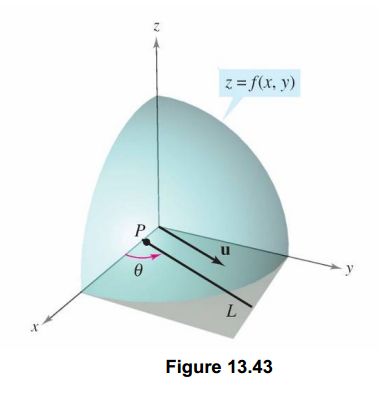
其实是可以做到的,我们都学过,在一平面中,任意一向量都可以用两个不共线的基向量表示,也就是说任意一方向上的变化,都可以分解到x和y两个方向上。
比如,我想求u方向上的变化率,根据导函数的定义
若:
其中α是u方向与x正方向的夹角
极限存在,可用洛必达法则,分子分母同时对\(\Delta u\)求导
原式等于:
令:
这是一个自变量是α的函数,我们将其命名为方向导数,其表明随着α的不同,方向不同,函数的变化率不同。
至此,我们推出了,方向导数的概念,还记得我们的梯度下降算法的第二步是什么吗?
”找到相对于该位置而言下降最快的方向“
而我们的方向导数,本身代表的就是函数变化率与方向的关系,也就是说我们需要利用方向导数,找到使得函数变化率最大的方向
那么,问题来了,在哪一个方向上变化率最大呢?
寻找函数变化率最大的方向-梯度
我们可以这样改写,令:
则:
θ是两个向量的夹角
显然,当θ=0时,取得最大方向导数,也就说随着α的改变,当两个向量A和I是平行的时候,取得最大方向导数,而此时I的方向就是下式的方向:
我们把上式称之为梯度,所以梯度方向是函数变化率最大的方向,更本质的说是函数增长最快的方向
所以,当我们需要最小化损失函数时,只需要使损失函数沿着负梯度前行,就能使损失函数最快下降。
更高元函数
二元函数的推导结论同样可作用于更高元的函数。
所以,高元函数在某点的梯度就是对每一个自变量求偏导,组成的一个向量,在该点的取值,该向量的方向就是函数在该点处增长最快的方向,显然,其负方向就是函数减少最快的方向
以下面的函数举个例子,这是一个有n+1个自变量的函数,自变量是θ:
首先呢,随机化一个我们梯度下降的初始位置,全部为0吧,当然在神经网络中可不能如此随意:
计算梯度,对每一个自变量求偏导:
将初始化的值0,代入上式梯度,就可以得到一个具体的向量,为什么是一个具体的向量呢?这个你要自己想想了
而该向量的方向就是函数在该点增长最快的方向
那么,显然,我们需要往其负方向走一段距离,可是,如何往负方向走呢?其实一样的道理,该负方向同样将其分解到各个自变量的维度上,即其更新过程可写成:
式中的减号表示往梯度的负方向改变
а为学习率,是一个大于0的数,它能控制沿着该方向走多长一段距离,不是步长
什么才是真正的步长?
一个式子说明足以,将当前位置θ代入下式,就是在该点处梯度下降的步长:
所以步长是一个有方向和模长的矢量,当然也是符合我们直观上的理解的,你总要确定往哪个方向走以及步子迈多大。
应用:线性回归的梯度下降解法
首先,我们给出线性回归的损失函数,为了方便,不带正则项:
其中:
其更新过程可写成:
具体的梯度下降流程:
第一步:先随便假设一组θ,你要是喜欢可以全部取0
第二步循环迭代:
第一次迭代:
第二次迭代:
第x次迭代:......
第三步,满足要求,循环结束,得到θ
参考资料:
- 为什么梯度反方向是函数值局部下降最快的方向?https://zhuanlan.zhihu.com/p/24913912
- 梯度下降(Gradient Descent)小结-刘建平 https://www.cnblogs.com/pinard/p/5970503.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号