


基于superagent 与 cheerio 的node简单爬虫
最近重新玩起了node,便总结下基本的东西,在本文中通过node的superagent与cheerio来抓取分析网页的数据。
目的
superagent 抓取网页
cheerio 分析网页
准备
Node(我的6.0)
三个依赖, express(4X),superagent 和 cheerio。
文档参考
superagent(http://visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。
cheerio(https://github.com/cheeriojs/cheerio )为服务器特别定制的,快速、灵活、实施的jQuery. 用来从网页中以 css selector 取数据,使用方式跟 jquery 一样。
代码
那么我将抓取自己博客的数据。(有兴趣的朋友可以锦上添花一下,用正则筛选阅读数不少于400的文章.)
1 var express = require('express'); 2 var superagent = require('superagent'); 3 var cheerio = require('cheerio'); 4 5 var app = express(); 6 app.get('/', function (req, res, next) { 7 superagent.get('http://www.cnblogs.com/LIUYANZUO') 8 .end(function (err, sres) { 9 if (err) { 10 return next(err); 11 } 12 // sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后 13 // 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$` 14 // 剩下就都是 jquery 的内容了 15 var $ = cheerio.load(sres.text); 16 var items = []; 17 $('.day .postTitle2').each(function (index, element) { 18 var $element = $(element); 19 items.push({ 20 标题: $element.text(), 21 网址: $element.attr('href') 22 }); 23 }); 24 res.send(items); 25 }); 26 }); 27 28 app.listen(4000, function () { 29 console.log('app is listenling at port 4000'); 30 });
在命令行运行,得到截图
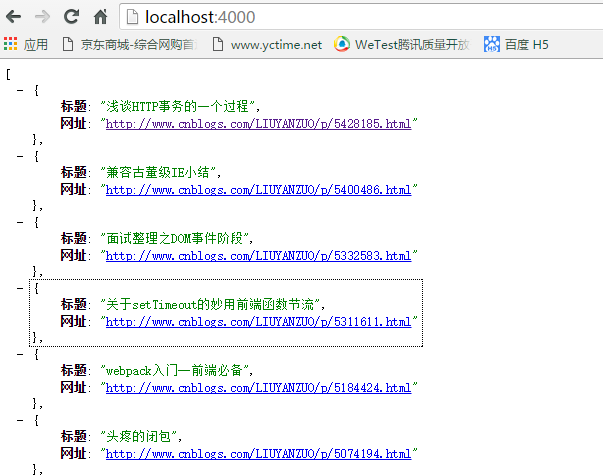
当然这是最简单的,下一篇我想介绍下node的异步并发。
https://github.com/LYZ0106/

