关于没有熔断降级导致服务重启问题
场景
1.k8s微服务触发重启
容器配置的健康检查采用actuator
curl 127.0.0.1:8080/actuator/health
2.容器重启钩子回调
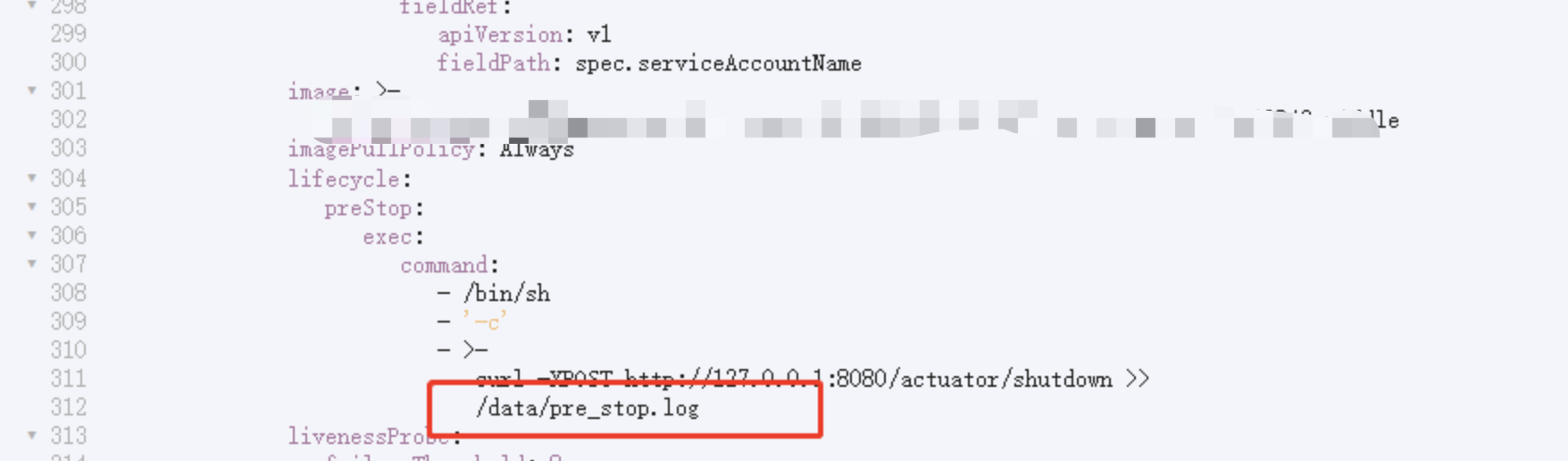
curl -X POST http://127.0.0.1:8080/actuator/shutdown
最终原因是因为调用第三方服务,超时设置3秒,重试3次,三方服务挂起导致tomcat连接池占满,健康检查请求进不来
总结

反思当时
当时是用户反馈才发现
1.首先触发重启需要进行告警
2.关于监测还需要通过error日志激增来进行告警,其实日志也有感知
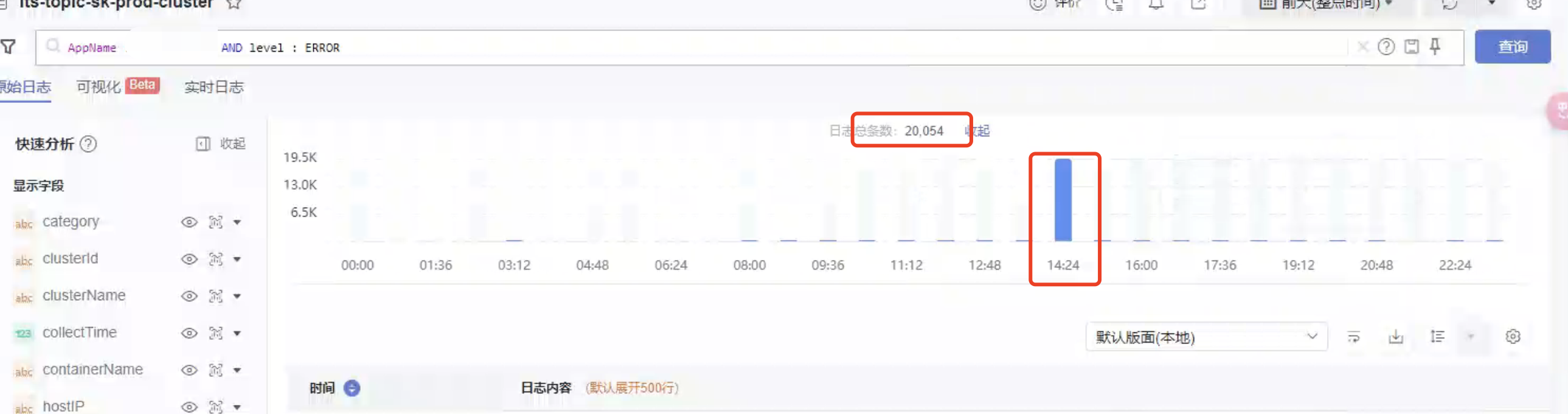
3.调用其他服务还是需要熔断降级,增对高并发场景,我们设置超时时间就算设置1秒,也会导致请求挂起一秒,
上熔断降级,短期内大量异常,直接熔断,过时间再少量尝试,正常了再放开
经验总结
当出现大面积超时排查步骤
1.结合jvm的线程来看当前活跃线程数量,主要看几种线程状态的数量 比如runable。
2.通过日志量看error是否激增,差异是啥
3.有链路追踪,可以结合链路追踪查看是否有大量耗时接口,和平均响应时间拉长,以及快速定位接口
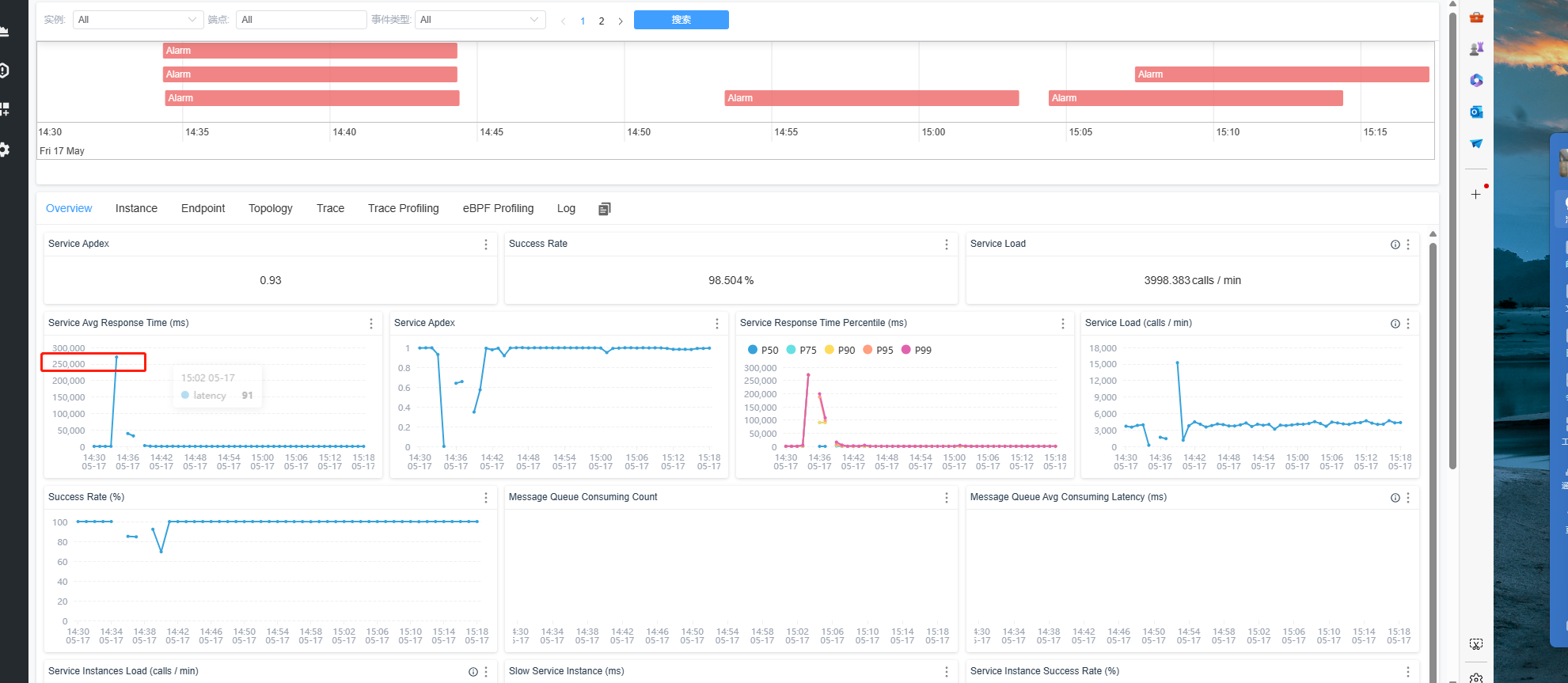
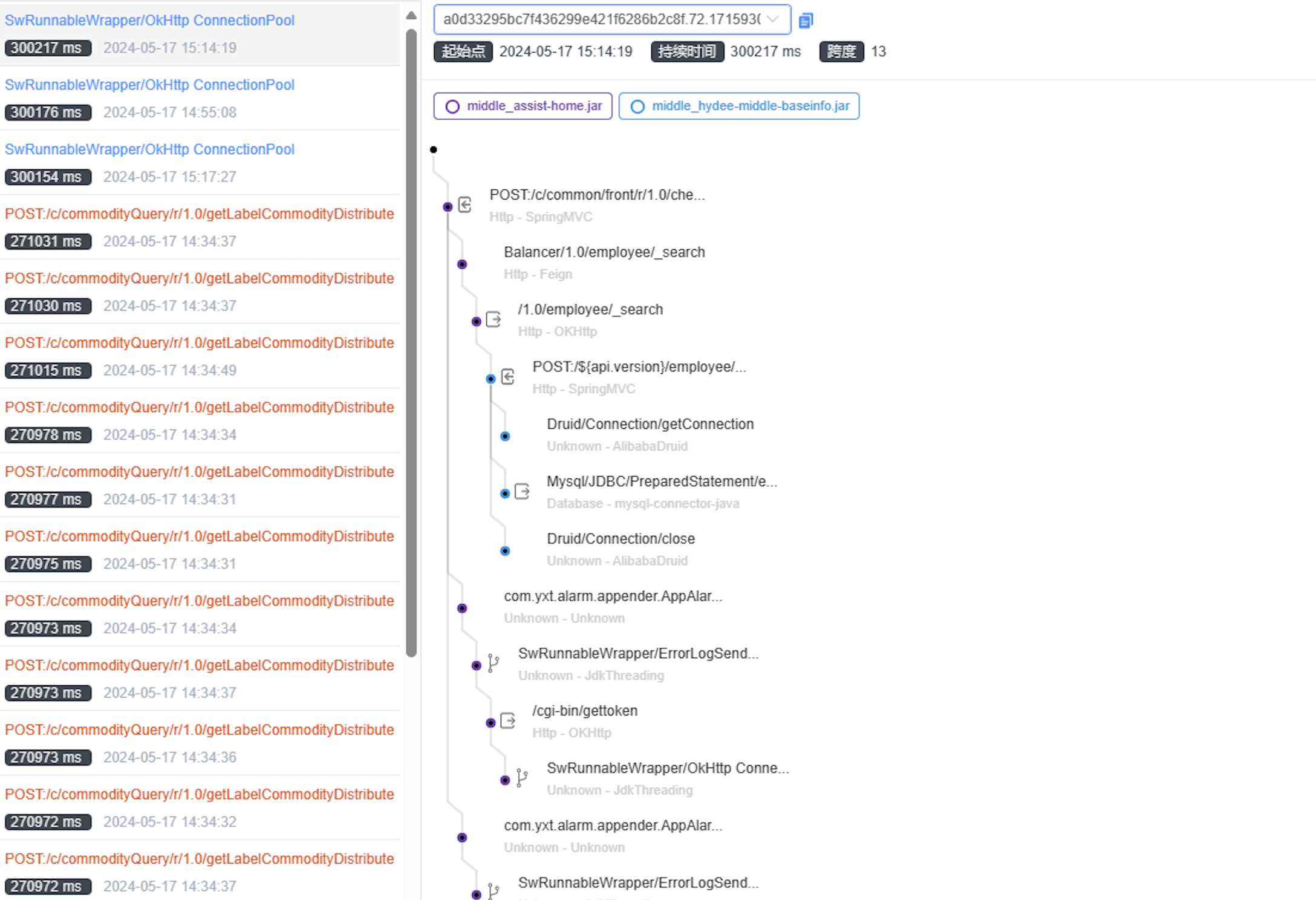
4.结合数据库挂起的慢查询
线程状态误区
1.本质问题是线程占满了导致,后续服务恢复看线程数量饱和度还是较高如下图
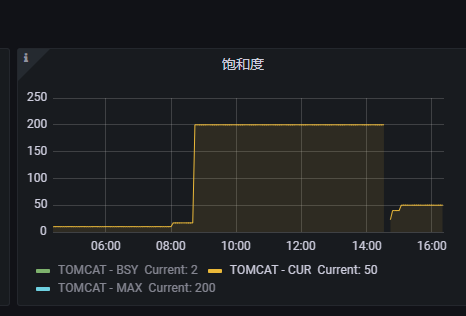
2.原因是这个服务是个并发较高的接口线程池有几个核心参数 核心线程数量 最大线程数量 线程队列 回收时间
3.其实这里面大量的线程是TIme_Waiting的线程,如果是paring的非runable过程中等待的是正常的
还需要结合队列中的任务数量
1.正常的
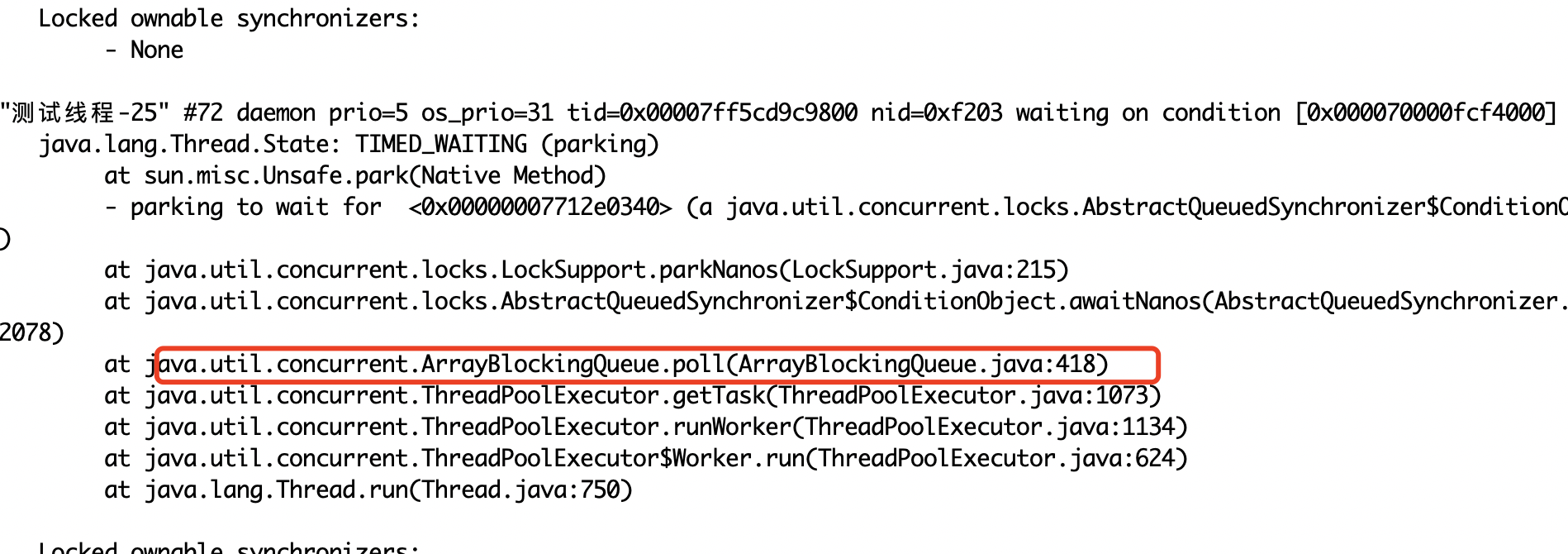
这种表示非核心线程在poll的时候尝试拿任务,指定时间内拿不到就表示空闲,触发回收(可以研究一下这里源码)
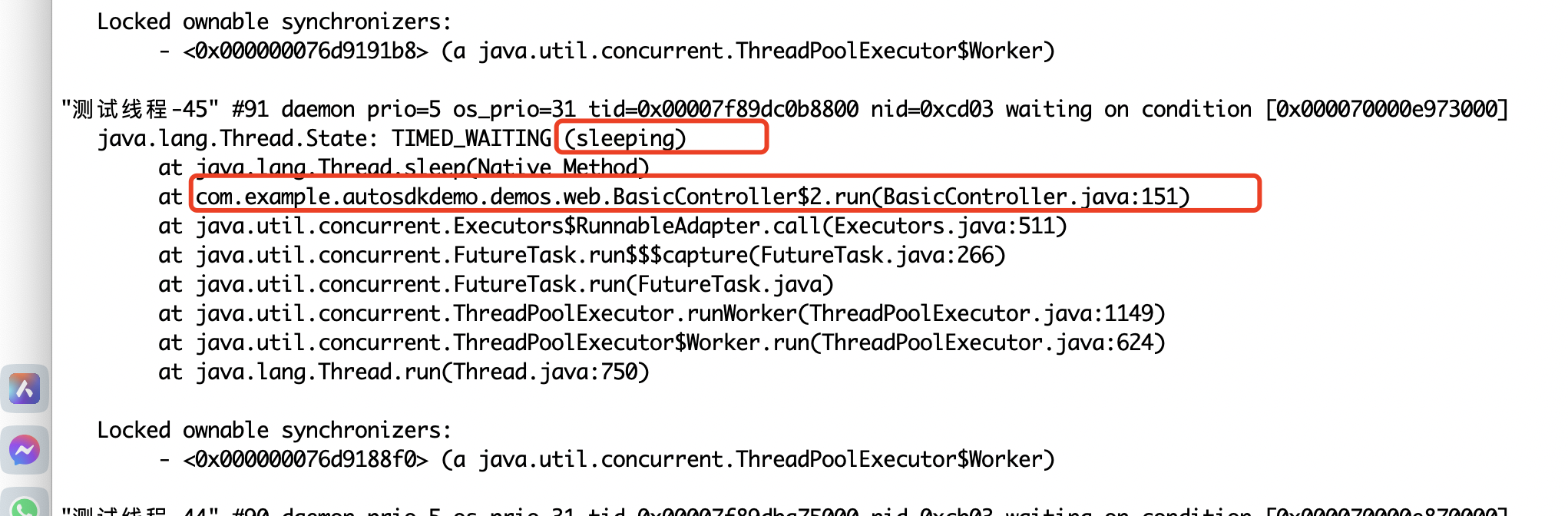
2.挂起的
业务挂起的都能看出来run挂起的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号