


PHP中的正则表达式
我们先看一个正则表达示的样子:
/^a-z@([a-z0-9][-_]?[a-z0-9]+)+[.][a-z]{2,3}([.][a-z]{2})?$/i
呵呵,看着就觉得揪心。提前声明,别被吓着,学习一下后你会发现没那么困难。
正则表达示我们其实之前经常看到,它主要用在以下一些地方:
- 匹配邮箱、手机号码、验证码
- 替换敏感的关键词。例如:涉及政治和骂人的话
- 文章采集。
- 早期的表情替换技术,ubb文件编码、markdown编辑器替换等
- 以后自己写模板引擎也需要用到正则表达示
- 其他....
PHP正则表达式的定界符
定界符,就是定一个边界,边界以内的就是正则表达式。
PHP的正则表达示定界符的规定如下:
定界符,不能用a-zA-Z0-9\ 其他的都可以用。必须成对出现,有开始就有结束。
我们来例几个例子:
| 例子 | 说明 |
|---|---|
| /中间写正则/ | 正确 |
| $中间写正则$ | 正确 |
| %中间写正则% | 正确 |
| ^中间写正则^ | 正确 |
| @中间写正则@ | 正确 |
| (中间写正则) | 错误 |
| A中间写正则A | 错误 |
注:\ 是转义字符,如果在以后正则表达示里面需要匹配/,如下图:
/ / /
这个时候真要匹配/ 的时候,需要把定界符里面的/ 用转义字符转义一下,写成下面的例子:
/ \/ /
如果你觉得麻烦,遇到这种需要转义的字符的时候可以把两个正斜线(/ /)定界,改为其他的定界符(# #)。
正则表达式中的原子
原子是正则表达示里面的最小单位,原子说白了就是需要匹配的内容。一个成立的正则表达示当中必须最少要有一个原子。
说明:我们见到的空格、回车、换行、0-9、A-Za-z、中文、标点符号、特殊符号全为原子。
在做原子的实例前我们先来讲解一个函数,preg_match:
int preg_match ( string $正则 , string $字符串 [, array &$结果] )
功能:根据$正则变量,匹配$字符串变量。如果存在则返回匹配的个数,把匹配到的结果放到$结果变量里。如果没有匹配到结果返回0。
注:上面是preg_match常用的主要几个参数。我在上面将另外几个参数没有列出来。因为,另外两个参数太不常用了。
<?php $zz = '/wq/'; $string = 'ssssswqaaaaaa'; if(preg_match($zz, $string, $matches)){ echo '匹配到了,结果为:'; var_dump($matches); }else{ echo '没有匹配到'; } ?>
运行结果:
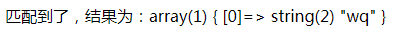
特殊标识的原子
| 原子 | 说明 |
|---|---|
| \d | 匹配一个0-9 |
| \D | 除了0-9以外的所有字符 |
| \w | a-zA-Z0-9_ |
| \W | 除了0-9A-Za-z_以外的所有字符 |
| \s | 匹配所有空白字符\n \t \r 空格 |
| \S | 匹配所有非空白字符 |
| [ ] | 指定范围的原子 |
这个个需要记住,最好达到默写级别。记忆的时候成对记忆,\d是匹配一个0-9,那么\D 就是除了0-9以外的所有字符。
| 原子 | 等价式 |
|---|---|
| \w | [a-zA-Z0-9_] |
| \W | [^a-zA-Z0-9_] |
| \d | [0-9] |
| \D | [^0-9] |
| \s | [ \t\n\f\r] |
| \S | [^ \t\n\f\r] |
PHP正则表达式中的元字符
抛出问题: \d 代表匹配一个字符。而我现在想要匹配十个八个,任意多个数字肿么办?
这个时候我们就要用到元字符。在使用原子的时候,发现只能够匹配一个字符,可是要匹配多个字符就出现了问题。
这个时候,我们需要借助元字符来帮我们修饰原子,实现更多的功能。
| 元字符 | 功能说明 |
|---|---|
| * | 是代表匹配前面的一个原子,匹配0次或者任意多次前面的字符。 |
| + | 匹配一次或多次前面的一个字符 |
| ? | 前面的字符可有可无【可选】 有或没有 |
| . | 更标准一些应该把点算作原子。匹配除了\n以外的所有字符 |
 |
或者。注:它的优先级最低了。 |
| ^ | 必须要以抑扬符之后的字符串开始 |
| $ | 必须要以$之前的字符结尾 |
| \b | 词边界 |
| \B | 非边界 |
| {m} | 有且只能出现m次 |
| {n,m} | 可以出现n到m次 |
| {m,} | 至少m次,最大次数不限制 |
| () | 改变优先级或者将某个字符串视为一个整体,匹配到的数据取出来也可以使用它 |
正则表达式中的模式修正符
我们通过元字符和原子完成了正则表达示的入门。有一些特殊情况我们依然需要来处理。
如果abc在第二行的开始处如何匹配?
我不希望正则表达示特别贪婪的匹配全部,只匹配一部份怎么办?
这个时候,我们就需要用到下面的这些模式匹配来增强正则的功能。
常用的模式匹配符有:
| 模式匹配符 | 功能 |
|---|---|
| i | 模式中的字符将同时匹配大小写字母. |
| m | 字符串视为多行 |
| s | 将字符串视为单行,换行符作为普通字符. |
| x | 将模式中的空白忽略. |
| A | 强制仅从目标字符串的开头开始匹配. |
| D | 模式中的美元元字符仅匹配目标字符串的结尾. |
| U | 匹配最近的字符串. |
模式匹配符的用法如下:
/ 正则表达示/模式匹配符
模式匹配符是放在这句话的最后的。例如:
/\w+/s
i 不区分大小写:
<?php //在后面加上了一个i $pattern = '/ABC/i'; $string = '8988abc12313'; $string1 = '11111ABC2222'; if(preg_match($pattern, $string, $matches)){ echo '匹配到了,结果为:'; var_dump($matches); }else{ echo '没有匹配到'; } ?>
运行结果:$string和$string1全都匹配成功了。因此,在后面加上了i之后,能够不共分匹配内容的大小写。
m视为多行
正则在匹配的时候,要匹配的目标字符串我们通常视为一行。
“行起始”元字符(^)仅仅匹配字符串的起始,“行结束”元字符($)仅仅匹配字符串的结束。
当设定了此修正符,“行起始”和“行结束”除了匹配整个字符串开头和结束外,还分别匹配其中的换行符的之后和之前。
注意:如果要匹配的字符串中没有“\n”字符或者模式中没有 ^ 或 $,则设定此修正符没有任何效果。
S视为一行
如果设定了此修正符,模式中的圆点元字符(.)匹配所有的字符,包括换行符。
x 忽略空白字符
- 如果设定了此修正符,模式中的空白字符除了被转义的或在字符类中的以外完全被忽略。
- 未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。
e 将匹配项找出来,进行替换
e模式也叫逆向引用。主要的功能是将正则表达式括号里的内容取出来,放到替换项里面替换原字符串。使用这个模式匹配符前必须要使用到preg_replace()。
mixed preg_replace ( mixed $正则匹配项 , mixed $替换项 , mixed $查找字符串)
<?php $string = "{April 15, 2003}"; //'w'匹配字母,数字和下划线,'d'匹配0-99数字,'+'元字符规定其前导字符必须在目标对象中连续出现一次或多次 $pattern = "/{(\w+) (\d+), (\d+)}/i"; $replacement = "\$2"; //字符串被替换为与第 n 个被捕获的括号内的子模式所匹配的文本 echo preg_replace($pattern, $replacement, $string); //结果为15 ?>
结论:
上例中\$2 指向的是正则表达示的第一个(\d+)。相当于把15又取出来了
替换的时候,我写上\$2。将匹配项取出来,用来再次替换匹配的结果。
U 贪婪模式控制
正则表达式默认是贪婪的,也就是尽可能的最大限度匹配。
A 从目标字符串的开头开始匹配
此模式类似于元字符中的^(抑扬符)效果。
D 结束$符后不准有回车
如果设定了此修正符,模式中的美元元字符仅匹配目标字符串的结尾。没有此选项时,如果最后一个字符是换行符的话,美元符号也会匹配此字符之前。
常用正则函数
我们常用的正则函数有:
| 函数名 | 功能 |
|---|---|
| preg_filter | 执行一个正则表达式搜索和替换 |
| preg_grep | 返回匹配模式的数组条目 |
| preg_match | 执行一个正则表达式匹配 |
| preg_match_all | 执行一个全局正则表达式匹配 |
| preg_replace_callback_array | 传入数组,执行一个正则表达式搜索和替换使用回调 |
| preg_replace_callback | 执行一个正则表达式搜索并且使用一个回调进行替换 |
| preg_replace | 执行一个正则表达式的搜索和替换 |
| preg_split | 通过一个正则表达式分隔字符串 |
大家针对这这些函数,对着手册用一下。有问题或遇到问题可以来我们的官网提问。
正则关于面试常遇到的问题
面试中经常考到的几个正则达达示是:
- 匹配邮箱
- 匹配手机号
- 匹配一个网址
- 用正则匹配某个格式,取出某个例
- 写一个采集器
其他....
