

datawhale-动手学数据分析task3笔记
动手学数据分析task3
数据重构
数据合并
-
.concat()函数可以基于整体合并DF和Series,包括columns合并和index合并。''' 参数说明: - objs=sequence/mapping,其元素是要合并的Dataframe或series - axis=0/1,沿着行/列合并 - join='outer'/'inner',合并时索引对齐方式 outer是单独拼接无改变(即index拼接时,index直接累加,而columns取并集,缺失值填充NaN),而inner是交联拼接(即index拼接时,index直接累加,而columns只保留交集的columns) - ignore_index=Bool,是否忽略掉原来的数据索引(即是否重新排序) - keys=None/sequence,合并DF后的index标签(即原index在DF合并后的index,与level相反,keys是分别的index而levels是合并的inex) - levels=None/sequence,合并需要合并的index后的index - names=None/list,为MultiIndex(多级索引)中的每个级别命名 - verify_integrity=Bool,检查新连接的轴是否包含重复项 - sort=Bool,True时,连接后的轴标签将根据字典顺序进行排序 - copy=Bool,True时,会返回副本,False则返回原始数据 ''' # 以下有具体值的为默认值 pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True) -
当多个index和columns都需合并时,可以采取多次
pd.concat()合并。 -
.join()方法可以基于index键合并DF。''' 参数说明: - other=Dataframe/Series,其是要合并的内容 - on=None/str/str list,指定合并columns,会基于on指定的columns进行合并DF,即保留指定的column中的相同value的index - how='left'/'right'/'outer'/'inner'/'cross',连接方式,即使用指定DataFrame的index(合并后非指定DF),inner则是使用交集index,outer是使用并集index。 - lsuffix=''/str,即为left DF中交集的index加的后缀 - rsuffix=''/str,同上,但为right DF - sort=Bool,True时,连接后的轴标签将根据字典顺序进行排序 - validate=None/'1:1'/'1:m'/'m:1'/'m:m',检查合并index是否有重复值,如果是'1:m'则允许right DF有重复index,其余同理 ''' # 以下有具体值的为默认值 df.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False, validate=None) -
.merge()函数是基于column键合并DF和Series。''' 参数说明: - left=right=Dataframe/Series,其是要合并的内容 - how同上join - on同上join - left_on=None/str/str list,left DF指定合并columns,同on,但是是left_on与right_on替代了on - left_index=Bool,如果True,则使用left DF的index作为合并键 - right_index=Bool,如果True,则使用right DF的index作为合并键 - sort同上join - suffixes=(left_str, right_str),即为DF中交集的index分别加的后缀 - copy=Bool,True时,会返回副本,False则返回原始数据 - indicator=Bool/str,如果True,将添加一个名为_merge的列到输出DF中,显示每行数据的来源('left_only', 'right_only', 'both'),如果为字符串,则用作该列的列名 - validate同上join ''' # 以下有具体值的为默认值 pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=None, indicator=False, validate=None) -
.concat()和.join()、.merge()的区别:-
.concat()函数偏重于沿着一个特定的轴连接两个或多个DF或Series对象。 -
.join()函数偏重于基于一个或多个index键合并两个DF对象(必须有合并的键),但on参数是可选的。 -
.merge()函数偏重于基于一个或多个columns键合并两个DF对象(必须有合并的键),但on参数是必需的(如果启用index作为合并键则不需要)。 -
.join()和.merge()要想实现.concat效果可以配合append方法。
-
有关数据和并部分方法的Blog可以参考:Pandas拼接操作与官方wiki
转变数据类型
-
可以用iloc将DF转化为series:
for i in df.index: pf=result.iloc[i,:] pfs.append(pf) -
.stcak()方法可以将DF的列旋转成行,从而将DF转化为Series。''' 参数说明: level=int/str,用于指定从哪个级别开始堆叠,-1即最内层级别 dropna=Bool,是否删除结果中缺少值的行 sort=Bool,是否排序index future_stack=Bool,是否使用新的stack方法 ''' # 以下有具体值的为默认值 DataFrame.stack(level=-1, dropna=True, sort=True, future_stack=False)
数据聚合与运算
groupby机制
-
Groupby用于将数据集按照一个或多个指定的column进行分组,并对每个分组应用某些操作或函数,从而得到每个分组的统计信息或其他计算结果。
-
通过
.groupby()方法即可生成groupby类型对象。''' 参数说明: by=None/column/columns,进行分组的column,多columns会按这些列的值的组合进行分组(多类分组),None不分组 level=int/level name,如果columns是一个MultiIndex,则按照级别编号或名称分组 sort=Bool,分组之前是否对数据进行排序 group_keys=None/Bool,是否保留分组键 observed=Bool,是否只显示实际观察到的类别 dropna=Bool,是否删除不含任何数据的组 ''' # 以下有具体值的为默认值 df.groupby(by=None, level=None, as_index=True, sort=False, group_keys=no_default, observed=True, dropna=True) -
groupby使用示例,groupby后的数据也是一种数据类型。
-
假设你想要按key1进行分组,并计算data1列的平均值。
df = pd.DataFrame({ 'key1' : ['a', 'a', 'b', 'b', 'a'], 'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})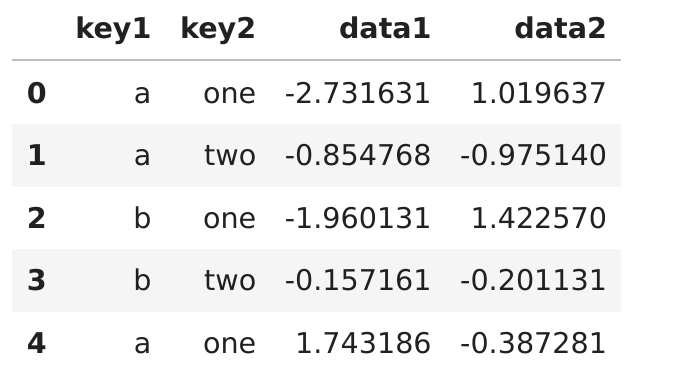
# 访问data1,并根据key1调用groupby grouped = df['data1'].groupby(df['key1']) grouped.mean()
-
假设一次传入多个数组
means = df['data1'].groupby([df['key1'], df['key2']]).mean()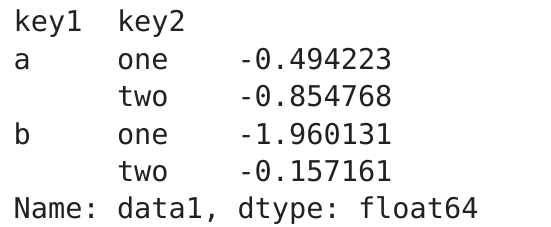
-
分组键可以是任何长度适当的数组。
states = np.array(['oh', 'ck', 'ck', 'oh', 'oh',]) years = np.array([2005, 2005, 2006, 2005, 2006]) df['data1'].groupby([states, years]).mean()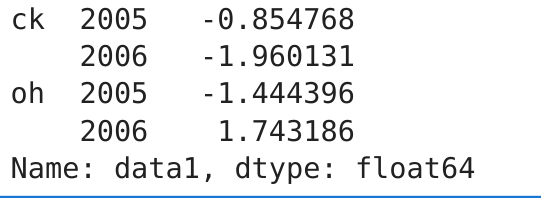
- 任何分组关键词中的缺失值,都会被从结果中除去。
-
-
可以对分组进行迭代。
for name, group in df.groupby('key1'): print(name) print(group)
for (k1, k2), group in df.groupby(['key1', 'key2']): print((k1, k2)) print(group)
-
groupby()语法糖。df.groupby('key1')['data1'] df.groupby('key1')[['data2']] # 等价于,是以下的语法糖 df['data1'].groupby(df['key1']) df[['data2']].groupby(df['key1']) -
grouby传入list和传入标量的区别。
# 输出的是DataFrame,如果传入的是list df.groupby(['key1', 'key2'])[['data1']].mean() # df[['data1']].groupby([df['key1'], df['key2']]).mean() # df[['data1']].groupby(['key1', 'key2']).mean()# 输出的是Series,如果传入的是标量 df.groupby(['key1', 'key2'])['data1'].mean() -
groupby()分组还可以通过字典或Series,还有函数和索引级。# 可以通过字典或Series进行分组 people = pd.DataFrame( np.random.randn(5, 5),columns=['a', 'b', 'c', 'd', 'e'],index=(['Joe', 'Steve', 'Wes', 'Jim', 'Travis'] ))\ mapping = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'} by_column = people.T.groupby(mapping)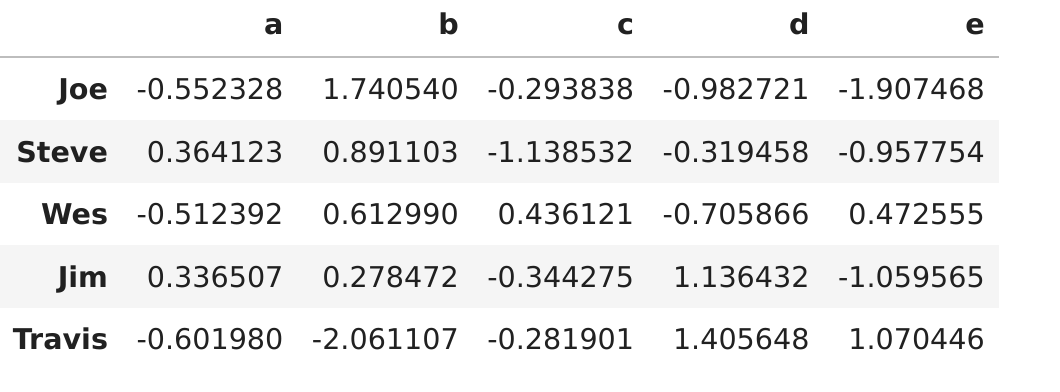
groupby聚合
-
聚合指的是任何能够从数组产生标量值的数据转换过程。
-
聚合可以使用自定义的聚合运算,也可以调用分租对象上已经定义好的任何方法。
-
如果使用自己的聚合函数,只需将其传入aggregate(agg)方法。
df method(arr): ... grouped.agg(method) -
对Series或DataFrame列的聚合运算其实就是使用aggregate或调用方法。
grouped.mean() == grouped.agg('mean') -
如果传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名。
如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的column名。grouped.agg(['fun1', 'func2'...]) grouped.agg([('name1', 'func1'), ['name2', 'func2']...]) -
如果想要对同一个column或不同的columns应用不同的函数,则需要向agg传入一个从列名映射到函数的字典。
grouped.agg({'name1' : [func1, func2], 'name2': func2}) -
如果想返回没有分组建组成的index索引,可以在groudby函数传入as_index=False禁用。
grouped的apply的应用
-
“拆分-合并-应用”,groudby最通用的方法apply。
grouded.apply(func) -
如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名一并传入。
grouded.apply(func, param1, param2...) -
在groupby中,当调用诸如describe之类的方法,实际上只是应用了快捷方式。
f = lambda x: x.describe() grouped.apply(f) -
可以将grouped_keys传入groupby从而禁止分组键。
