jieba库的使用和好玩的词云
I.三国演义和水浒传的词频统计:
#三国演义的词频统计 import jieba excludes = {"将军","却说","荆州","二人","不可","不能","如此"} txt = open("threekingdoms.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word == "诸葛亮" or word == "孔明曰": rword = "孔明" elif word == "关公" or word == "云长": rword = "关羽" elif word == "玄德" or word == "玄德曰": rword = "刘备" elif word == "孟德" or word == "丞相": rword = "曹操" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))
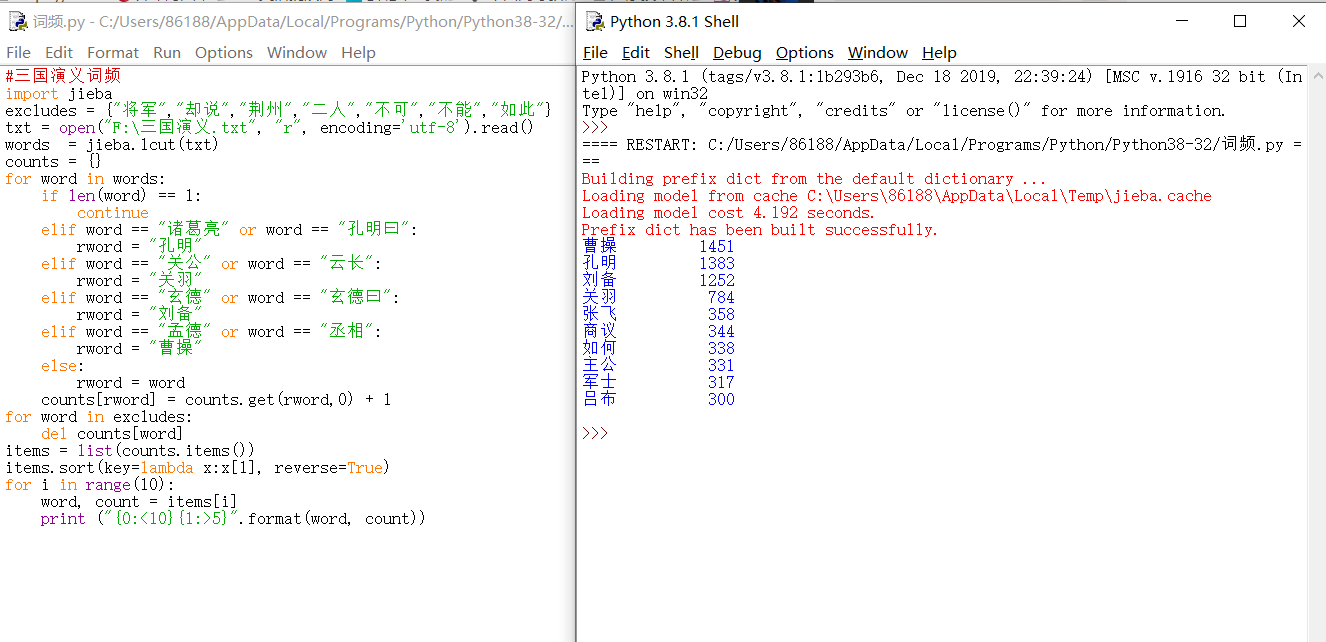
II.水浒传词频统计:
#水浒传词频 import jieba excludes = {"一个","说道","只见","如何","两个","众人","哥哥","这里","那里","今日","出来","军马","头领","兄弟","梁山泊"} txt = open("F:\水浒传.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word=="宋江道": rword="宋江" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))
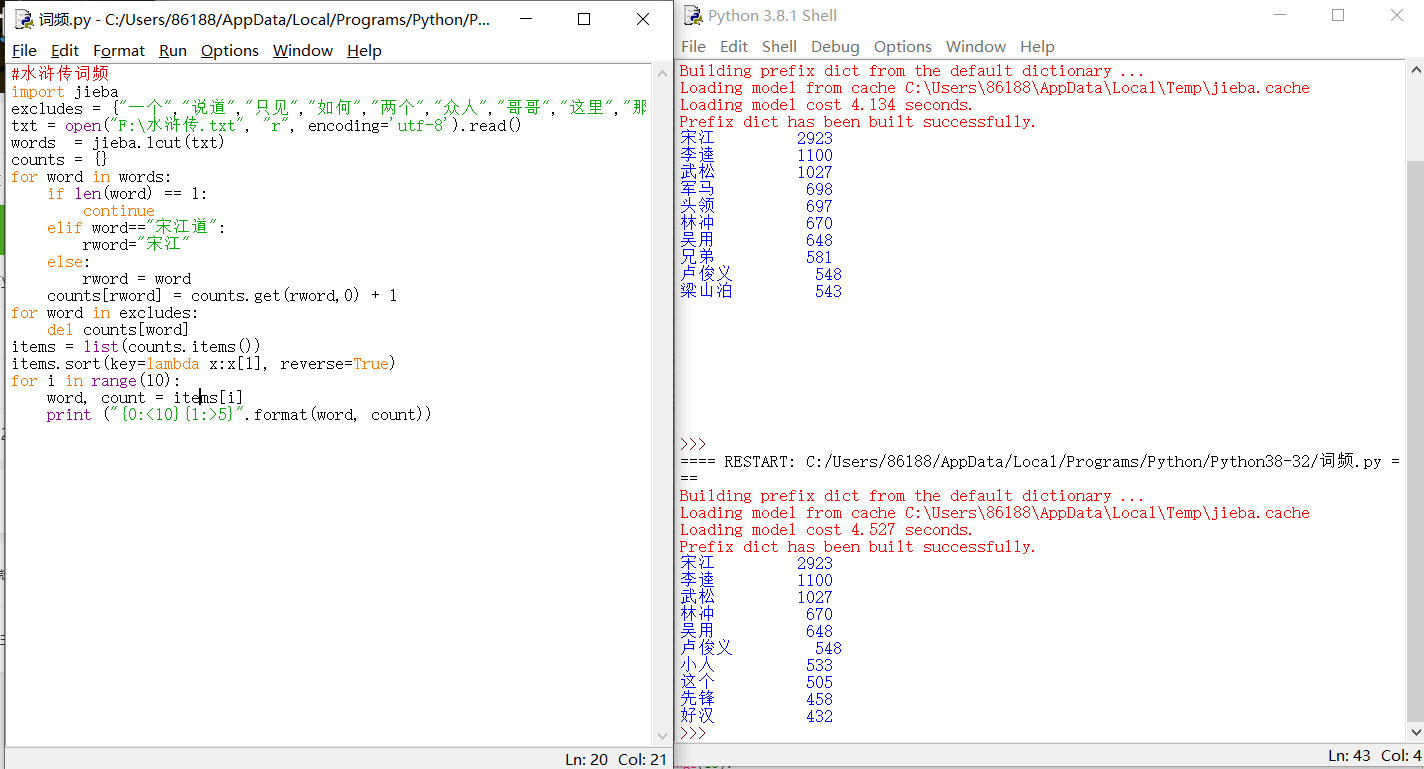
#水浒传词频 import jieba txt = open("F:\水浒传.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(15): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))

III.好玩的词云图:
#三国演义词云 import jieba import wordcloud f = open("F:\三国演义.txt", "r", encoding="utf-8") t = f.read() f.close() ls = jieba.lcut(t) txt = " ".join(ls) w = wordcloud.WordCloud( \ width = 1000, height = 700,\ background_color = "white", font_path = "msyh.ttc" ) w.generate(txt) w.to_file("grwordcloud.png")

#水浒传词云图 import jieba import wordcloud f = open("F:\水浒传.txt", "r", encoding="utf-8") t = f.read() f.close() ls = jieba.lcut(t) txt = " ".join(ls) w = wordcloud.WordCloud( \ width = 1000, height = 700,\ background_color = "white", font_path = "msyh.ttc",max_words=15 ) w.generate(txt) w.to_file("grwordcloud.png")
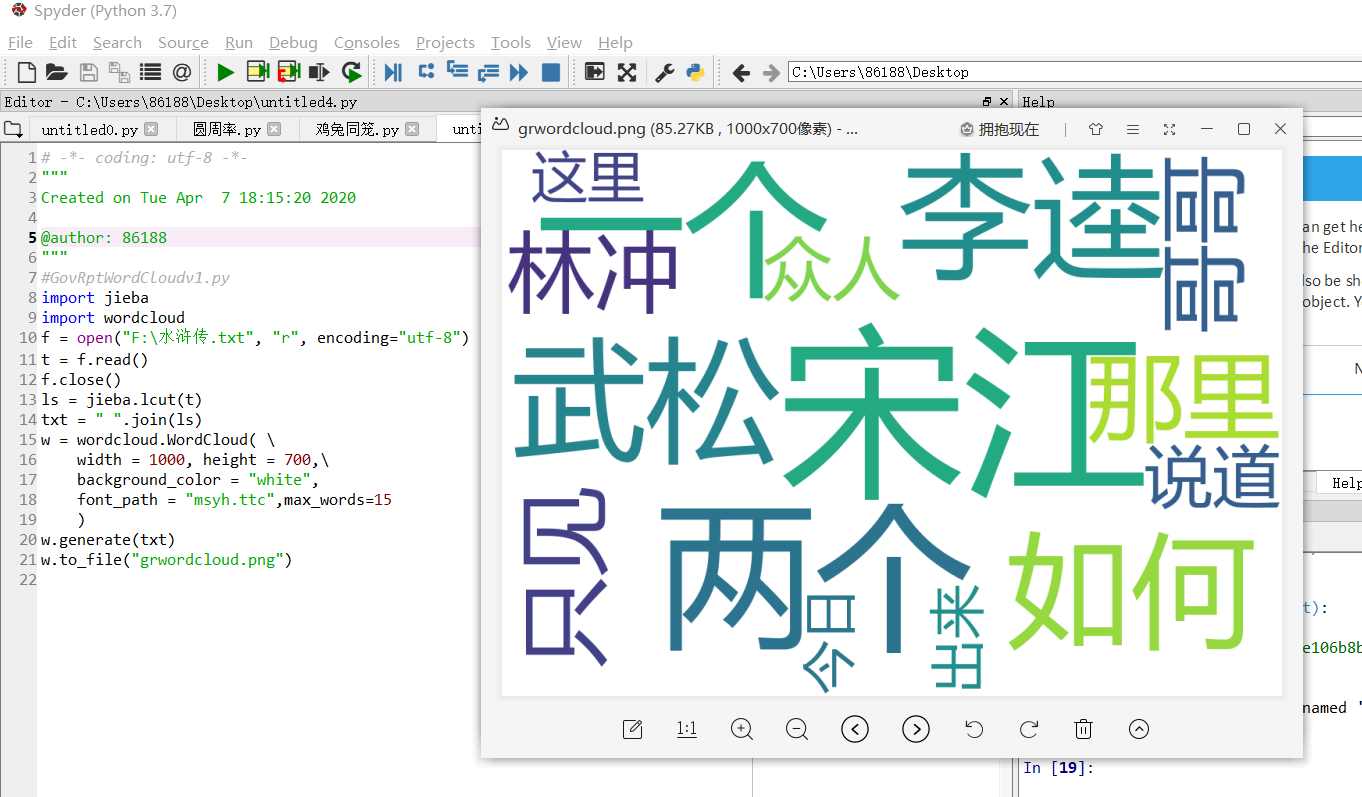

 浙公网安备 33010602011771号
浙公网安备 33010602011771号