


用何以为家500条最热门的评价告诉你,它好不好看
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
import sqlite3 with sqlite3.connect('gzccnews.sqlite') as db: newsdf.to_sql('gzccnews',con=db) !pip install PyMySQL !pip install sqlalchemy with sqlite3.connect('gzccnews.sqlite') as db: df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db) df2
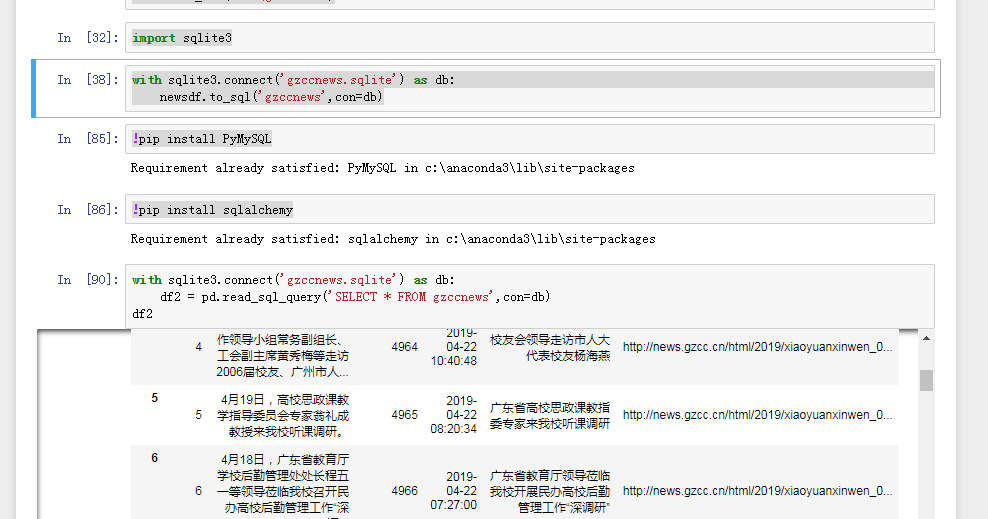
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
import pymysql from sqlalchemy import create_engine coninfo = "mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8" engine = create_engine(coninfo,encoding="utf-8") newsdf.to_sql(name ='gzccnews',con = engine,if_exists = 'append',index = False,index_label='id') newsdf.to_sql(name='gzccnews',con=coninfo,if_exists='append',index= False) conn=pymysql.connect(host='localhost',port=3306,user='root',passwd='',db='gzccnews',charset='utf8')
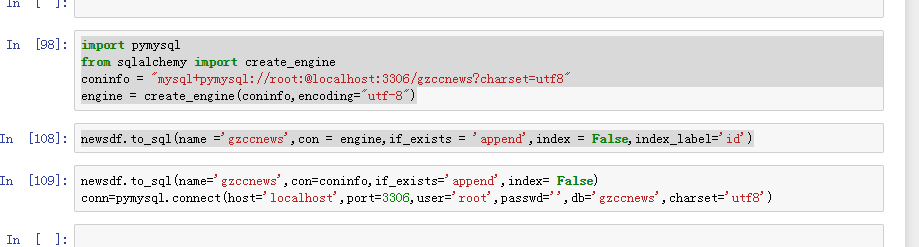
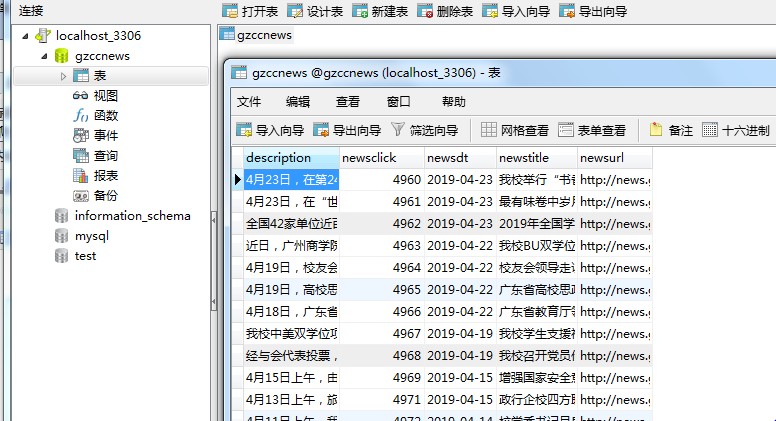
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
1.选择主题:豆瓣电影网,何以为家
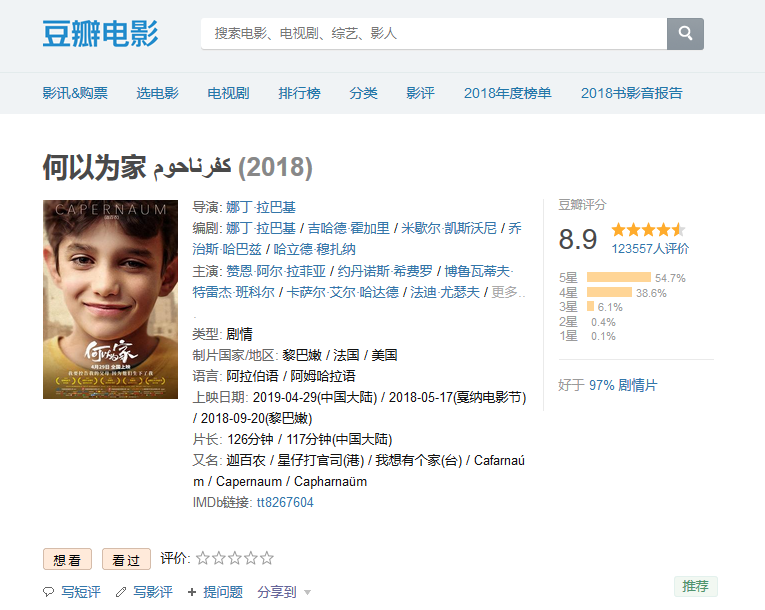
2.爬取对象:何以为家的短评
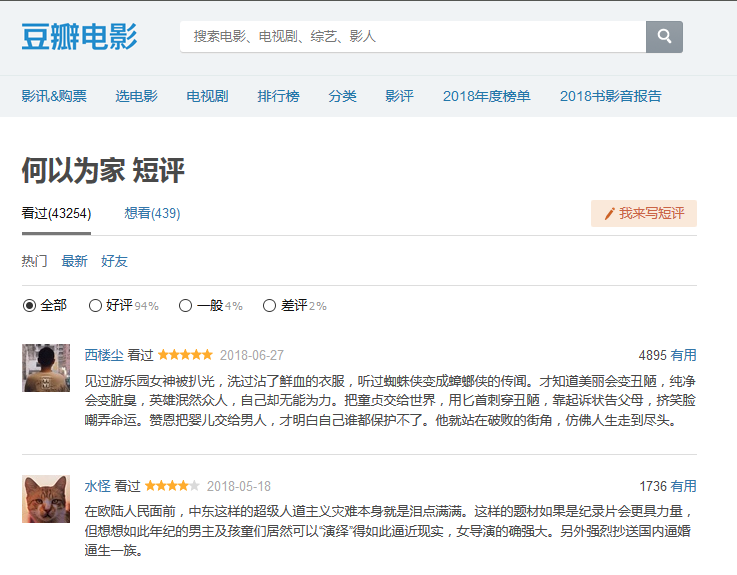
注:爬取网址规律:每一页的网址都只有改变一个地方 start = (开始为0,每加一页数值加20)

爬取相应内容:

import pandas
import requests
from bs4 import BeautifulSoup
import time
import random
import re
def getHtml(url):
cookies = {'PHPSESSID':'Cookie: bid=7iHsqC-UoSo; ap_v=0,6.0; __utma=30149280.1922890802.1557152542.1557152542.1557152542.1;<br> __utmc=30149280; __utmz=30149280.1557152542.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1923787146.1557152542.1557152542.1557152542.1;<br> __utmb=223695111.0.10.1557152542; __utmc=223695111; __utmz=223695111.1557152542.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none);<br> _pk_ses.100001.4cf6=*; push_noty_num=0; push_doumail_num=0; __utmt=1; __utmv=30149280.19600; ct=y; ll="118281";<br> __utmb=30149280.12.9.1557154640902; __yadk_uid=6FEHGUf1WakFoINiOARNsLcmmbwf3fRJ; <br>_vwo_uuid_v2=DE694EB251BD96736CA7C8B8D85C2E9A7|9505affee4012ecfc57719004e3e5789;<br> _pk_id.100001.4cf6=1f5148bca7bc0b13.1557152543.1.1557155093.1557152543.; dbcl2="196009385:lRmza0u0iAA"' }
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = requests.get(url,headers=headers,cookies=cookies,verify=False);
req.encoding='utf8'
soup = BeautifulSoup(req.text,"html.parser")
return soup;
def alist(url):
comment = []
for ping in soup.select('.comment-item'):
pinglundict={}
user = ping.select('.comment-info')[0]('a')[0].text
userUrl = ping.select('.comment-info')[0]('a')[0]['href']
look = ping.select('.comment-info')[0]('span')[0].text
score = ping.select('.comment-info')[0]('span')[1]['title']
time = ping.select('.comment-time')[0]['title']
pNum = ping.select('.votes')[0].text
pingjia = ping.select('.short')[0].text
pinglundict['user'] = user
pinglundict['userUrl'] = userUrl
pinglundict['look'] = look
pinglundict['score'] = score
pinglundict['time'] = time
pinglundict['pNum'] = pNum
pinglundict['pingjia'] = pingjia
comment.append(pinglundict)
return comment
url = 'https://movie.douban.com/subject/30170448/comments?start={}&limit=20&sort=new_score&status=P'
comment=[]
for i in range(25):
soup = getHtml(url.format(i * 20))
comment.extend(alist(soup))
time.sleep(random.random() * 3)
print(len(comment))
print('--------------------------总共爬取 ', len(comment), ' 条-------------------------')
print(comment)
pinglundf = pandas.DataFrame(comment)
pinglundf.to_csv(r'D:\ZUOYE\pinglun.csv',encoding='utf_8_sig')
爬取到的评论信息:
这次我们爬取到的信息有:用户名、观看情况、评分情况、评论、评论时间和赞同次数
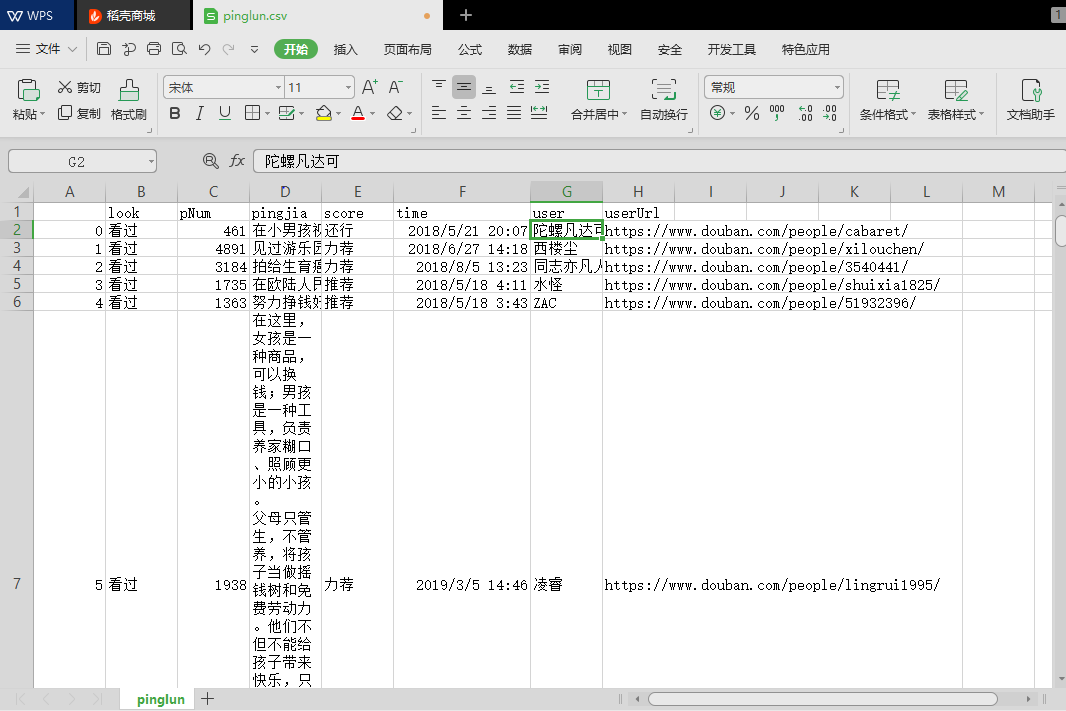
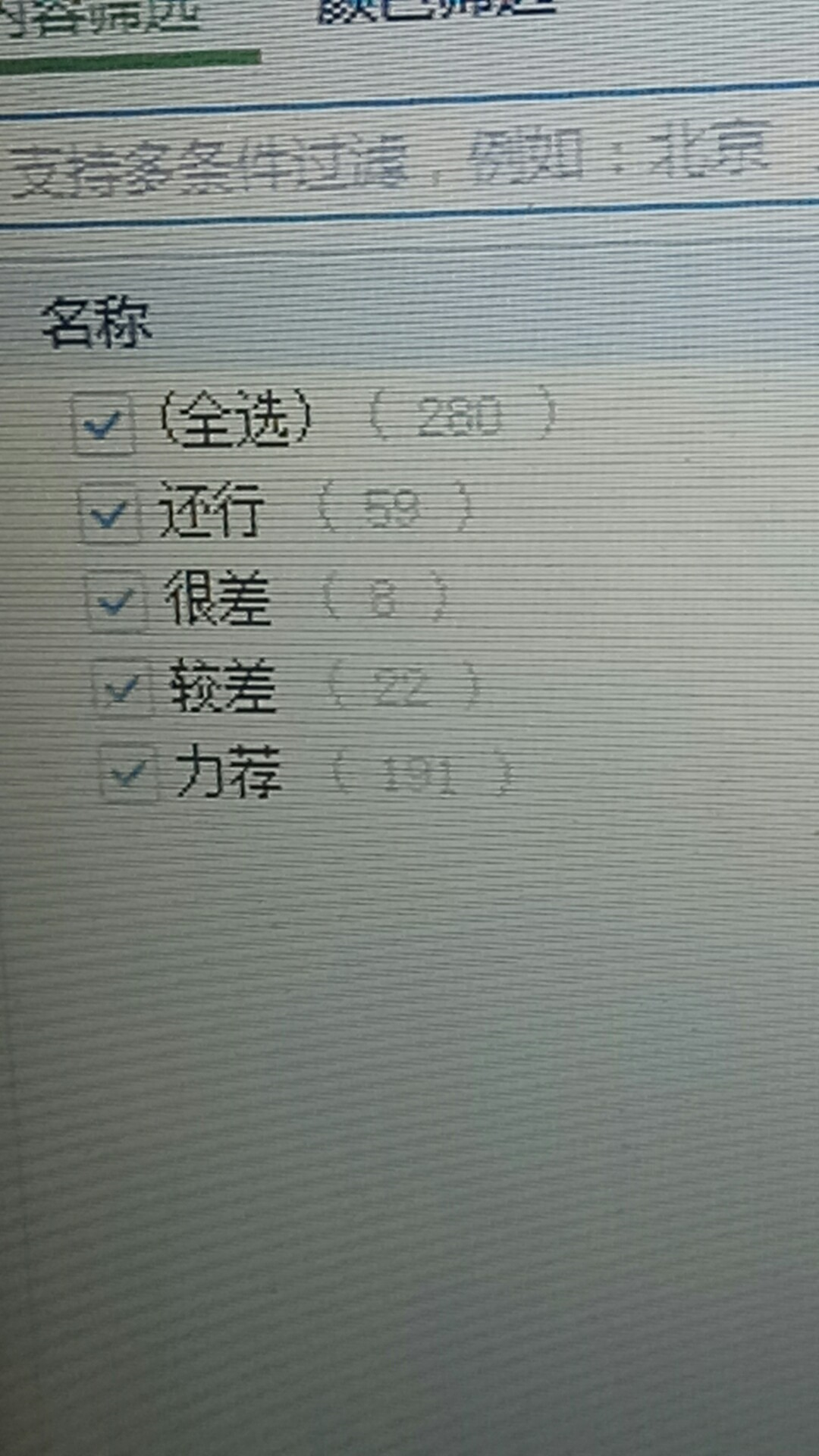
电影评分情况统计:(除去部分出现日期的情况)
评论整理:将爬取到的评论信息进行处理,最后经过词频统计。
# coding=utf-8 # 导入jieba模块,用于中文分词 import jieba # 获取所有评论 import pandas as pd # 读取小说 f = open(r'ping.txt', 'r', encoding='utf8') text = f.read() f.close() print(text) ch="《》\n:,,。、-!?0123456789" for c in ch: text = text.replace(c,'') print(text) newtext = jieba.lcut(text) te = {} for w in newtext: if len(w) == 1: continue else: te[w] = te.get(w, 0) + 1 tesort = list(te.items()) tesort.sort(key=lambda x: x[1], reverse=True) # 输出次数前TOP20的词语 for i in range(0, 20): print(tesort[i]) pd.DataFrame(tesort).to_csv('ping.csv', encoding='utf-8')
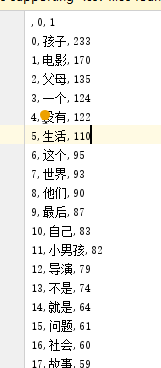

总结:
在本次爬取到的影片评论信息何以为家中我们可以看出70%左右的观众对这部影片还是持有着力荐的态度。认为该影片值得一看。
而在用户评论中出现次数最多的“孩子”,“电影”,“父母”,“一个”,“没有”,“生活”,“这个”,“世界”,“他们”,“最后”,“自己”,“小男孩”,“导演”,“不是”,“就是”,“问题”,“社会”,“故事”,“真实”,“还是”,“希望”等词可以看出本片大概的主题内容,应该说的是一个失去了父母的小男孩在社会上见到了很多社会上的人感觉到了希望,最终明白自己就是父母留在这个世界最后的礼物。
可以说,何以为家,还是一部很不错的电影。
这是


