Hadoop Day1
Hadoop Day1
1.Hadoop简介(****了解***)
- hadoop是什么?
What Is Apache Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
Hadoop是开源的,可靠的,可扩展的,分布式的运算存储系统。
备注:用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
- Hadoop能解决什么问题?(***记住***)
l 海量数据的存储(HDFS)
l 海量数据的分析(MapReduce)
l 资源管理调度(YARN)
- hadoop来源与历史(****了解***)
l Hapdoop是Google的集群系统的开源实现
-Google集群系统:
GFS(Google File System) 、MapReduce、BigTable
-Hadoop主要由HDFS(Hadoop Distributed File System即hadoop分布式文件系统)、MapReduce和Hbase组成。
l Hadoop的最初是为了解决Nutch的海量数据爬取和存储需要。
l Hadoop在2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
- hadoop具体能干什么(***知道****)
hadoop擅长日志分析
l facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析.
l 淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!
l 在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
- 哪些公司使用hadoop(***了解***)
l Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。
比较大型IT公司如EMC、Microsoft、Intel、Teradata、Cisco都明显增加了Hadoop方面的投入。
l 在淘宝:
n 从09年开始,用于对海量数据的离线处理,例如对日志的分析,交易记录的分析
n 规模从当初的3~4百台节点,增加到现在的一个集群有3000个节点,淘宝现在已经有2~3个这样的集群
n 在支付宝的集群规模也有700台节点,使用Hbase对用户的消费记录可以实现毫秒级查询
- Hadoop生态地图(***了解***)
1.这一切是如何开始的—Web上庞大的数据!
2.使用Nutch抓取Web数据
3.要保存Web上庞大的数据——HDFS应运而生
4.如何使用这些庞大的数据?
5.采用Java或任何的流/管道语言构建MapReduce框架用于编码并进行分析
6.如何获取Web日志,点击流,Apache日志,服务器日志等非结构化数据——fuse,webdav, chukwa, flume, Scribe
7.Hiho和sqoop将数据加载到HDFS中,关系型数据库也能够加入到Hadoop队伍中
8.MapReduce编程需要的高级接口——Pig, Hive, Jaql
9.具有先进的UI报表功能的BI工具- Intellicus
10.Map-Reduce处理过程使用的工作流工具及高级语言
11.监控、管理hadoop,运行jobs/hive,查看HDFS的高级视图—Hue, karmasphere, eclipse plugin, cacti, ganglia
12.支持框架—Avro (进行序列化), Zookeeper (用于协同)
13.更多高级接口——Mahout, Elastic map Reduce
14.同样可以进行Hbase
备注:
Sqoop传统数据库和hdfs进行数据交换,目前支持cloudera版本的hadoop,项目主页:https://github.com/cloudera/sqoop
Flume日志实时传输整合工具,项目主页:https://github.com/cloudera/flume
HBase是一个分布式的、面向列的开源数据库http://hbase.apache.org/
- Hadoop版本(***了解***)
l Apache hadoop官方网址http://hadoop.apache.org/
官方目前最高版本(2.7.0)
备注:下载地址http://hadoop.apache.org/releases.html
官方提供的包有两种:
一:source包,也就是源码包要求自已编译安装的包
二:binary包,32位编译后的包,可以直接使用的包。
注意:官方只提供32位环境编译的包,只能运行在32位机器上.生产环境一般是64位操作系统,要求自已编译源码包进行安装。
另外下载所有版本网址:http://archive.apache.org/dist/hadoop/
其中http://archive.apache.org/dist这部分是apache开源的所有项目地址,而http://archive.apache.org/dist/hadoop/ 是hadoop项目的地址。
- Hadoop的特点(***了解***)
l 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
l 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
l 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
l 可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
- Hadoop部署方式(***了解***)
l 本地模式
l 伪分布模式
l 集群模式
2.Linux环境准备(***必须掌握****)
参考:http://www.cnblogs.com/LUCKMOON/articles/8833872.html
l 安装VMWare软件
l 在VMWare软件下linux系统
l 配置VMWare虚拟软件网卡,保证Windows机器能和虚拟机linux正常通信
l 修改主机名
l 设置linux机器IP
l 修改主机名和IP的映射关系
l 关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
centos7使用如下命令:
关闭firewall:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
l 重启系统
reboot
l 安装JDK
- 上传
- 解压jdk
#创建文件夹
mkdir /opt/java
#解压
tar -zxvf jdk-7u45-linux-x64.tar.gz -C /opt/java/
- 将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/opt/java/jdk1.7.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$JAVA_HOME/bin:$PATH
#刷新配置
source /etc/profile
#验证
java -version
l SSH免密码登录的配置
原因:在搭建Linux集群服务的时候,主服务器需要启动从服务器的服务,如果通过手动启动,集群内服务器几台还好,要是像阿里1000台的云梯Hadoop集群的话,轨迹启动一次集群就得几个工程师一两天时间,是不是很恐怖。如果使用免密登录,主服务器就能通过程序执行启动脚步,自动帮我们将从服务器的应用启动。而这一切就是建立在ssh服务的免密码登录之上的。所以要学习集群部署,就必须了解linux的免密码登录。
目标:在主服务器Frank2016上的用户免密码登录从服务器Frank2017上的用户
#使用root登录主服务器Frank2016
cd ~
#在主服务器Frank2017上生成密钥对
ssh-keygen -t rsa #然后敲四下回车

会在cd ~/.ssh目录下生成密钥对
drwx------ 2 usera usera 4096 8月 24 09:22 .
drwxrwx--- 12 usera usera 4096 8月 24 09:22 ..
-rw------- 1 usera usera 1675 8月 24 09:22 id_rsa
-rw-r--r-- 1 usera usera 399 8月 24 09:22 id_rsa.pub
#然后将公钥上传到从服务器Frank2017,并以root用户登录
ssh-copy-id root@Frank2017 #敲三次回车
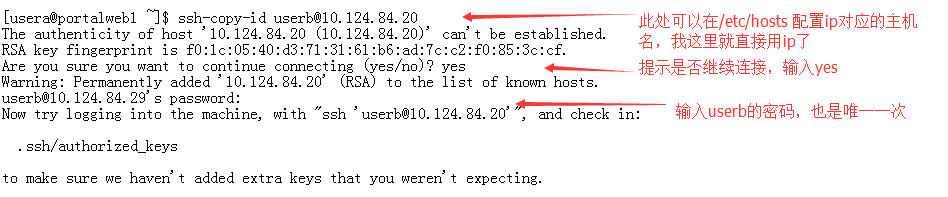
#这个时候主服务器root的公钥文件内容会追加写入到从服务器root的 .ssh/authorized_keys 文件中
另外我们要注意,.ssh目录的权限为700,其下文件authorized_keys和私钥的权限为600。否则会因为权限问题导致无法免密码登录。
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
ssh root@Frank2017
★★★★★1. 建议将主服务器Frank2016的公钥分别传至主服务器Frank2016、从服务器Frank2017、从服务器Frank2018
2.建议从服务器Frank2017、从服务器Frank2018将公钥传至主服务器Frank2016、从服务器Frank2017、从服务器Frank2018
这样子,在后面启动集群的时候,就不用反复输入密码了!!!
下面是原理:
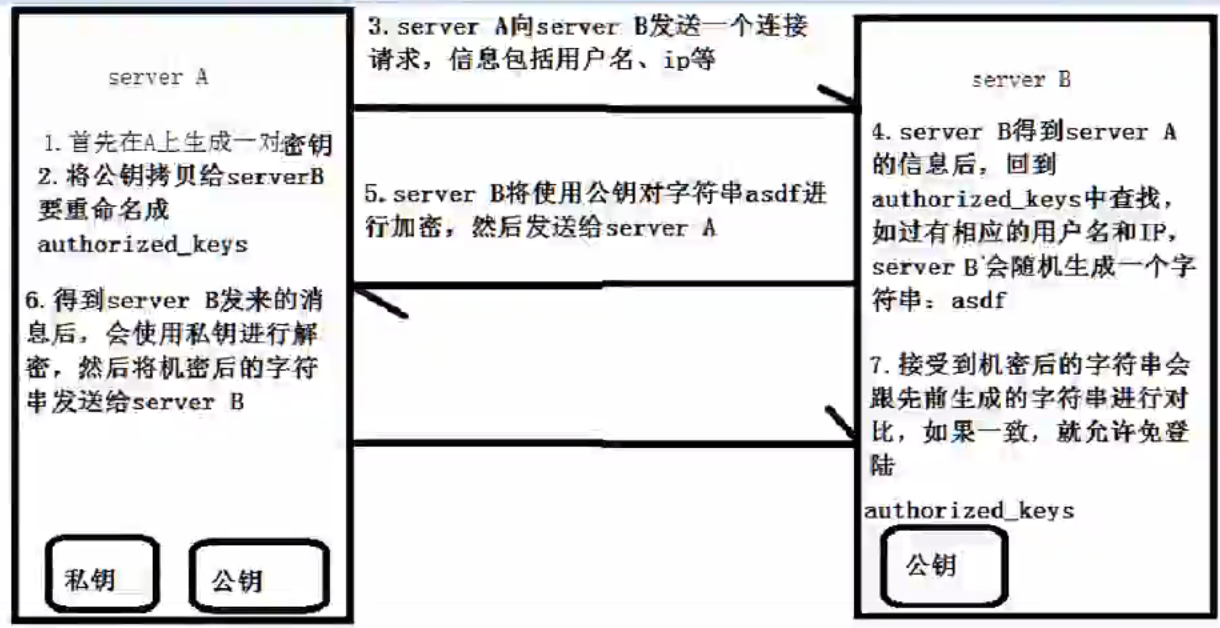
3搭建Hadoop的伪分布环境(***必须掌握***)
l 上传hadoop2.7.0编译后的包并解压到/itcast目录下
mkdir /itcast
解压
tar -zxvf hadoop.2.7.0.tar.gz -C /opt
l 配置hadoop
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
首先要创建文件夹
1./opt/hadoop/hadoop-2.7.3/hdfs/name
2./opt/hadoop/hadoop-2.7.3/hdfs/data
3./opt/hadoop/hadoop-2.7.3/tmp
第一个:hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/opt/java/jdk1.7.0_45
第二个:core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://Frank2016:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Frank2016:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
第三个:hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Frank2016:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Frank2016</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Frank2016:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Frank2016:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Frank2016:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Frank2016:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Frank2016:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
l 将hadoop添加到环境变量
vim /etc/profile
内容如下:
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.3
export JAVA_HOME=/opt/java/jdk1.7.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME_WARN_SUPPRESS=1
让配置生效:
source /etc/profile
l 修改/opt/hadoop/hadoop-2.7.3/etc/hadoop/slaves,改成如下内容
Frank2017
Frank2018
注意:这样配置的前提是主节点要能免密登录到从节点中
当你去执行start-dfs.sh时,它会去slaves文件中去找从节点(这就是配置免密登录的原因)
然后去启动从节点。同时自己也需要做免密登录也就是说要自己对自己做免密登录.
l 格式化namenode(是对namenode进行初始化)
hdfs namenode -format 或者 hadoop namenode -format
l 将整个hadoop-2.7.3\jdk1.7.0_45\profile 文件夹及其子文件夹使用scp复制到Frank2017和Frank2018的相同目录中:
scp -r /opt/hadoop/hadoop-2.7.3 root@Frank2017:/opt/hadoop
scp -r /opt/hadoop/hadoop-2.7.3 root@Frank2018:/opt/hadoop
scp -r /opt/java/jdk1.7.0_45/ root@Frank2017:/opt/java
scp -r /opt/java/jdk1.7.0_45/ root@Frank2018:/opt/java
scp -r /etc/profile root@Frank2017:/etc
scp -r /etc/profile root@Frank2018:/etc
l 启动hadoop
- 先启动HDFS
sbin/start-dfs.sh
- 再启动YARN
sbin/start-yarn.sh
- 也可以使用如下命令
hadoop namenode -format
hadoop-daemon.sh start namenode
hadoop-daemons.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemons.sh start nodemanager
hadoop-daemon.sh start secondarynamenode
l 验证是否启动成功
使用jps命令验证
master:
NameNode
Jps
SecondaryNameNode
ResourceManager
slaves:
DataNode
Jps
NodeManager
l 查看集群状态
hadoop dfsadmin -report
http://frank2016:50070/ (HDFS管理界面)
http://frank2016:18088/ (MR管理界面)
4.Hadoop环境测试(***必须掌握***)
-
hadoop jar /opt/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 5 10
-
- 测试HDSF
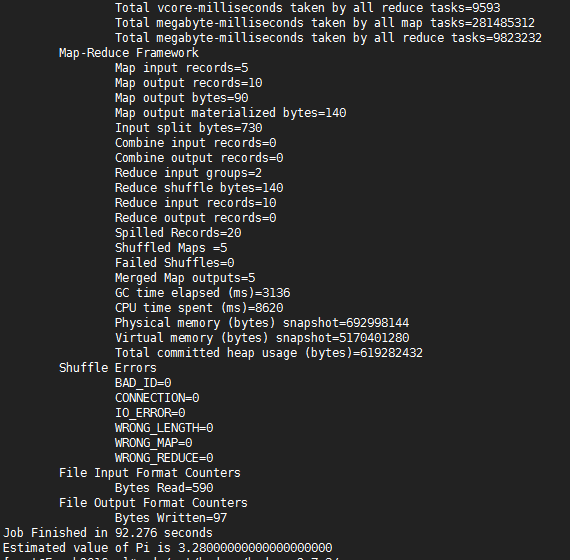
n HDFS shell操作
#查看帮助
hadoop fs -help <cmd>
#上传
hadoop fs -put <linux上文件> <hdfs上的路径>
#查看文件内容
hadoop fs -cat <hdfs上的路径>
#查看文件列表
hadoop fs -ls /
#下载文件
hadoop fs -get <hdfs上的路径> <linux上文件>
n 上传文件到hdfs文件系统上
hadoop fs -put <linux上文件> <hdfs上的路径>
例如:hadoop fs -put /root/install.log hdfs://Frank2016:9000/
n 删除hdfs系统文件
hadoop fs -rmr hdfs://Frank2016:9000/install.log
注:如果能正常上传和删除文件说明HDFS没问题。
- 测试Yarn
n 上传一个文件到HDFS
hadoop fs -put words.txt hdfs://Frank2016:9000/
n 让Yarn来统计一下文件信息
cd $HADOOP_HOME/share/hadoop/mapreduce
#测试命令
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /words.txt hdfs://Frank2016:9000/wc

查看结果
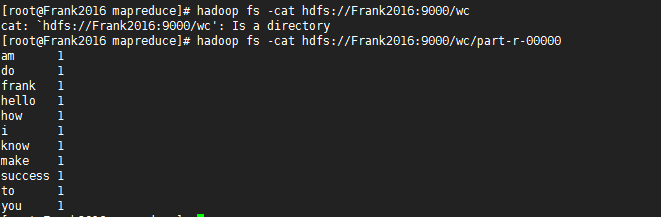
注:如果能正常生成一个目录,并把统计信息输出到文件夹下,说明Yarn没问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号