CUDA基础
CUDA基础
不错的文章
https://www.cnblogs.com/timlly/p/11471507.html
https://zhuanlan.zhihu.com/p/76297133
NVIDIA GPU 架构梳理
在英伟达的设计理念里,CPU和主存被称为Host,GPU被称为Device。Host和Device概念会贯穿整个英伟达GPU编程
GPU与CUDA介绍
CPU与GPU
CPU:central processing unit,简称CPU,中央处理器,是计算机系统的运算和控制核心。
GPU:Graphics Processing Unit,简称GPU,图形处理单元。最初GPU只用在显示器上渲染高端图形。它们只用于像素计算。后来,人们意识到如果可以做像素计算,那么他们也可以做其他的数学计算。现在,GPU除了用于渲染图形图像外,还用于其他许多应用程序中,用做数据处理。
它们都是由计算单元、控制单元和存储单元组成,其架构如下。
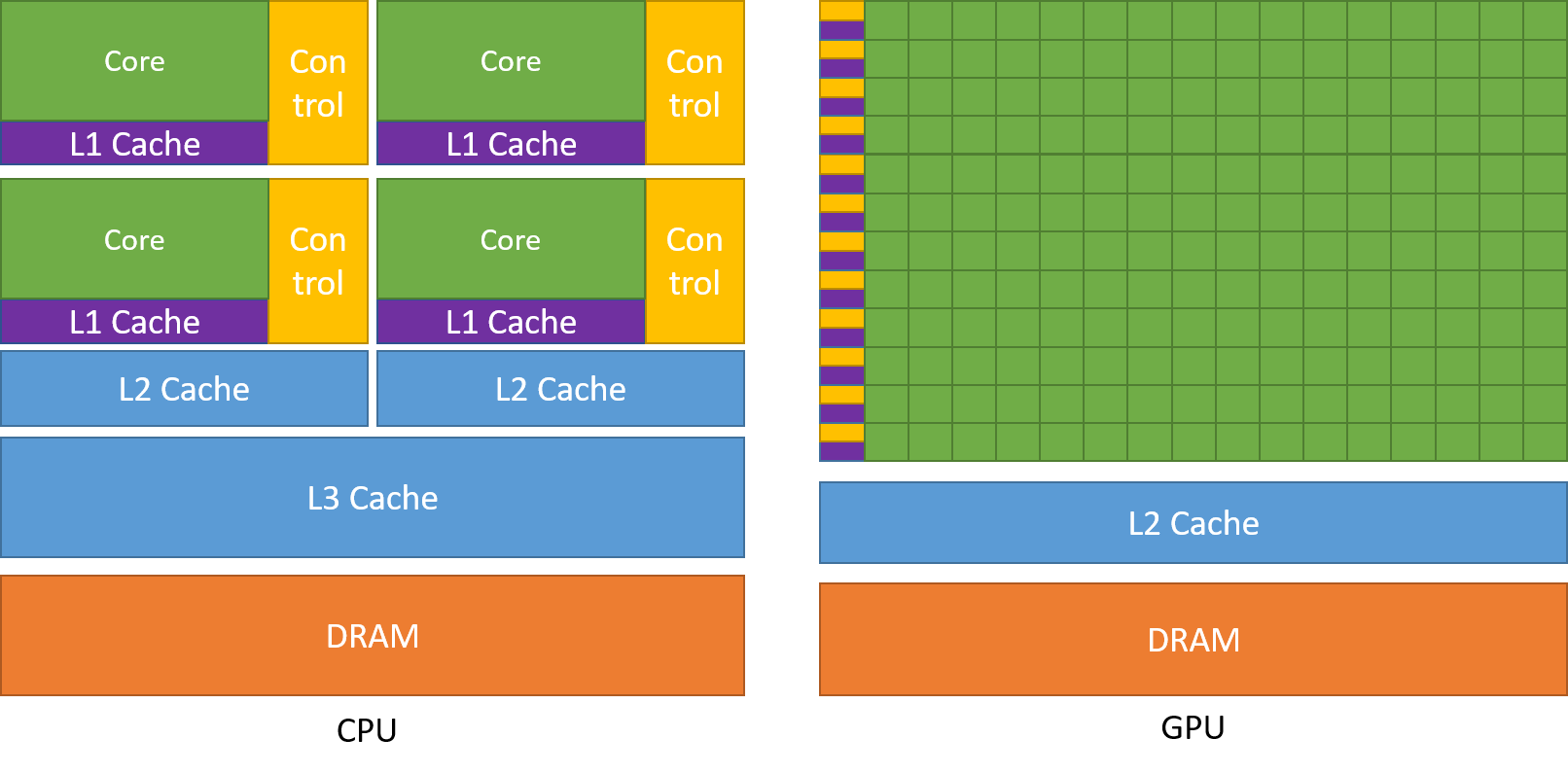
从上图可以看出,CPU这边起码30%是控制单元,各个单元占比还算均衡,而GPU就夸张了,80%以上都用在了计算单元。正是由于这种区别,导致CPU与GPU的差异:
-
CPU精于控制和复杂运算, 被设计为以尽可能快的速度执行一系列线程(thread)操作,并且可以并行执行几十个这样的线程。
-
GPU 被设计为并行执行数千个线程(实现更大的吞吐量),专门用于高度并行的计算。
基于CPU与GPU的区别,我们很容易能够想出,综合利用其各自优势,协同工作,由CPU承担控制、GPU承担大量计算,以最大限度地提高整体性能。
CUDA介绍
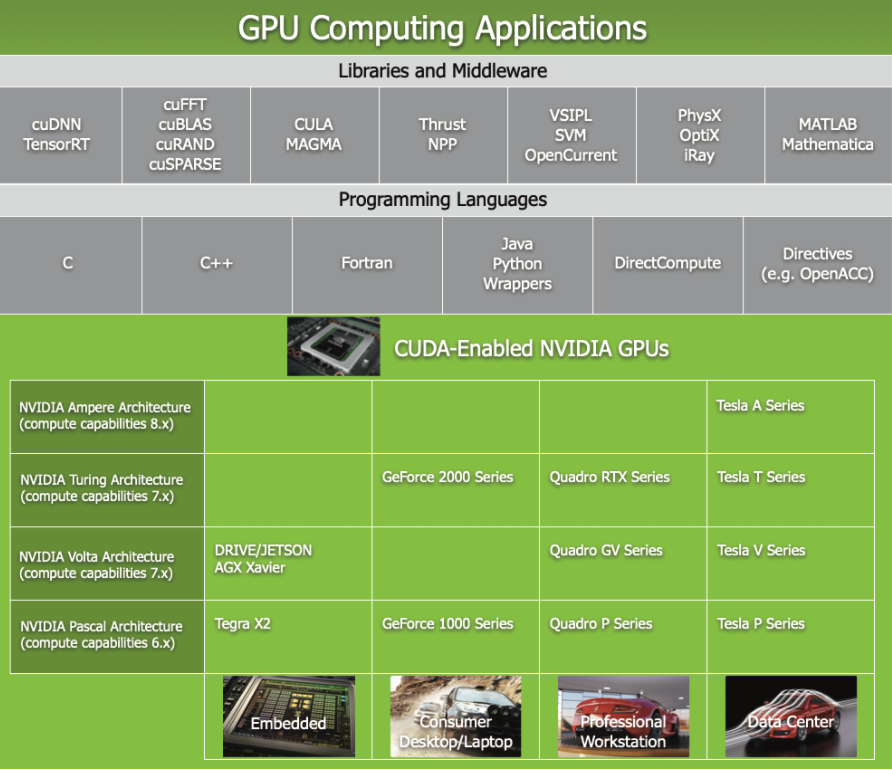
为了使开发人员能够充分利用GPU强大的运算能力,并且实现与CPU的协调工作,NVIDIA 推出了 Compute Unified Device Architecture,CUDA,这是一种通用并行计算平台和编程模型。如下图所示,CUDA的作用就是使开发人员通过高级编程语言,方便的使用GPU完成特定功能,相当于对GPU做了抽象。
CUDA 附带一个软件环境,允许开发人员使用 C++ 作为高级编程语言,添加需要利用GPU并行性的关键字。CUDA允许程序员指定CUDA代码的哪个部分在CPU上执行,哪个部分在GPU上执行。
CUDA的核心
CUDA的核心是三个关键概念——线程组层次结构(a hierarchy of thread groups)、共享内存(shared memory)和屏障同步(barrier synchronization)。
这些概念提供了细粒度数据并行性和线程并行性,嵌套在粗粒度数据并行性和任务并行性中。它们指导程序员将问题划分为可以由block独立并行解决的粗略子问题,并将每个子问题划分为可以由block内的所有线程并行协作解决的更精细的部分。
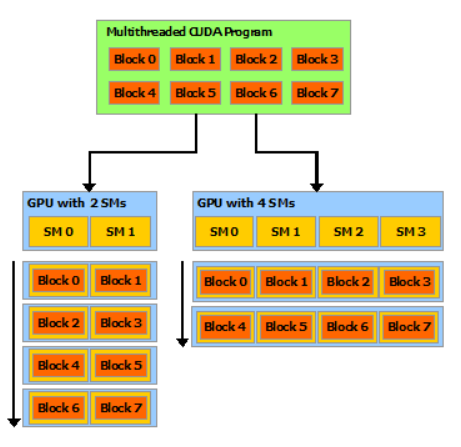
每个线程块都可以在 GPU 内 任何可用的 多处理器上以任何顺序、并发或顺序进行调度,以便编译后的 CUDA 程序可以在任意数量的多处理器上执行,如下图所示,并且只有运行时系统需要知道物理多处理器数量。
异构编程
也就是CPU与GPU协同工作。
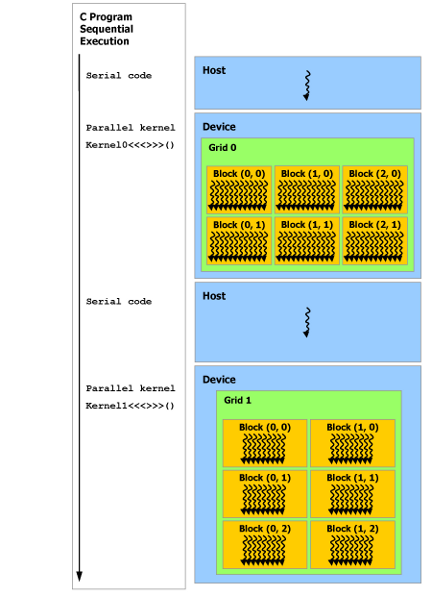
如上图所示,CUDA 编程模型假设 CUDA 线程在物理上独立的设备上执行,该设备作为运行 C++ 程序的主机的协处理器运行。例如,当kernel在 GPU 上执行而 C++ 程序的其余部分在 CPU 上执行。
CUDA 编程模型还假设主机和设备都在 DRAM 中维护自己独立的内存空间,分别称为主机内存和设备内存。因此,程序通过调用 CUDA 运行时(在编程接口中描述)来管理内核可见的全局、常量和纹理内存空间。这包括设备内存分配和释放以及主机和设备内存之间的数据传输。统一内存提供managed 内存来桥接主机和设备内存空间。managed 内存可从系统中的所有 CPU 和 GPU 访问,作为具有公共地址空间的单个、连贯的内存映像。
CPU-GPU数据流
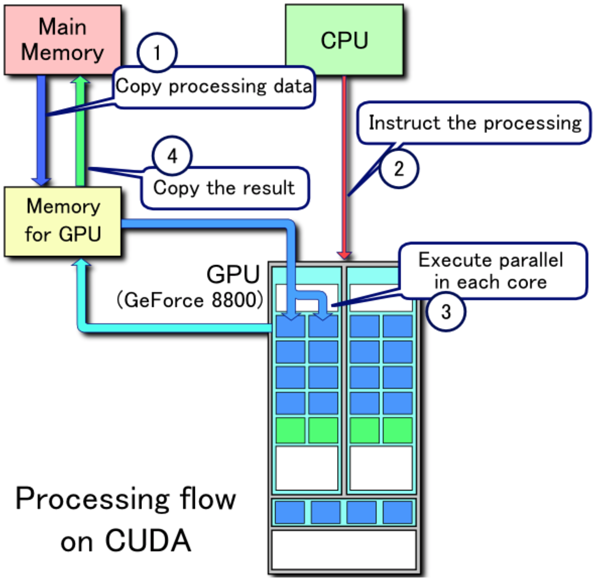
上图是CPU与GPU采用分离式架构,通过PCI-e等总线通讯时的数据流。
1、将主存的处理数据复制到显存中。
2、CPU指令驱动GPU。
3、GPU中的每个运算单元并行处理。此步会从显存存取数据。
4、GPU将显存结果传回主存。
显卡硬件架构介绍
要继续了解CUDA,首先就需要了解显卡的几个硬件架构。
SP(streaming processor)
最基本的处理单元,之前也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM(streaming multiprocessor 流式多处理器)
多个SP加上其他的一些资源组成一个SM,也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。如下图是pascal架构的GP100核心的一个SM的基本组成,其中每个绿色小块代表一个SP。
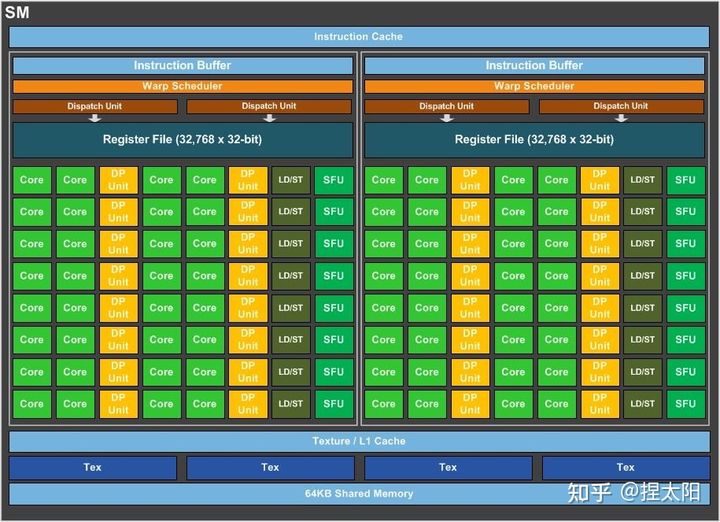
如上图,单个SM包含:
- 64个运算核心 (Core,也叫流处理器Stream Processor)
- 16个LD/ST(load/store)模块来加载和存储数据
- 16个SFU(Special function units)执行特殊数学运算(sin、cos、log等)
- 256KB寄存器(Register File)
- L1缓存
- 全局内存缓存(Uniform Cache)
- 纹理读取单元
- 纹理缓存(Texture Cache)
- 2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
- 指令缓存(Instruction Cache)
- 32 个DP双精度运算单元
CUDA context
类似于CPU进程上下文的概念,表示了管理由Driver层分配的资源(例如某个指针,指向一段显存;或者某个纹理对象)的生命周期。在每次运行cuda的第一个函数时,cuda会进行initialization,这时就会创建cuda context。cuda函数的调用都需要context来管理。
多线程分配调用的GPU资源一般情况下同属一个context下,通常与CPU的一个进程对应。但是有了MPS(Multi Process Service)之后,多个CPU进程可以共享同一GPU context,不同进程的kernel和memcpy操作在同一GPU上并发执行,以实现最大化 GPU利用率、减少GPU上下文的切换时间与存储空间。
与CPU进程的管理类似,每个Context有自己的地址空间,之间是隔离的,在一个Context中有效的东西(例如某个指针,指向一段显存,或者某个纹理对象),只能在这一个Context中使用。
一个CUDA Context中的任何一个kernel,挂掉后,则整个Context中的所有东西都会失效(例如所有的缓冲区,kernel对象,纹理对象,stream等等)。在同一个GPU上,可能同时存在1个或者多个CUDA Context。一般情况下,在任意时刻,GPU上只有一个活动的context。如下图所示,多个context之间按照time slice的方式轮流使用GPU。
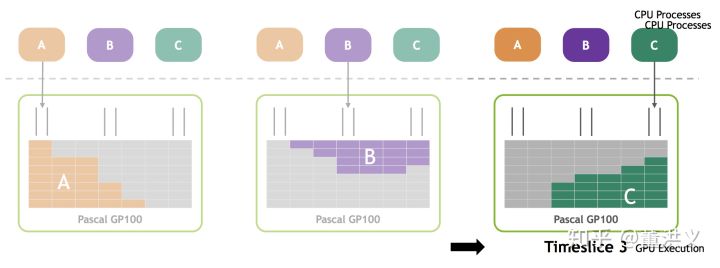
对于context的创建与管理,CUDA runtime和CUDA driver API的方式稍有不同:
-
CUDA runtime软件库通过延迟初始化(deferred initialization)来创建context,也就是lazy initialization。具体意思是在调用每一个CUDART库函数时,它会检查当前是否有context存在,若没有context,那么才自动创建。也就是说需要创建上面这些对象的时候就会创建context。runtime也可以通过调用cudaFree(0)来强制显式地初始化context。cuda runtime将context和device的概念合并了,即在一个gpu上的操作可看成在一个context下。也就是说,一个device对应一个context。
-
在驱动这一层的Driver API里,创建的context是针对一个线程的,即一个device,对应多个context,每个context对应多个线程,线程之间的context可以转移。在driver API中,每一个cpu线程必须要创建 context,或者从其他cpu线程转移context。如果没有创建context,直接调用 driver api创建上面那些对象,就会报错。
CUDA runtime API和driver API的区别:
- 我们平常安装使用的CUDA,即runtime软件库,是构建在Driver API上的另一层封装,所有的API都是以4个字母cuda开头。在编译时其cu代码可以和C/C++代码混合编译。而CUDA还有另外一个功能更强大,当然使用起来也更麻烦的API接口Driver API。Driver API将完整的CUDA功能展现给用户,功能更加强大,但是用起来较为繁琐,所有的Driver API,则都是2个字母cu开头。
CUDA Stream
CUDA Stream是指一堆异步的CUDA操作,他们按照host代码调用的顺序执行在device上,Stream维护了这些操作的顺序,并在所有预处理完成后允许这些操作进入工作队列,同时也可以对这些操作进行一些查询操作。这些操作包括host到device的数据传输,launch kernel以及其他的由host发起由device执行的动作。这些操作的执行是异步的,CUDA runtime会决定这些操作合适的执行时机。我们则可以使用相应的cuda api来保证所取得结果是在所有操作完成后获得的。同一个stream里的操作有严格的执行顺序(FIFO),不同的stream则没有此限制。
所有的cuda操作(包括kernel执行和数据传输)都显式或隐式的排队在stream中,stream也就两种类型,分别是:
- 隐式声明stream(NULL stream):默认流,无需显式创建,CUDA中默认存在。
- 显示声明stream(non-NULL stream) :在代码中创建,并对某个CUDA操作指明Stream
默认情况下,使用 NULL 流,但用户可以将操作提交给多个用户定义的流。 如果有足够的内部资源可用,来自不同流的kernel可以通过共享 GPU 的内核并发运行。
CUDA API 调用可以是同步的,也可以是异步的;对于许多调用,可以使用两者的变体。例如,cudaMemcpy 和 cudaMemcpyAsync 都在 CPU 内存和 GPU 内存的区域之间,或 GPU 内存的两个区域之间复制数据,但是 cudaMemcpyAsync 可以在复制完成之前将控制权返回给调用 CPU 任务,而 cudaMemcpy 会阻塞 CPU 任务直到内存复制完成。
当我们使用CUDA异步函数与多流(Multi Stream)时,多线程间可以实现并行进行数据传输与计算,如下图所示。不过需要注意的是, CUDA runtime API的default stream是同步串行的,且一个进程内的所有线程都在default stream下,需要显式声明default之外的Stream才可以实现多流并发。
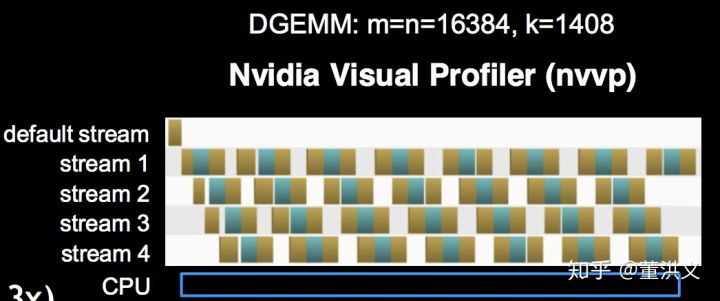
例如,一段代码使用三个stream,数据传输和kernel运算都被分配在了这几个并发的stream中,那么其运行过程如下所示。
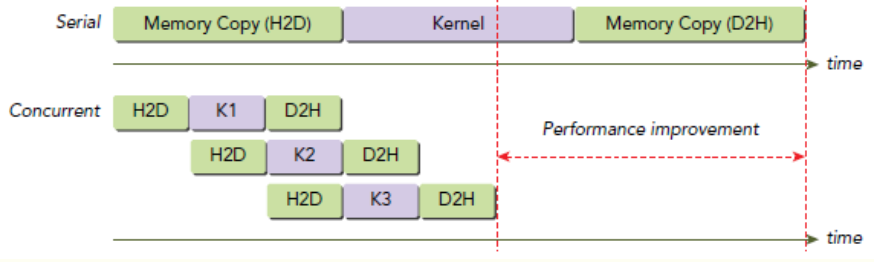
需要注意的是,上图中数据传输的操作并不是并行执行的,即使他们是在不同的stream中。
Hyper-Queue
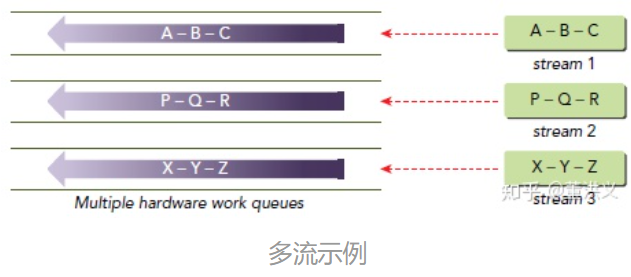
Hyper-Q是GPU从Kepler架构后,Nvidia提出的硬件特性,Kepler架构上出现了32个工作队列。允许多个CPU 线程或进程同时加载任务到一个GPU上, 实现CUDA kernels的并发执行。Hyper‐Q允许来自多个 CUDA 流、多个消息传递接口(MPI)进程,甚至是进程内多个线程的单独连接。
使用Hyper-Q有以下两种情况,分别对应了上面介绍的context与stream:
-
多流:利用CUDA异步函数以及多流的声明,既可以实现多个线程的计算与数据传输的并行,增加GPU利用率。
-
MPS(Multi-Process Service 多进程服务):多进程时使用MPS(Multi Process Service)。我们知道,每个进程默认对应一个context,而GPU在同一时刻只会运行一个context,因此进程间实际是无法并发的。MPS 作为具有CUDA 上下文的服务器进程运行,允许多个CPU进程共享同一GPU context,不同进程的kernel和memcpy操作在同一GPU上并发执行,以实现最大化 GPU利用率、减少GPU上下文的切换时间与存储空间。
kernel
官方文档: the programmer to define C++ functions, called kernels
Kernel就是在GPU上调用的函数,称为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行。
内核是使用 global 声明说明符定义的,并且使用配置语法 <<<...>>> 指定执行该Kernel的 CUDA 线程数。 每个执行Kernel的线程都被赋予一个唯一的线程 ID,该 ID 可通过内置变量在内核中访问。
作为说明,以下示例代码使用变量 threadIdx,将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
从以上示例可以看出,有N个线程在执行VecAdd(),每个线程执行一个加法。
CUDA 内核是从单个 GPU 线程的角度编写的。如上例,它使用Kernel vecAdd 为每个 GPU 线程添加一对元素,将总和存储在输出数组的相应位置。当kernel执行时,线程会锁步运行,每个线程同时对不同的数据执行相同的操作。
Kernel作为一组可以以任何顺序执行的线程块在 GPU 上运行。这些线程块,或简称为块,每个都由多个线程组成。如上例第12行所示,块数和每个块的线程数是程序员指定的,可以在内核启动时在运行时设置。 GPU 调度程序使用这些值将工作分配给 SM。block是 GPU 上的可调度实体。一个block中的所有线程总是在同一个 SM 上执行,并且非抢占式运行直到完成。当所有块中的所有线程都退出时,内核就完成了。并且CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。
grid与block
CUDA的线程组织方式。
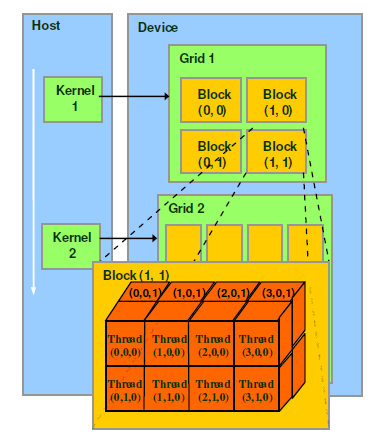
Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。
Block:一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可以通过一些共享内存共享数据,也可以通过调用 __syncthreads() 内部函数在内核中指定同步点; __syncthreads() 充当屏障,在允许任何线程继续之前,block中的所有线程必须等待该屏障。为了高效协作,共享内存应该是每个处理器核心附近的低延迟内存(很像 L1 cache),而 __syncthreads() 应该是轻量级的。
例如,以下代码将两个大小为NxN 的矩阵A和 B相加,并将结果存储到矩阵 C 中:
// 内核定义
__global__ void MatAdd( float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx .x;
int j = threadIdx .y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
... // 内核调用一块 N * N * 1 个线程int numBlocks = 1;
dim3threadsPerBlock (N, N);
MatAdd <<< numBlocks, threadsPerBlock >>> (A, B, C);
...
}
上例中,通过配置语法 <<< >>>指定kenel运行的块数以及每个块内的线程数。当一个kernel启动后,很多thread会被分配成很多block,每个block可能被分配到不同的SM中执行,并且每个块的线程数是有限制的,因为一个块的所有线程都应该驻留在同一个SM上,并且必须共享该内核的有限内存资源。在当前的 GPU 上,一个线程块最多可以包含 1024 个线程。但是,一个内核可以由多个相同的线程块执行,因此总线程数等于每个块的线程数乘以块数。
Warp
warp是调度和运行的基本单元。
一个SP可以执行一个thread,但是实际上并不是所有的thread都能够在同一时刻在不同的SP上执行。目前Nvidia把32个threads(也就是SP)组成一个warp,也就是warp是以32个线程调度的。同一个warp中的thread可以以任意顺序执行相同的指令,只是处理的数据不同。
一个SM上在任意时刻只能运行一个wrap,多个warp需要轮流进入SM,由SM的硬件warp scheduler负责调度。当一个warp空闲时(可能是存取global memory 操作,需要等待),SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以新调度的warp的状态已经存储在SM中了。一个GPU上resident thread最多只有 SM*warp个。
内存结构
CUDA 线程在执行期间可以访问来自多个内存空间的数据,如下图所示。每个线程都有私有的本地内存。每个线程块都具有对该块的所有线程可见的共享内存,并且与该块具有相同的生命周期。所有线程都可以访问相同的全局内存。
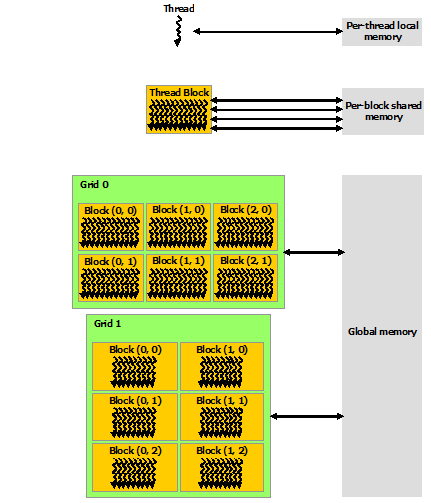
还有两个额外的只读内存空间可供所有线程访问:常量和纹理内存空间。全局、常量和纹理内存空间针对不同的内存使用情况进行了优化。纹理内存还为某些特定数据格式提供不同的寻址模式以及数据过滤。全局、常量和纹理内存空间在同一应用程序的内核启动中是持久的。
texture memory( 纹理内存)是一种只读存储器,由GPU用于纹理渲染的的图形专用单元发展而来,因此也提供了一些特殊功能。实质上是全局内存的一个特殊形态,全局内存被绑定为纹理内存,对其的读(写)操作将通过专门的texture cache(纹理缓存)进行,其实称为纹理缓存更加贴切。
总结
经过上面的介绍,我们已经对CUDA的一些基础概念有所了解,现在我们总结一下它们之间的关系。
当要执行程序中的第一个kernel时,会先进行CUDA initialization,创建一个CUDA context,用于管理由Driver层分配的所有资源(例如所有的缓冲区,kernel对象,纹理对象,stream等等)的生命周期。通常情况下,一个context对应一个CPU进程,并且任意时刻GPU上只能有一个活动的context,但是采用MPS技术,多个CPU进程可以共享一个context,不同进程的kernel和memcpy操作在同一GPU上并发执行。
Kernel以及数据传输等操作都是CUDA操作,而这些操作的执行顺序是由Stream进行维护的。一个GPU上可以有多个Stream,同一个stream里的操作是串行的,不同的stream则没有此限制。CUDA开始执行时,会有一个默认的stream,当代码中没有明确指明操作的stream时,就放在默认的stream中,这样无关的操作也无法并行,所以通过在代码中创建不同的stream,并对操作指明具体的stream,就可以实现多个操作的并行。这里的并行,可以说真正的并行,但也有可能两个操作因为数据依赖或者硬件资源冲突,而等待的现象。
上面所说的内容,涉及到Kernel、内存拷贝等操作,接下来我们重点说一下一个Kernel函数是怎么执行的。
一个kernel被分解成许多个thread,而thread的数目在代码中显式指明,这些thread组成一个grid,grid里又有数个block,每个block是一个thread群组,并且每个block中的thread数量是在代码中显式指明的,在同一个block中的thread可以通过共享内存(shared memory)来通信、同步,而不同block之间的thread是无法通信的。
CUDA的设备在实际执行过程中,会以block为单位。把一个个block分配给SM进行运算,并且一个block中的所有thread都应该在同一个SM上执行,而block中的thread又会以warp为单位,对thread进行分组计算。目前CUDA的warp大小都是32,也就是说32个thread会被组成一个warp来一起执行。同一个warp中的thread执行的指令是相同的,只是处理的数据不同。
基本上warp 分组的动作是由SM 自动进行的,会以连续的方式来做分组。比如说如果有一个block 里有128 个thread 的话,就会被分成四组warp,第0-31 个thread 会是warp 1、32-63 是warp 2、64-95是warp 3、96-127 是warp 4。而如果block 里面的thread 数量不是32 的倍数,那它会把剩下的thread独立成一个warp;比如说thread 数目是66 的话,就会有三个warp:0-31、32-63、64-65 。由于最后一个warp 里只剩下两个thread,所以其实在计算时,就相当于浪费了30 个thread 的计算能力,所以在设定block 中thread 数量时一定要注意。
一个SM 会根据其内部SP数目分配warp,就像上面介绍SM时的例子里,就有两个wrap,但是SM 不见得会一次把这个warp 的所有指令都执行完。当遇到正在执行的warp 需要等待的时候(例如存取global memory 就会要等好一段时间),就切换到别的warp来继续做运算(wrap的切换是几乎没有代价的,因为另一个wrap所需的各种东西都已经在SM中),借此避免为了等待而浪费时间。所以理论上效率最好的状况,就是在SM 中有够多的warp 可以切换,让在执行的时候,不会有「所有warp 都要等待」的情形发生;因为当所有的warp 都要等待时,就会变成SM 无事可做的状况了。
实际上,warp 也是CUDA 中,每一个SM 执行的最小单位,如果GPU 有16 组SM 的话,也就代表他真正在执行的thread 数目会是32*16 个。不过通过warp 的切换可以隐藏thread 的延迟、等待,来达到大量平行化的目的,所以会用所谓的active thread 这个名词来代表一个SM 里同时可以处理的thread 数目。而在block 的方面,一个SM 可以处理多个线程块block,当其中有block 的所有thread 都处理完后,他就会再去找其他还没处理的block 来处理。假设有16 个SM、64 个block、每个SM 可以同时处理三个block 的话,那一开始执行时,device 就会同时处理48 个block;而剩下的16 个block 则会等SM 有处理完block 后,再进到SM 中处理,直到所有block 都处理结束 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号