一 数据的概括性度量
一 数据的概括性度量
(1)集中趋势的度量

分类数据:众数
1. 一组数据中出现次数最多的变量值
2. 适合于数据量较多时使用
3. 不受极端值的影响
4. 一组数据可能没有众数或有几个众数
5. 主要用于分类数据,也可用于顺序数据和数值 型数据
顺序数据:中位数和分位数
中位数:
1. 排序后处于中间位置上的值
2. 不受极端值的影响(重要)
3. 主要用于顺序数据,也可用数值型数据,但不能 用于分类数据
四分位数:
1. 排序后处于25%和75%位置上的值
2. 不受极端值的影响
数值型数据:平均数
平均数(mean):
1. 也称为均值
2. 集中趋势的最常用测度值
3. 一组数据的均衡点所在
3. 体现了数据的必然性特征
4. 易受极端值的影响
5. 有简单平均数和加权平均数之分
6. 根据总体数据计算的,称为平均数,记为μ;根据 样本数据计算的,称为样本平均数,记为 x
离散程度的度量
分类数据:异众比率
顺序数据:四分位差
数值型数据:方差和标准差
相对离散程度:离散系数
(2)离散程度的度量
1. 数据分布的另一个重要特征
2. 反映各变量值远离其中心值的程度(离散程度)
3. 从另一个侧面说明了集中趋势测度值的代表程度
4. 不同类型的数据有不同的离散程度测度值
分类数据:异众比率
1. 对分类数据离散程度的测度
2. 非众数组的频数占总频数的比例
3. 计算公式为
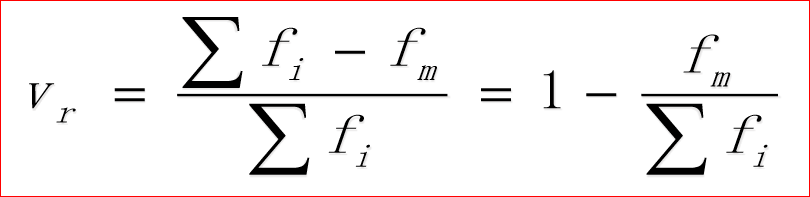
顺序数据:四分位差
1. 对顺序数据离散程度的测度
2. 也称为内距或四分间距
3. 上四分位数与下四分位数之差 Qd = QU – QL
4. 反映了中间50%数据的离散程度
5. 不受极端值的影响
6. 用于衡量中位数的代表性
数值型数据:方差和标准差
1. 数据离散程度的最常用测度值
2. 反映了各变量值与均值的平均差异
3. 根据总体数据计算的,称为总体方差(标准差), 记为σ∧2(σ);根据样本数据计算的,称为样本方 差(标准差),记为s∧2(s)
总体方差和标准差

样本方差和标准差

自由度
1. 自 由 度 是 指 数 据 个 数 与 附 加给 独 立 的观 测 值 的 约束或限制的个数之差
2. 从 字 面 涵 义 来 看 , 自 由 度 是指 一 组 数据 中 可 以 自由取值的个数
3. 当样本数据的个数为n时,若样本平均数确定后, 则附加给n个观测值的约束个数就是 1个,因此 只 有 n-1 个 数 据 可 以 自 由 取 值 , 其 中 必 有 一 个 数据不能自由取值
4. 按着这一逻辑,如果对n个观测值附加的约束个 数为k个,自由度则为n-k
#1. 样本有3个数值,即x1=2,x2=4,x3=9,则 x = 5。 当 x = 5 确定后,x1,x2和x3有两个数据可以自由取 值,另一个则不能自由取值,比如x1=6,x2=7,那么 x3则必然取2,而不能取其他值 #2. 为什么样本方差的自由度为什么是n-1呢?因为在计 算离差平方和时,必须先求出样本均值x ,而x则 是附件给离差平方和的一个约束,因此,计算离差 平方和时只有n-1个独立的观测值,而不是n个 #3. 样本方差用自由度去除,其原因可从多方面解释, 从实际应用角度看,在抽样估计中,当用样本方差s2 去估计总体方差σ2时,它是σ2的无偏估计量
标准分数
1. 也称标准化值
2. 对某一个值在一组数据中相对位置的度量
3. 可用于判断一组数据是否有离群点(outlier)
4. 用于对变量的标准化处理
5. 计算公式为
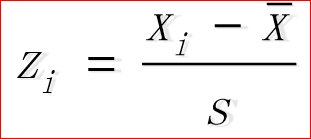
经验法则(适用于数据对称分布)
约有68%的数据在平均数加减1个标准差的范围 之内
约有95%的数据在平均数加减2个标准差的范围 之内
约有99%的数据在平均数加减3个标准差的范围 之内
切比雪夫不等式
1. 如果一组数据不是对称分布,经验法则就不再适用,这时可使用切比雪夫不等式,它对任何分布形状的数据都适用
2. 切比雪夫不等式提供的是“下界”,也就是 “所占比例至少是多少”
3. 对于任意分布形态的数据,根据切比雪夫不 等式,至少有1-1/k2的数据落在平均数加减k 个标准差之内。其中k是大于1的任意值,但 不一定是整数
#对于k=2,3,4,该不等式的含义是 : #1. 至少有75%的数据落在平均数加减2个标准差的范围之内 #2. 至少有89%的数据落在平均数加减3个标准差的范围之内 #3. 至少有94%的数据落在平均数加减4个标准差的范围之内
相对离散程度:离散系数
1.标准差与其相应的均值之比
2.对数据相对离散程度的测度
3.消除了数据水平高低和计量单位的影响
4.用于对不同组别数据离散程度的比较
5.计算公式为
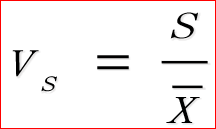

 浙公网安备 33010602011771号
浙公网安备 33010602011771号