
新知识:Java 利用itext填写pdf模板并导出(昨天奋战到深夜四点,直到今天两点终于弄懂)
2019-09-24更新:https://www.cnblogs.com/LUA123/p/11580525.html
***************制作模板*******************
1.先用word做出界面
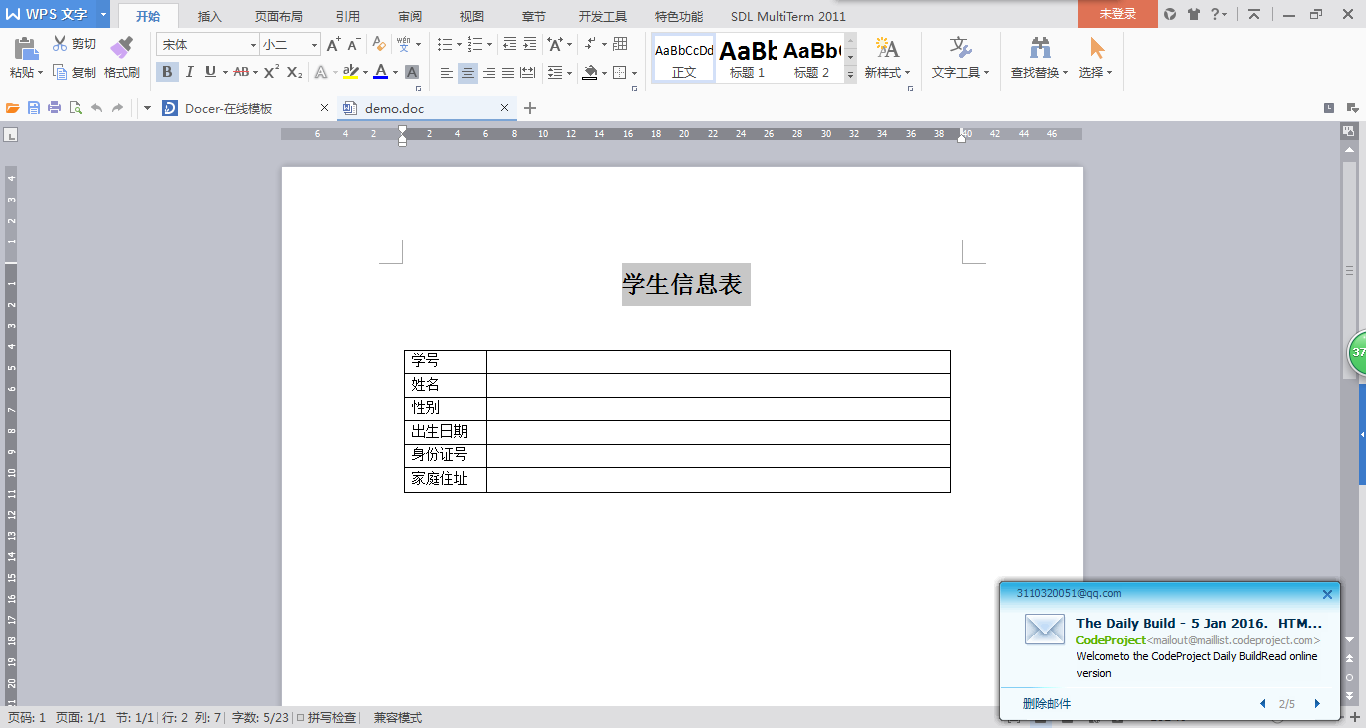
2.再转换成pdf格式
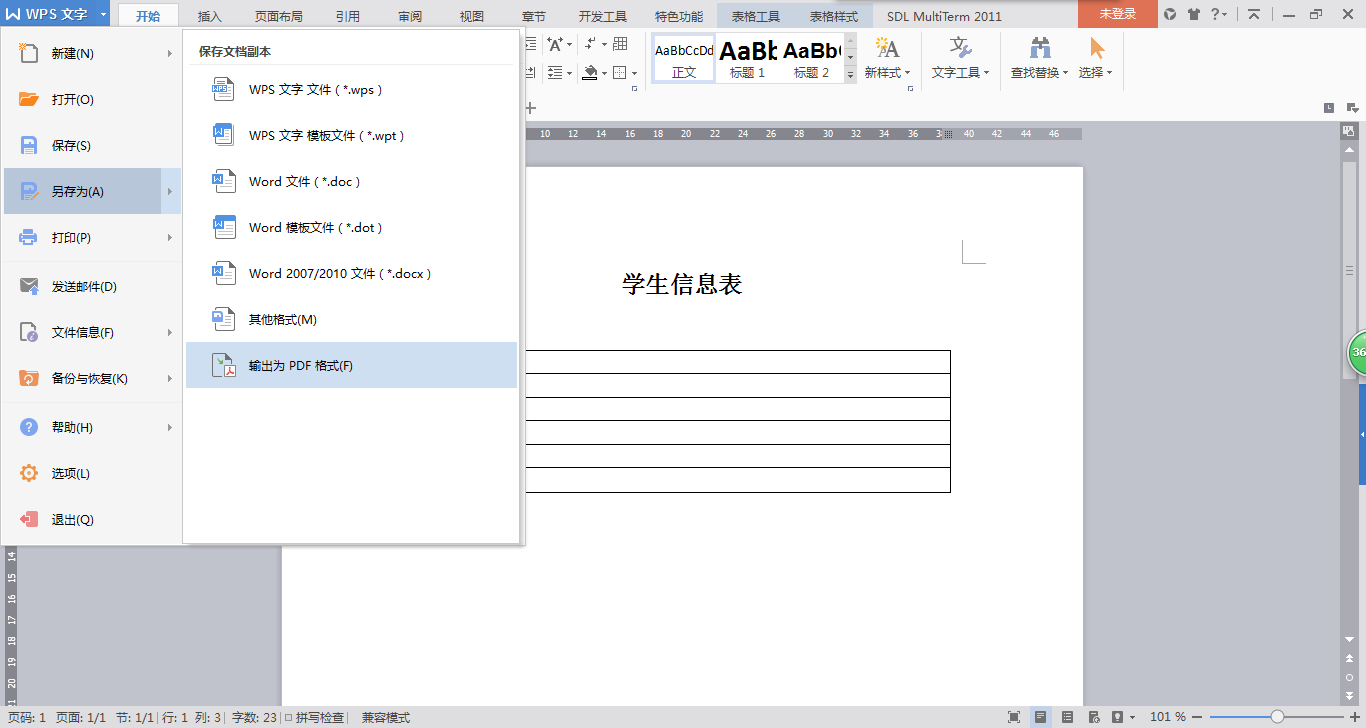
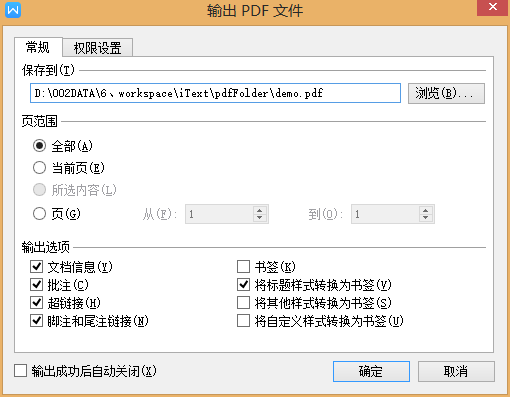
3.用Adobe Acrobat 打开你刚刚用word转换成的pdf

会出现如下界面

下一步

点击浏览,选择刚才你转换好的pdf

下一步
4.打开后它会自动侦测并命名表单域,右键表单域,点击属性,出现文本域属性对话框,有的人说要改成中文字体,可是我没有改一样成功啦

5.一般情况下不需要修改什么东西,至少我没有修改哦
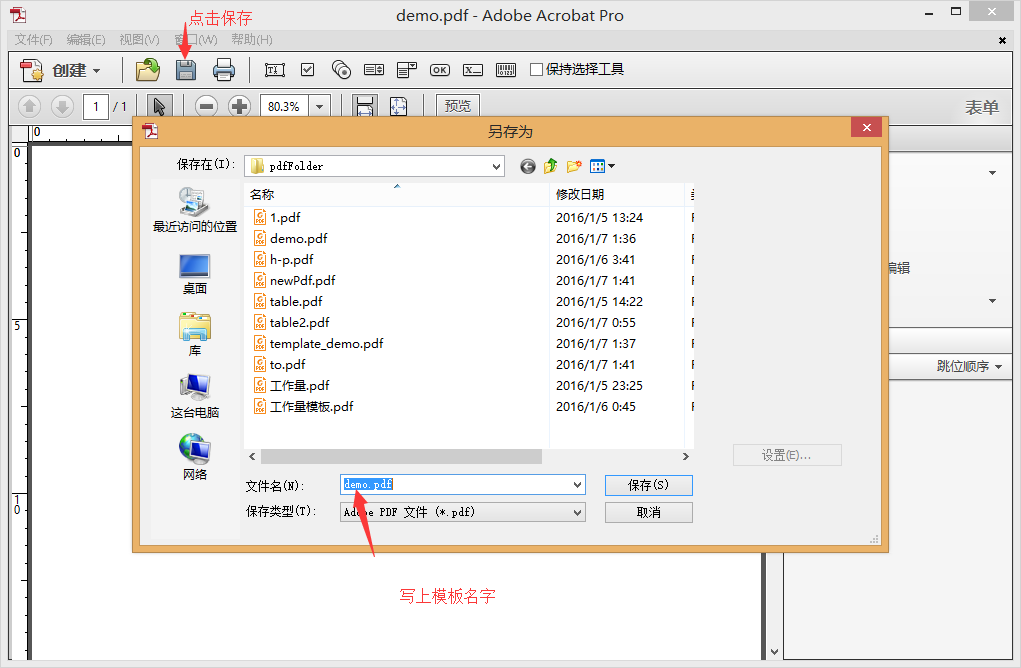
6.直接另存为就行了
************************上程序********************************
准备:itext的jar包包:官网:http://sourceforge.net/projects/itext/files/
因为是利用模板,所以不需要建立字体来解决中文不显示的问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | public void fillTemplate(){//利用模板生成pdf //模板路径 String templatePath = "pdfFolder/template_demo.pdf"; //生成的新文件路径 String newPDFPath = "pdfFolder/newPdf.pdf"; PdfReader reader; FileOutputStream out; ByteArrayOutputStream bos; PdfStamper stamper; try { out = new FileOutputStream(newPDFPath);//输出流 reader = new PdfReader(templatePath);//读取pdf模板 bos = new ByteArrayOutputStream(); stamper = new PdfStamper(reader, bos); AcroFields form = stamper.getAcroFields(); String[] str = {"123456789","小鲁","男","1994-00-00", "130222111133338888" ,"河北省唐山市"}; int i = 0; java.util.Iterator<String> it = form.getFields().keySet().iterator(); while(it.hasNext()){ String name = it.next().toString(); System.out.println(name); form.setField(name, str[i++]); } stamper.setFormFlattening(true);//如果为false那么生成的PDF文件还能编辑,一定要设为true stamper.close(); Document doc = new Document(); PdfCopy copy = new PdfCopy(doc, out); doc.open(); PdfImportedPage importPage = copy.getImportedPage( new PdfReader(bos.toByteArray()), 1); copy.addPage(importPage); doc.close(); } catch (IOException e) { System.out.println(1); } catch (DocumentException e) { System.out.println(2); } } |
模板如图:

程序结果如图:
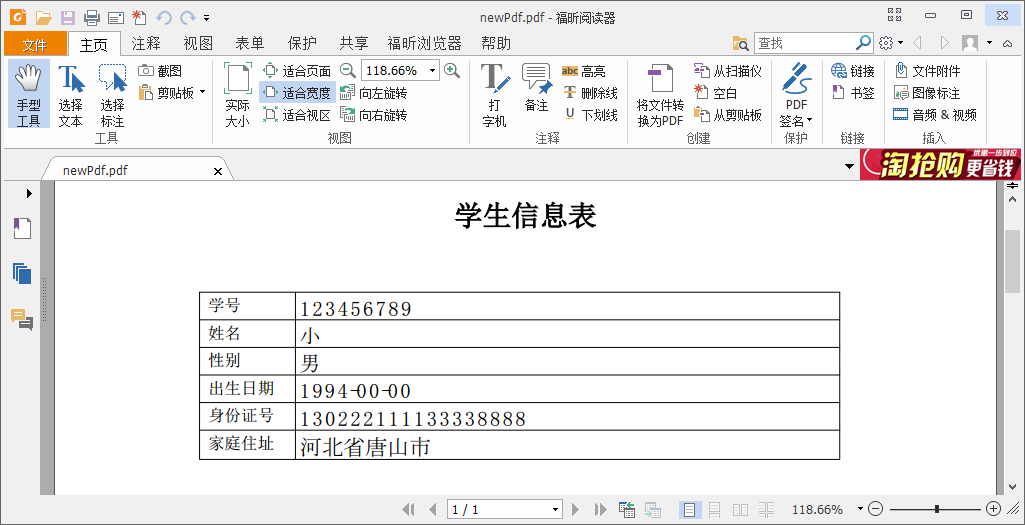
可以看到,少了一个鲁......于是我把模板的表单域的字体改成了宋体,结果中文一个也不显示了,所以我判断是他那个字体支持的中文比较少吧,先不管这个了
现在都两点多了(不是下午两点多啊。。。)
到此时,利用模板生成pdf已经over了,我再说说入门的hello word 级别的程序吧,反正闲着也是闲着
程序一:

1 public void test1(){//生成pdf 2 Document document = new Document(); 3 try { 4 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/1.pdf")); 5 document.open(); 6 document.add(new Paragraph("hello word")); 7 document.close(); 8 } catch (FileNotFoundException | DocumentException e) { 9 System.out.println("file create exception"); 10 } 11 }
结果:
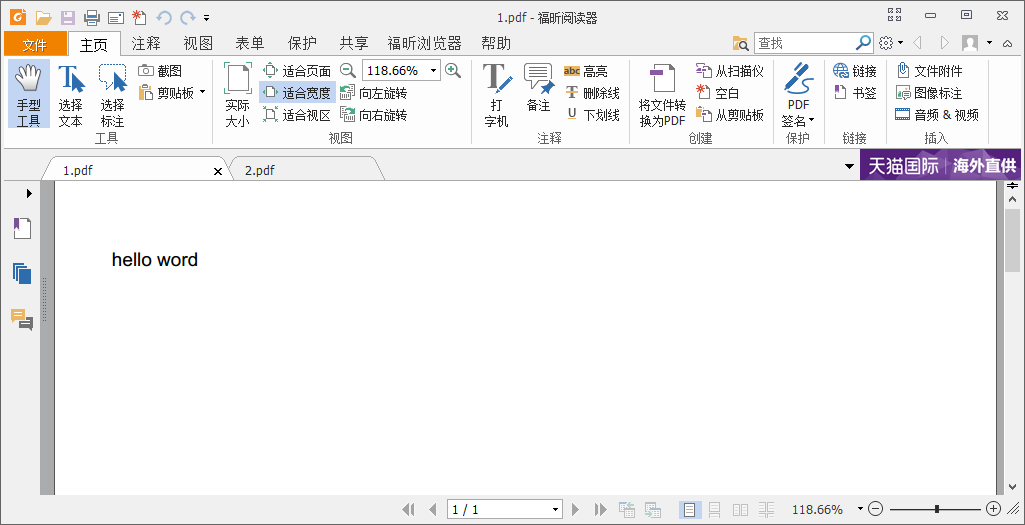
可是如果要输出中文呢,上面这个就不行了,就要用到语言包了
最新亚洲语言包:http://sourceforge.net/projects/itext/files/extrajars/
1 public void test1_1(){ 2 BaseFont bf; 3 Font font = null; 4 try { 5 bf = BaseFont.createFont( "STSong-Light", "UniGB-UCS2-H", 6 BaseFont.NOT_EMBEDDED);//创建字体 7 font = new Font(bf,12);//使用字体 8 } catch (DocumentException | IOException e) { 9 e.printStackTrace(); 10 } 11 Document document = new Document(); 12 try { 13 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/2.pdf")); 14 document.open(); 15 document.add(new Paragraph("hello word 你好 世界",font));//引用字体 16 document.close(); 17 } catch (FileNotFoundException | DocumentException e) { 18 System.out.println("file create exception"); 19 } 20 }
结果如下:
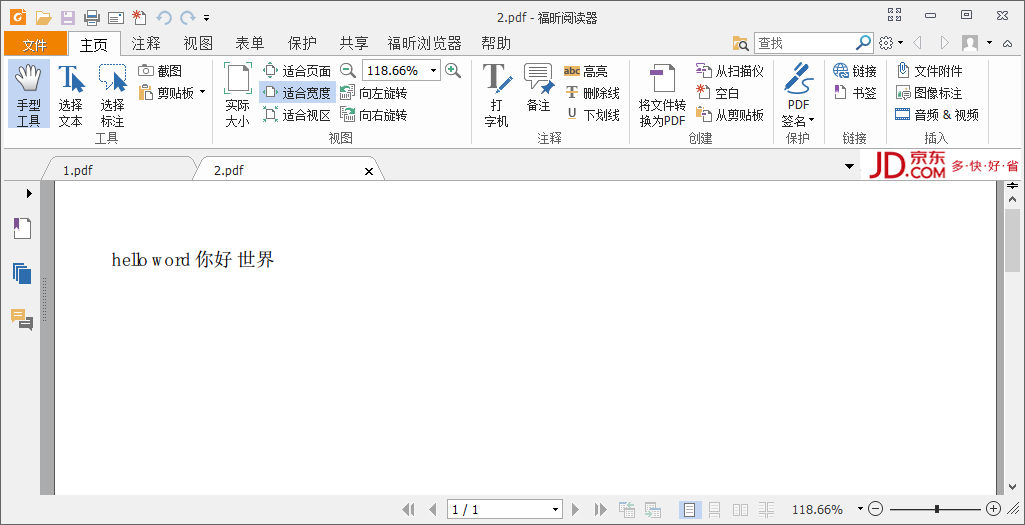
另外一种方法:我不用第三方语言包:
我是在工程目录里面新建了一个字体文件夹Font,然后把宋体的字体文件拷贝到这个文件夹里面了
上程序:
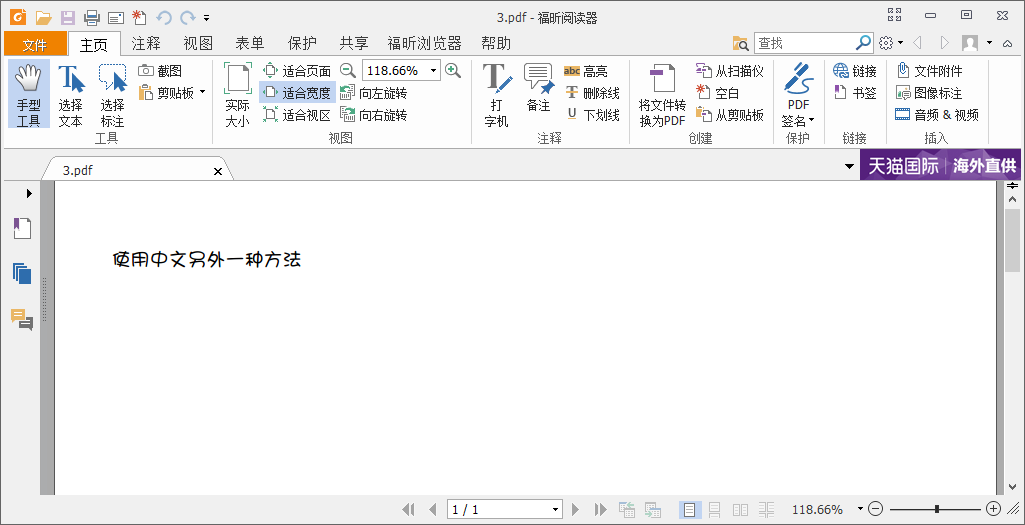
1 public void test1_2(){ 2 BaseFont bf; 3 Font font = null; 4 try { 5 bf = BaseFont.createFont("Font/simsun.ttc,1", //注意这里有一个,1 6 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 7 font = new Font(bf,12); 8 } catch (DocumentException | IOException e) { 9 e.printStackTrace(); 10 } 11 Document document = new Document(); 12 try { 13 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/3.pdf")); 14 document.open(); 15 document.add(new Paragraph("使用中文另外一种方法",font)); 16 document.close(); 17 } catch (FileNotFoundException | DocumentException e) { 18 System.out.println("file create exception"); 19 } 20 }
结果“:
我如果换成:华康少女文字W5(P).TTC,即
bf = BaseFont.createFont("Font/华康少女文字W5(P).TTC,1", //simsun.ttc
BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
哈哈,我喜欢图文并茂的教程02:44:58



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)