

datawhale-动手学数据分析task4笔记
动手学数据分析task4
数据可视化
基础matplotlib
-
matplotlib的图像都位于figure对象中,创建新的对象用
plt.figure。 -
plt.subplot()方法可以更方便地创建一个新figure,并返回一个含有以创建的subplot对象的numpy数组。''' 参数说明: - nrows=int,subplot的行数 - ncols=int,subplot的列数 - sharex=Bool/'none'/'all'/'row'/'col',所有subplot是否使用相同的x轴刻度(调节xlim将会影响所以的subplot) - sharey=Bool/'none'/'all'/'row'/'col',所有subplot是否使用相同的x轴刻度(调节ylim将会影响所以的subplot) - squeeze=Bool,是否返回生成图形的具体对象,如果False,则返回一个字图(numpy数组) - subplot_kw=dict,用于创建各subplot的关键字字典 - gridspec_kw=dict,指定子图网格的大小和比例 - **fig_kw,创建figure时的其他关键字 ''' # 以下有具体值的为默认值 plt.subplots(nrows=1, ncols=1, sharex=False, sharey=False, squeeze=True, subplot_kw=None, gridspec_kw=None, **fig_kw) -
plt.bar()函数可以刻画竖直柱状图。''' 参数说明: - x=float/list,表示x坐标 - y=float/list,表示柱状图的高度(y坐标) - width=float(0-1)/list,表示柱状图的宽度 - bottom=float/list,表示柱状图的起始位置 - align='center'/'edge',表示柱状图的中心位置 - label 表示标签 - color=color/color list 表示柱状图颜色,默认blue - linewidth=None/float 表示边框宽度 - linestyle 表示线条样式 ''' # 以下有具体值的为默认值 plt.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs) -
可对Series、DataFrame对象直接使用
.plot.bar()绘制柱形图。# 绘制柱形图 Series.plot.bar() # 为柱形图添加title,并展示 plt.title('...') plt.show() -
.plot()可直接将DF或series数据可视化。''' 参数说明: - x=label/position - y=None/label/labels/positions - kind=str,'line'折线图、'bar'竖直柱状图、'barh'水平柱状图、'hist'直方图、'box'箱线图、'kde''density'核密度估计图、'area'面积图、'pie'饼图、'scatter'散点图、'hexbin'六边形箱图 - stacked=Bool,是否堆叠图 ''' # 以下有具体值的为默认值 df.plot(*args, **kwargs) -
可以先将MutiIndex通过
.unstack()方法去掉多层索引然后再使用plot(kind='bar', stacked=True)创建堆叠图柱状图,如果去掉stcaked参数即可获得对比柱状图。
seaborn快速入门
-
直方图(displot)。
sns.displot()可以绘制直方图。''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 - data=df/series/list,需要绘制的数据 - kde=Bool,是否绘制密度估计曲线 - bins=int,控制分布矩形数量的参数 - rug=Bool,毛毯是否显示(代表数据点的位置) - width=float,控制直方图中每个柱子的宽度。 - hist_kw=dict,直方图直方的参数,通过字典显示color、lable... - kde_kw=dict,密度曲线的参数,通上hist - rug_kw=dict,同上 ''' # 以下有具体值的为默认值 sns.displot(df, kde=False, rug=False, width=0.8) -
条形图(barplot)。
sns.barplot()可以绘制条形图。''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 - data=df/series/list,需要绘制的数据 - hue=df中的变量,可以对x轴的数据进行细分,细分条件就是hue的参数 - orient='v'/'h',作图的方向v垂直,h水平 - order=list,控制轴上展示的顺序 - hue_order=list,控制轴上hue的展示的顺序 - width=float,控制条形的宽度 ''' # 以下有具体值的为默认值 sns.barplot(df, x, y, orient='v', width=0.8) -
计数图(countplot)。
sns.countplot()可以绘制计数图。''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴(改变水平或竖直仅需选择将变量传给参数x或y) - data=df/series/list,需要绘制的数据 - hue=df中的变量,可以对x轴的数据进行细分,细分条件就是hue的参数 - order=list,控制轴上展示的顺序 - hue_order=list,控制轴上hue的展示的顺序 - width=float,控制条形的宽度 ''' # 以下有具体值的为默认值 sns.countplot(df, x/y= ,width=0.8) -
散点图(stripplot/swarmplot)。
sns.stripplot()是用少量的随机“抖动”调整分类轴上的点的位置。''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 可以通过调换x/y轴,实现横向显示 - data=df/series/list,需要绘制的数据 - jitter=Bool/int,可以控制抖动的大小 - hue=df中的变量,对散点图添加更多细分的维度,其会以颜色来进行区分 - order=list,控制轴上展示的顺序 - width=float,控制每个类别的点的分布宽度 ''' # 以下有具体值的为默认值 sns.stripplot(df, x, y, jitter=True, width=0.8)sns.swarmplot()表示的是带分布属性的散点图,其使用防止它们重叠的算法沿着分类轴调整点,可以更好地表示观测的分布。''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 可以通过调换x/y轴,实现\横向显示 - data=df/series/list,需要绘制的数据 - hue=df中的变量,对散点图添加更多细分的维度,其会以颜色来进行区分 - order=list,控制轴上展示的顺序 - width=float,控制每个类别的点的分布宽度 ''' # 以下有具体值的为默认值 sns.swarmplot(df, x, y, jitter=True, width=0.8) -
箱线图(boxplot)。
boxplot(箱线图)是一种用作显示一组数据分散情况的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。
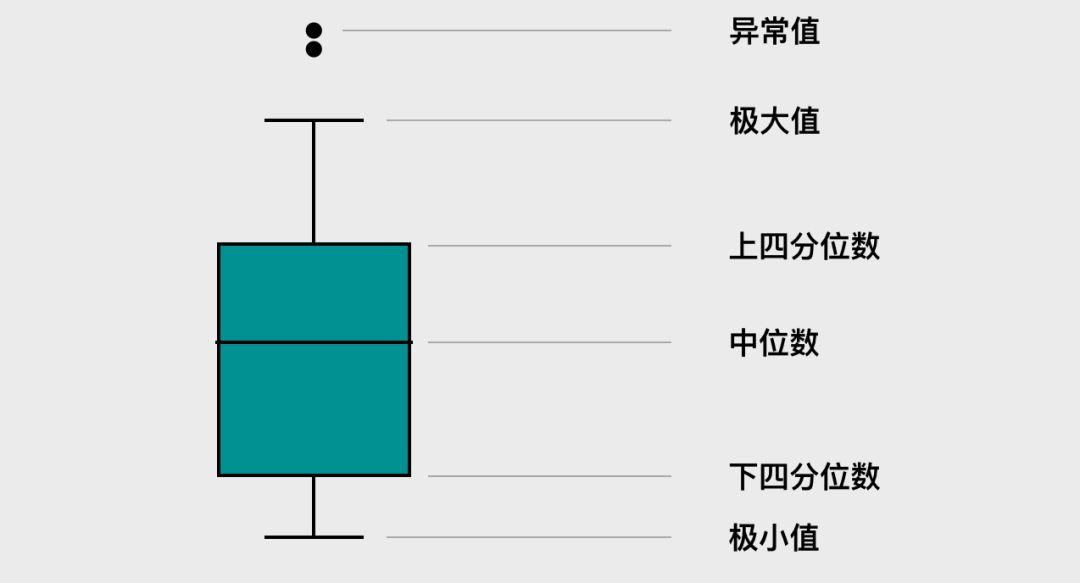
''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 可以通过调换x/y轴,实现箱线图的横向显示 - data=df/series/list,需要绘制的数据 - hue=df中的变量,对x轴的字段进行细分 - order=list,控制x轴上展示的顺序 - hue_order=list,控制x轴上hue的展示的顺序 - width=float,控制箱体的宽度 - linewidth=float,控制线条的粗细 ''' # 以下有具体值的为默认值 sns.boxplot(df, x, y) -
小提琴图(violinplot)。
小提琴图是箱线图与核密度图的结合,其展示了任意位置的密度。
在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须。外部形状即为核密度估计。
''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 可以通过调换x/y轴,实现横向显示 - data=df/series/list,需要绘制的数据 - hue=df中的变量,对x轴的字段进行细分 - split=Bool,当hue参数只有两个级别时,通过设置此参数“拆分”小提琴,使提琴两边分别表示两个分类的情况 - inner=None/'box'/'stick'/'quart'/'point' None不绘制任何东西,point在内部为每个观测值绘制一个点,quart在内部绘制四分位数线,stick在内部,为每个观测值绘制一条垂直的线 - order=list,控制x轴上展示的顺序 - hue_order=list,控制x轴上hue的展示的顺序 - width=float,控制内部的核密度估计的宽度 - linewidth=float,控制线条的粗细 ''' # 以下有具体值的为默认值 sns.violinplot(df, x, y) -
回归图(regplot/lmplot)。
''' 简易参数说明: - x=df中的变量,x轴 - y=df中的变量,y轴 可以通过调换x/y轴,实现横向显示 - data=df/series/list,需要绘制的数据 - ci=None/int(0-100),是否绘制估计的置信区间(一个估计值的不确定性范围)以及该区间的宽度 - color=matplotlib color,图形的颜色 - marker=matplotlib marker code/list,数据点的形状 - linewidth=float,控制回归线的粗细 - fit_reg=True,是否显示拟合的直线 ''' # 以下有具体值的为默认值 sns.regplot(df, x, y, ci=95, color=None)在
lmplot()中还可使用hue参数,如果使用col代替hue参数即可将不同的类别分开绘制。 -
热力图(heatmap)。
热力图通常用来表示特征之间的相关性,一般通过颜色的深浅来表示数值的大小或者相关性的高低。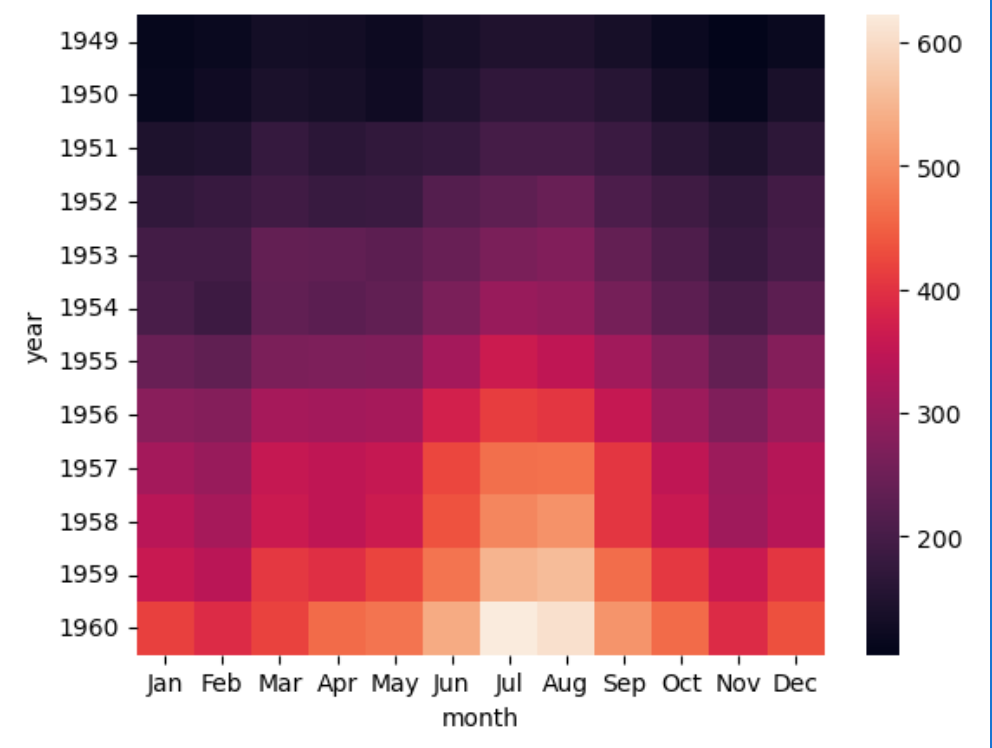
# 一般先将df数据用pivot(index, column, value)方法重塑。 df.pivot(index= , column= , value= ) # 然后再进行热力图的绘制 # annot=Bool,annot参数控制是否显示数值 sns.heatmap(f)
