一个SQL查询连续三天的流量100以上的数据值【SQql Server】
题目
有一个商场,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (date)、 人流量 (people)。请编写一个查询语句,找出高峰期时段,要求连续三天及以上,并且每天人流量均不少于100。
例如,表 stadium:
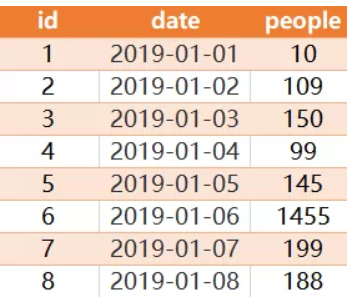
对于上面的示例数据,输出为:
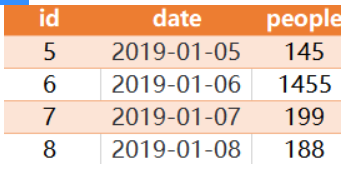
这个题的题意已经很明白了,就是要找出 连续三天(含)以上人流量都在100(含)以上的数据。
我用SQL Server 来做吧(因为别人都用MySql,正所谓:常在河边走,哪能都穿鞋?)
我做了点测试数据:
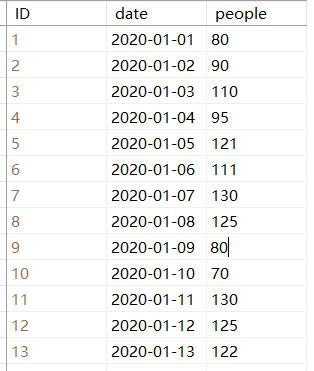
方法一:
这种题目的思路,就是找到那些数据是即 在100(含)以上,而且又是连续三天对吧?拆分一下思路:
1、每天人流量 >=100
2、连续的天数 要 >=3
你看 我又说了个废话对吧? >=100简单,但是 >=3 这个怎么来呢?也就是怎么求出连续天数呢?
举个例子来总结个规律:
1000 - 1 =999 1001 - 2 =999 1002 - 3 =999
发现了吗,如果一组“减数”和一组“被减数”都是递增的,那么他们的差是相同的哦!有没有猜到我要干嘛了?
先看一下满足第1步需的SQL
select * from stadium where people>=100
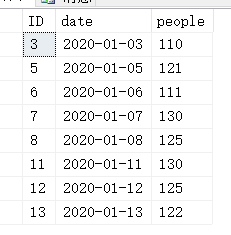
Q:这样之后呢?和刚才的规律有毛关系吗?
A:嗯 目前是没有的,但是 如果我给他们增加一列“递增的行号” rownum,和 一例“日期偏移量" dayOffset呢?只要日期连贯,这个dayOffset是否就也是连贯了呢(也就自增了哇)。看图吧
select *, row_number() over(order by [date]) as rownum ,datediff(day,'1990-1-1',[date]) dayOffset from stadium where people>=100
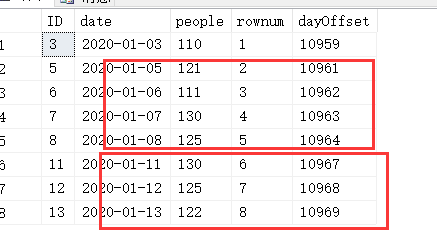
来观察一下,两个红色框的数据 是不是都是符合要求的?怎么取出来呢?
还记得前边总结的【如果一组“减数”和一组“被减数”都是递增的,那么他们的差是相同】的例子吗?这会要用上了
看代码:
select *,t1.dayOffset-t1.rownum flag from ( select *, row_number() over(order by [date]) as rownum ,datediff(day,'1990-1-1',[date]) dayOffset from stadium where people>=100 )t1

看到没有?“日期偏移量" -“递增的行号” 得到的值,如果是连续日期,得到的值相同,如果日期中断,就会得到一个新的值了,这个就不解释了吧
得到了这个值之后,我们是不是可以使用partition来做个分区求数量 最后过滤呢?来吧 就这样了
select *,count(*) over(partition by t2.flag) conDays from ( select *,t1.dayOffset-t1.rownum flag from ( select *, row_number() over(order by [date]) as rownum ,datediff(day,'1990-1-1',[date]) dayOffset from stadium where people>=100 )t1 )t2
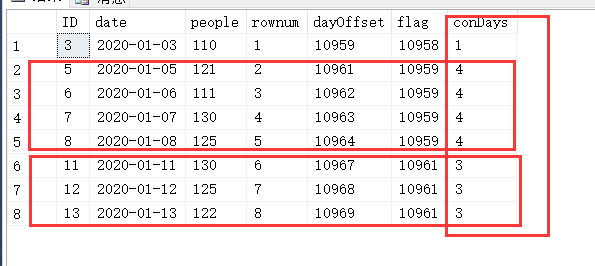
透彻了不?最后过滤一下 是不是就可以了?顺便只显示目标数据列就可以了:
select t3.ID,t3.[date],t3.people from ( select *,count(*) over(partition by t2.flag) conDays from ( select *,t1.dayOffset-t1.rownum flag from ( select *, row_number() over(order by [date]) as rownum ,datediff(day,'1990-1-1',[date]) dayOffset from stadium where people>=100 )t1 )t2 ) t3 where t3.conDays>=3

这种类型的题目还可以继续延伸:
比如:高峰期延续最久的时间段范围?
比如:高峰期持续最长的天数?
类似这种,都可以根据 日期偏移量和行号差的思路来做
方法二:
这个方法就很好理解了,3天对不?我假设每一天都是连续3天的第一天,如果连着三天的数据都是>=100那么这将时我的目标数据
select t1.id id1,t1.[date] date1,t1.people people1, t2.id id2,t2.[date] date2,t2.people people2, t3.id id3,t3.[date] date3,t3.people people3 from (select *,ROW_NUMBER() over(order by id) num from stadium) t1 join (select *,ROW_NUMBER() over(order by id) num from stadium) t2 on t1.num+1=t2.num join (select *,ROW_NUMBER() over(order by id) num from stadium) t3 on t2.num+1=t3.num where t1.people>=100 and t2.people>=100 and t3.people>=100
方法很简单,就是联合查询三次这个表,是每条数据都和他后边的两条数据关联。当然,最后两条数据忽略,因为最后两条数据已经出现在 倒数第三条数据中了,看查询效果吧

看看 我们要的数据 是不是都在这里边了?只是他们在同一个行中了,或者有重复数据了 对吧?没关系 我们把他们拿出来 就好了! 看代码
with tb as ( select t1.id id1,t1.[date] date1,t1.people people1, t2.id id2,t2.[date] date2,t2.people people2, t3.id id3,t3.[date] date3,t3.people people3 from (select *,ROW_NUMBER() over(order by id) num from stadium) t1 join (select *,ROW_NUMBER() over(order by id) num from stadium) t2 on t1.num+1=t2.num join (select *,ROW_NUMBER() over(order by id) num from stadium) t3 on t2.num+1=t3.num where t1.people>=100 and t2.people>=100 and t3.people>=100 ) select id1,date1,people1 from tb union select id2,date2,people2 from tb union select id3,date3,people3 from tb
这里with as 和 union我就不介绍了吧。看一下最终效果是不是一样的?
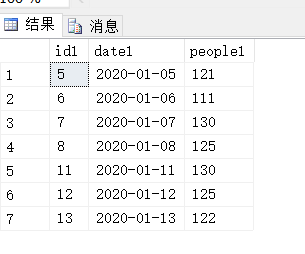
知识很简单,方法多的很。欢迎留言分享其他方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号