
合作——独木不成林
- Github项目地址:https://github.com/Lin-000/WordCount.git
- 结对伙伴的作业地址:https://www.cnblogs.com/lazy-bear/p/11650424.html
- 作业链接: https://www.cnblogs.com/harry240/p/11524113.html
代码规范
- 基本命名规范:
=》在命名时需要使用有意义的名称
=》优先使用英文,如果英文没有合适的单词,可以使用拼音,如城市名称等
=》禁止使用中文命名
=》命名不能使用缩写,如必须写成 person,不能写成 per
=》变量采用驼峰命名法
=》第一个单词以小写字母开始;从第二个单词开始以后的每个单词的首字母都采用大写字母,例如:myFirstName、myLastName。 - 布局规范:
=》使用 Tab 缩进,缩进大小为4。
=》【Visual Studio 2017 中设置方法:菜单工具-选项-文本编辑器-C#-制表符,把制表符大小和缩进大小设置成4,选中“保留制表符”,点确定】
=》左右花括号必须独占一行,括号内容为空时可在一行
=》【Visual Studio 2017 中设置方法:菜单工具-选项-文本编辑器-C#-代码样式-格式设置-新行】 - 注释:
=》对于复杂难理解的代码,要加上详细的注释,便于理解代码以及后续的代码复审。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1200 | 1450 |
| Estimate | 估计这个任务需要多长时间 | 1200 | 1450 |
| Development | 开发阶段 (以下从需求分析到具体编码过程) | 120+60*4+360=720 | 150+80*2+70+80+400=860 |
| Analysis | 需求分析(包括新技术学习) | 120 | 150 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审(和同学审核设计文档) | 60 | 80 |
| Coding Standard | 代码规范(为目前的开发制定规范) | 60 | 70 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 360 | 400 |
| Code Review | 代码复审 | 100 | 110 |
| Test | 测试(自我测试、修改代码、代码提交) | 130 | 140 |
| Reporting | 报告 | 100 | 120 |
| Test Report | 测试报告 | 60 | 90 |
| Size Measurement | 计算工作量 | 40 | 60 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 50 | 70 |
| total | 总计 | 1200 | 1450 |
代码思路分析
- 统计字符串中所有字符总数函数:用CharactersNum()函数,把文档中所有的字符串作为参数传入CharactersNum()函数,依次匹配字符串中的每个字符,对\s进行匹配,可利用 Matches()方法来逐个记录,最后返回字符串中所有字符总数
- 统计字符串中所有单词总数函数:需要利用集合的思想,在集合中保存满足条件的单词,即至少由4个字母组成的单词,利用正则,匹配[A-Za-z]{4}[A-Za-z0-9]*(\W|$,最后返回满足这些条件的集合,
- 统计字符串中文本行数函数:把文本内容即字符串作为函数的参数传入,对\r进行匹配,即换行符,利用正则的思想,Matches()中传入 \r,依次记录文本中 \r 的数量
- 统计一个集合中单词出现的频率函数:在统计完字符串中所有单词之后,再依次遍历集合中每个单词,把单词保存在集合中,匹配的过程中,如果出现相同 的单词,就把单词对应的数量+1,没有相同的,就先把单词放入到集合中,最后返回记录的单词以及该单词对应出现的次数的集合
- 找出单词字典中出现频率最高的n个单词函数:在完成统计一个集合中单词出现的功能之后,把返回值作为参数传入到该函数中,利用下标依次遍历,选择出符合条件的n个单词,并同时输出它们出现的次数
- 将字符串写入文件函数:这部分是参考CSDN上面的,利用FileStream()来new一个对象,指定输入的文件,利用StreamWriter()所创建的对象,来把运行结果写入文件
- 输出指定长度的单词词组(这里我们输出的词组中所有的单词的均满足要求:至少以4个英文字母开头):定义一个返回类型为字典的函数,接受已经筛选单个单词长度的返回结果List
集合和指定长度(WordNum)的参数,然后开始遍历接受的List 集合,把每WordNum个词组存到一个字典中。在把词组存入到字典之前,首先判断字典中是否存在该词组,若已经存在,则只把该词组的频率(该词组对应的值)+1,否则把该词组添加到字典中(同时,设定该词组的频率设为1)。 - 声明:初次拿到题目时,就考虑到应该用正则表达式来匹配,然后去找了C#关于正则的相关API,知道了使用方式,代码中用到了很多正则知识。对于在命令行运行程序,并通过命令行输入字符串作为参数传递给 program.cs 这个问题,百度搜索。
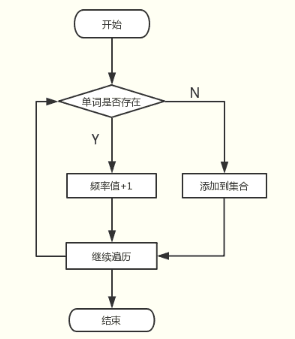
流程图
- 输出频率最高的num个单词:num为要输出的单词个数,dic.Count为要查找的字典的元素个数,x为临时变量

关键代码
- 根据要求,我们将统计字符串中所有单词的总数( WordsNum.cs )、找出单词字典中出现频率最高的n个单词( MaxFrequence.cs )、统计字符串中所有字符总数 ( CharactersNum.cs ),这三个函数独立封装了起来,其中 program.cs 为主函数, programTests.cs 为单元测试函数。

- 统计字符串中所有单词的总数的函数 WordsNum.cs
public class GetWordsNum
{
public static List<string> WordsNum(string text)
{
List<string> words = new List<string>();
MatchCollection matches = Regex.Matches(text, @"[A-Za-z]{4}[A-Za-z0-9]*(\W|$)"); // 利用正则实现匹配
foreach (Match match in matches)
{
words.Add(match.Value);
}
return words; // 返回一个储存了所有单词的集合(包括重复的单词)
}
}
- 找出单词字典中出现频率最高的n个单词 MaxFrequence.cs
public class GetMaxFrequence
{
/* 找出单词字典中出现频率最高的n个单词 */
public static Dictionary<string, int> MaxFrequence(Dictionary<string, int> dic, int n)
{
// dic储存单词及出现频率的字典 n为需要输出单词个数
Dictionary<string, int> d = new Dictionary<string, int>();
int x = 0;
// 判断需要的单词个数是否超出总单词个数
if (n <= dic.Count)
{
x = n;
}
else
{
x = dic.Count;
}
while (d.Count < x)
{
List<string> l = new List<string>(); // 多个单词有相同频率时储存至这个临时集合中按字典顺序排序
int maxValue = dic.Values.Max(); ; // 单词的最高频率
foreach (string s in dic.Keys)
{
if (dic[s] == maxValue) // 获取拥有最高频率的单词
{
l.Add(s); // 添加到临时集合中
}
}
foreach (string s in l) // 将单词从原来的字典中删除 准备下一次查找
{
dic.Remove(s);
}
l.Sort(string.CompareOrdinal);
foreach (string s in l)
{
d.Add(s, maxValue);
if (d.Count >= x) // 获取到10个单词后就退出
break;
}
}
return d;
}
}
- 统计一个集合中单词出现的频率的函数
public static Dictionary<string, int> WordFrequence ( List<string> wordList )
{
Dictionary<string, int> dictionary = new Dictionary<string, int>();
foreach (string word in wordList) // 遍历集合中每个单词
{
int value;
if (dictionary.TryGetValue(word, out value))
{
// 存在,则+1
dictionary[word] += 1;
}
else
{
// 不存在,则添加到集合中
dictionary.Add(word, 1);
}
}
return dictionary;
}
- 统计满足 -m 功能的词组频率函数 CountPhrase.cs
public class CountPhrase
{
// wordList 为已经筛选后的四个字母以上的单词集合,wordGroupNum为长度
public static Dictionary<string, int> WordsGroups(List<string> wordList, int wordGroupNum)
{
// 创建字典用于保存 -m 功能的字符数组
Dictionary<string, int> wordsGroup = new Dictionary<string, int>();
int i;
int j = 0;
// 循环判断 -m 后输入的数字,截取对应长度的词组
for (i = 0; i <= wordList.Count - wordGroupNum; i++)
{
// str 用来临时存储当前单词个数为 wordGroupNum 的词组
string str = "";
for (j = i; j < wordGroupNum + i; j++)
{
str += wordList[j];
}
// 对词组频率进行统计
if (wordsGroup.ContainsKey(str))
{
// 如果词组已经存在,则频率 +1
wordsGroup[str] += 1;
}
else
{
// 否则加入新的字典中
wordsGroup.Add(str, 1);
}
}
return wordsGroup;
}
}
- 统计字符串中所有字符总数的函数 CharactersNum.cs
public static int CharactersNum(string text) // text为要统计的字符串
{
int num = 0;
num = Regex.Matches(text, @"[\S| ]").Count;
return num; // 返回字符总个数
}
代码复审
-
部分函数功能内部的语句有的可以简化,然后我针对部分函数中的语句做了修改,在代码简洁的同时保证了功能的正确实现。(下面的性能测试图,是在最开始的代码基础上,改进之后做的分析。由于之前第一次完成性能测试时,没有及时截图,便对代码做了重新的优化,所以性能分析是最终优化后的)
-
我们起初计划的是各自负责几个功能函数,最后把函数引入合并,在需要的地方调用函数。初步实现各自的功能函数之后,就开始把代码合并,复审的过程中,出现的大多问题是和命名规范相关的,这些问题导致合并的过程会被绕晕,很慢,然后我就重新统一命令规范,愉快的完成了代码合并,成功的实现了功能。
-
当我把代码发给我的同伴时,检测在不同的环境下程序是否能够侦正常运行,当她在命令行输入之后,出现了以下问题

-
错误分析:提示显示 input.txt 文件和 output.txt 文件的路径有问题
-
解决方法:原因是输入输出文件的路径不对,应该指定正确的路径,然后她按照我的文件路径新建对应的 input.txt 和 output .txt 文件,然后就可以正常运行啦。(路径是一个不能忽视的很重的小细节!!!)
代码实现过程(测试、分析)
- 测试计算字符串中字符总数函数
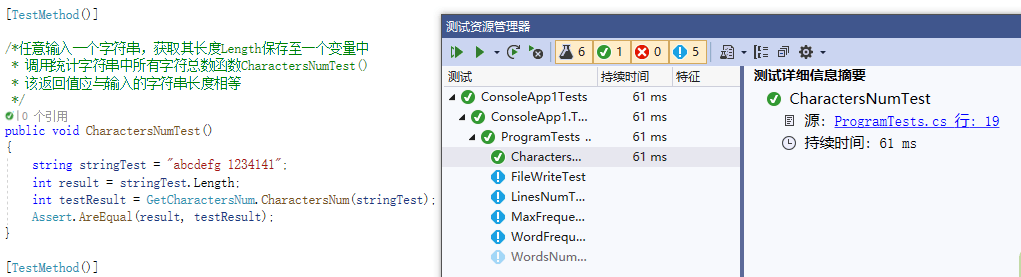
- 测试计算字符串中行数总数函数(主要针对 \r )

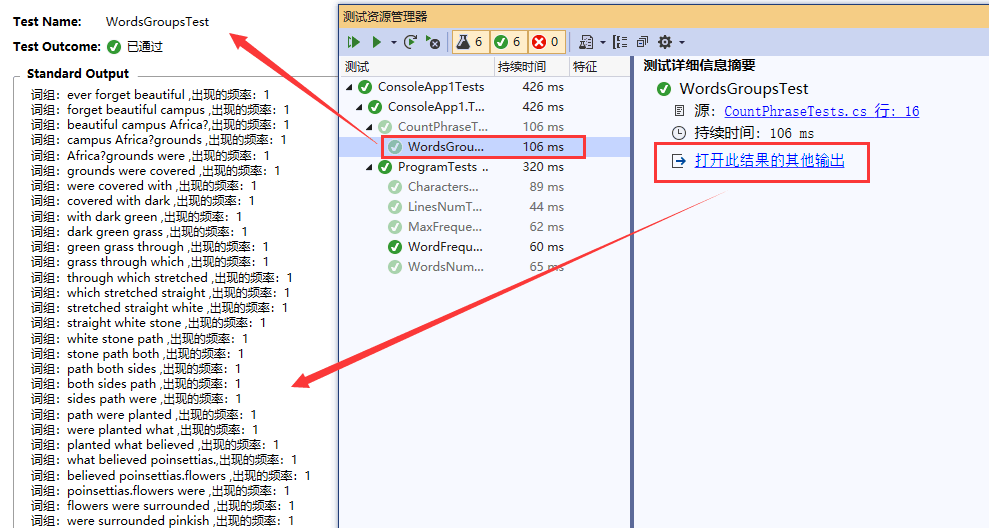
- 测试计算字符串中、出现频率最高的10个单词总数函数

- 可点击【此结果的其他输出】 ,来查看测试结果,点击如下图:

- 测试统计指定长度的词组的频率函数
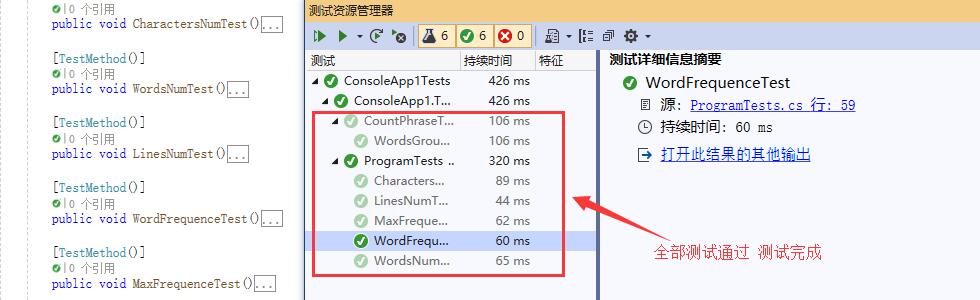
- 测试完成
- 初步性能分析图
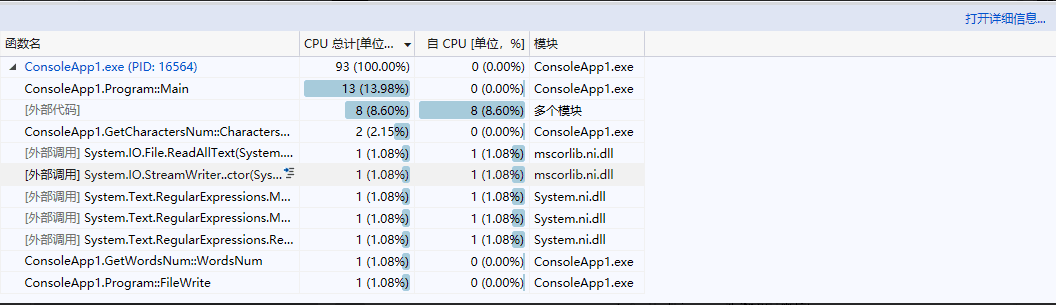
- 详细性能分析

- 创建了多个测试用例
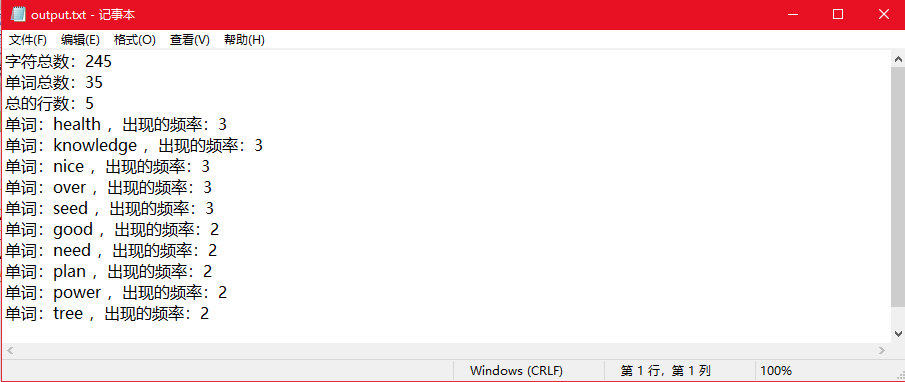
- 运行效果
=》待检测的文件 input.txt:

=》命令行输入方式以及对应结果

=》命令行输入方式以及对应结果

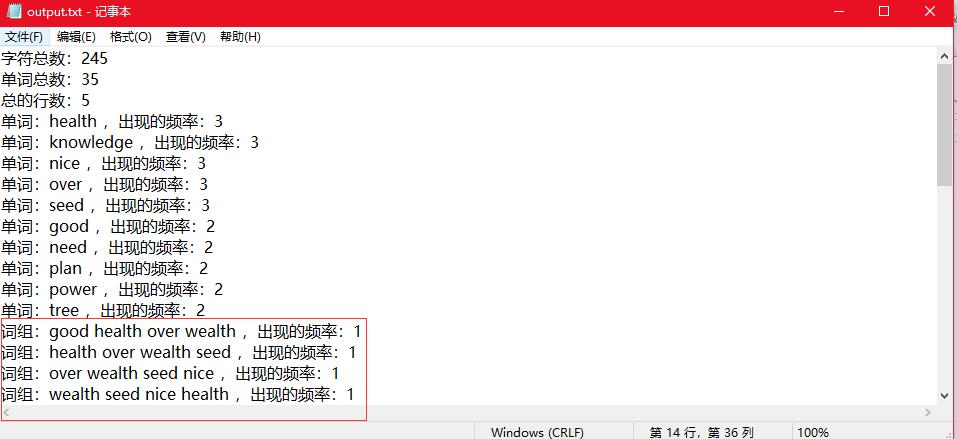
=》命令行输入方式以及对应结果


收获 感受
- 我负责的是基本功能中的统计某个单词的出现频率(只输出出现字数最高的10个)、接口封装、以及新增功能中的 -i 参数设定读入的文件路径和-n参数设定输出的单词数量和 -o 参数设定生成文件的存储路径,这次作业相对内容比较多,做的时间也很长,涉及到正则、封装、接口等知识,以及合并代码,PSP表格计划时间,做性能分析等过程,如果一个人完成的话,可能会延时比较长,进度会很慢,但这次两人合作结对编程,就进行的很顺利,我们合理的分配了任务,然后各自根据自己的空闲时间来安排进度,及时的沟通和交流,总体感觉很棒,在交流的同时,不仅解决了测试、以及封装等问题,也让我对Visual Studio 2017的使用更加熟悉了,知道了设置布局规范的快捷方式,创建单元测试的方式,以及把某个类独立出来,然后与主类建立一定的联系,再调用的方式,让我感受到了合作的力量。
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号