
ComfyUI进阶篇:ControlNet核心节点
前言:
ControlNet_aux库包含大量的图片预处理节点,功能丰富,适用于图像分割、边缘检测、姿势检测、深度图处理等多种预处理方式。掌握这些节点的使用是利用ControlNet的关键,本篇文章将帮助您理解和学会使用这些节点。
目录
一、安装方法
二、模型下载
三、Segmentor节点
四、Lines节点
五、Color Pallete/Content Shuffle节点
六、OpenPose节点
七、Depth节点
八、MeshGraphormer Hand Refiner节点
九、ControlNet示例工作流
一、安装方法
在ComfyUI主目录里面输入CMD回车。
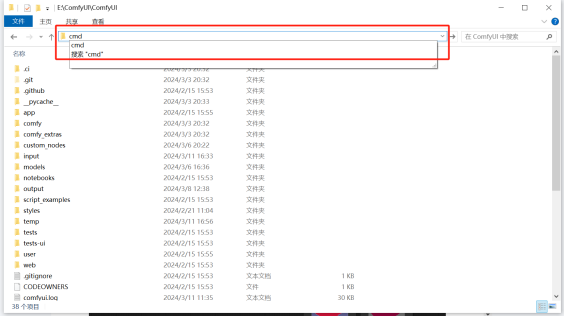
在弹出的命令提示行输入git clone +github下载网址,即可开始下载。

github项目地址:https://github.com/Fannovel16/comfyui_controlnet_aux.git
二、模型下载
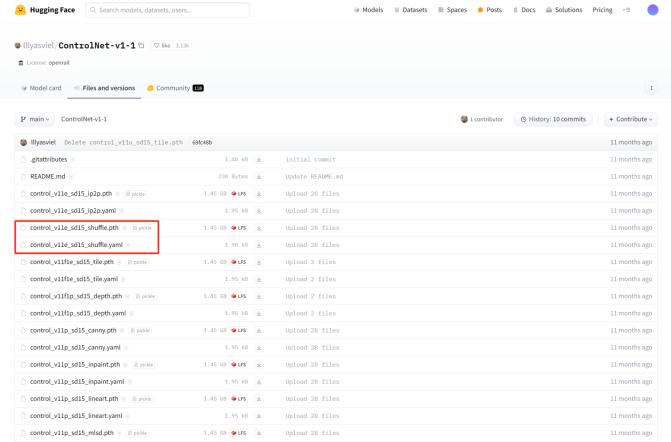
ControlNet-SD1.5模型下载地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
注意:模型下载需同时下载ControlNet模型和模型对应的配置文件(yaml)文件。
三、Segmentor节点
该节点是用来执行图像分割任务的,并用不同颜色标注出图像区域
添加节点:Anime Face Segmentor/ UniFormer Segmentor/ Semantic Segmentor (legacy, alias for UniFormer)/ OneFormer COCO Segmentor/ OneFormer ADE20K Segmentor
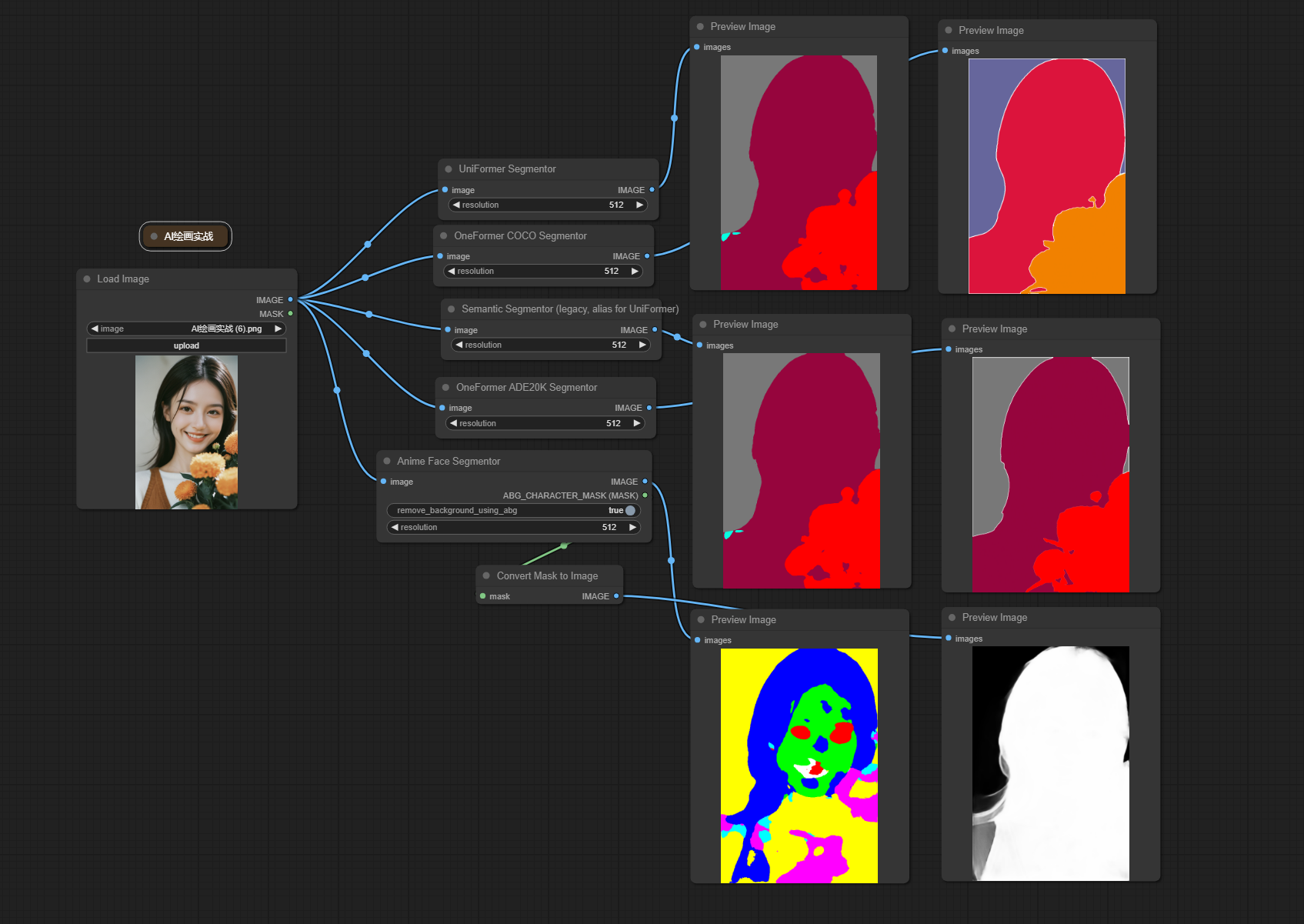
输入:
Image → 需要进行预处理的原始图片
参数:
remove_background_using_abg → 自动生成的二值化字符掩码,从图像中分离对象
resolution → 输出图像的分辨率 此值会影响最终的图像分割结果
输出:
IMAGE → 输出图像分割后的结果
ABG_CHARACTER_MASK(MASK) → 输出蒙版结果
注意:这些节点的使用会自动下载相应的模型,模型存放位置为:
..\ComfyUI\custom_nodes\comfyui_controlnet_aux\ckpts\lllyasviel\Annotators
通过使用 Segmentor 节点,用户可以在 ComfyUI 中方便地进行图像分割任务,从而在不同的应用场景中利用分割结果进行进一步的图像处理和分析。
四、Lines节点
该节点是一种用于检测图像中的线条或边缘的工具。
添加节点:Binary Lines/ Standard Lineart/ HED Soft-Edge Lines/Scribble Lines/ Anime Lineart/ PiDiNet Soft-Edge Lines/ TEEDPreprocessor/ Scribble XDoG Lines/ Canny Edge/ M-LSD Lines/ Fake Scribble Lines (aka scribble_hed)/ Manga Lineart/ Diffusion Edge/ Realistic Lineart/
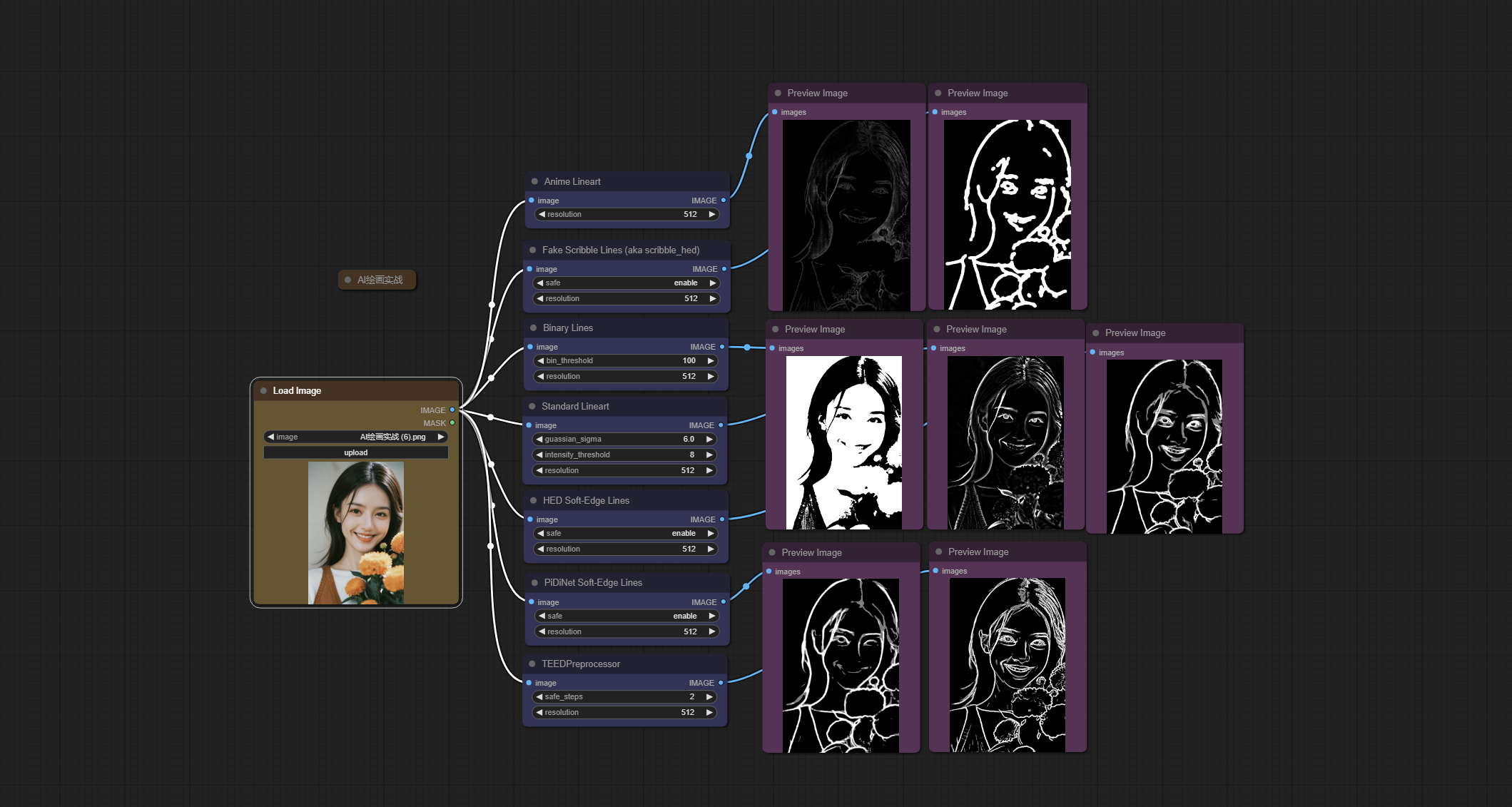

输入:
image → 需要处理的原始图像
参数:
bin_threshold → 表示阈值 该阈值会影响边缘检测效果,可进行更改尝试效果
safe → 该参数控制着 HED 算法中的行为 比如异常值处理,边缘链接等
guassian_sigma → 表示高斯滤波核 图像边缘检测前一般会进行降噪,此时用到高斯滤波核
patch_batch_size → 表示边缘检测时批次数量 图像一般会被分块进行处理,块成为patch
resolution → 表示输出图像的分辨率 该值会影响最终的检测效果
注意:这些节点的参数较多,上图的对比仅使用默认的参数进行跑图,具体的情况还需要大家进行多次尝试,上图效果仅供参考。
输出:
IMAGE → 输出图像的边缘检测信息结果
通过使用 Lines 节点,用户可以在 ComfyUI 中轻松实现图像中的线条检测,从而为进一步的图像分析和处理提供有价值的信息。
五、Color Pallete/Content Shuffle节点
在ComfyUI中,Color Palette 节点是用来提取图像中的颜色信息并生成一个颜色调色板的工具。Content Shuffle 节点是用来随机化或重排输入数据或图像内容的工具。这两个节点主要作用是保持图像的画风一致,配合shuffle的ControlNet使用。
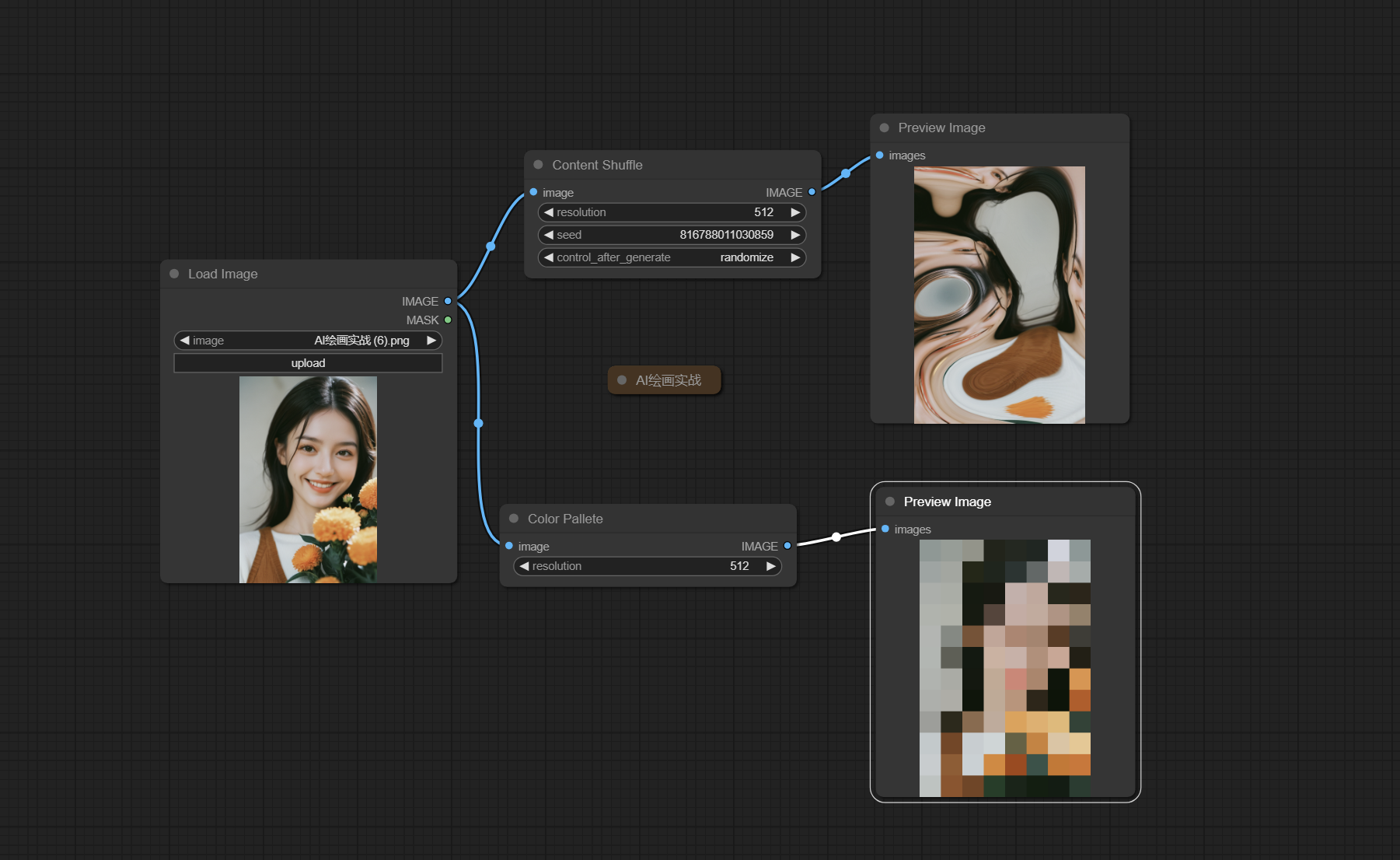
输入:
image → 加载原始图像
参数:
resolution → 表示输出图像的分辨率 此值的设定会影响最终结果
seed → 随机数种子
control_after_generate → 产生种子之后,以何种方式进行处理 递增,递减,固定
输出:
IMAGE → 输出处理之后的图像

·而通过使用 Content Shuffle 节点,用户可以在 ComfyUI 中轻松实现数据或图像内容的随机化或重排,从而为各种应用场景提供有用的工具和方法。
六、OpenPose节点
该节点是用来进行人体姿态估计的工具。
添加节点: AnimalPose Estimator (AP10K)/MediaPipe Face Mesh/ OpenPose Pose
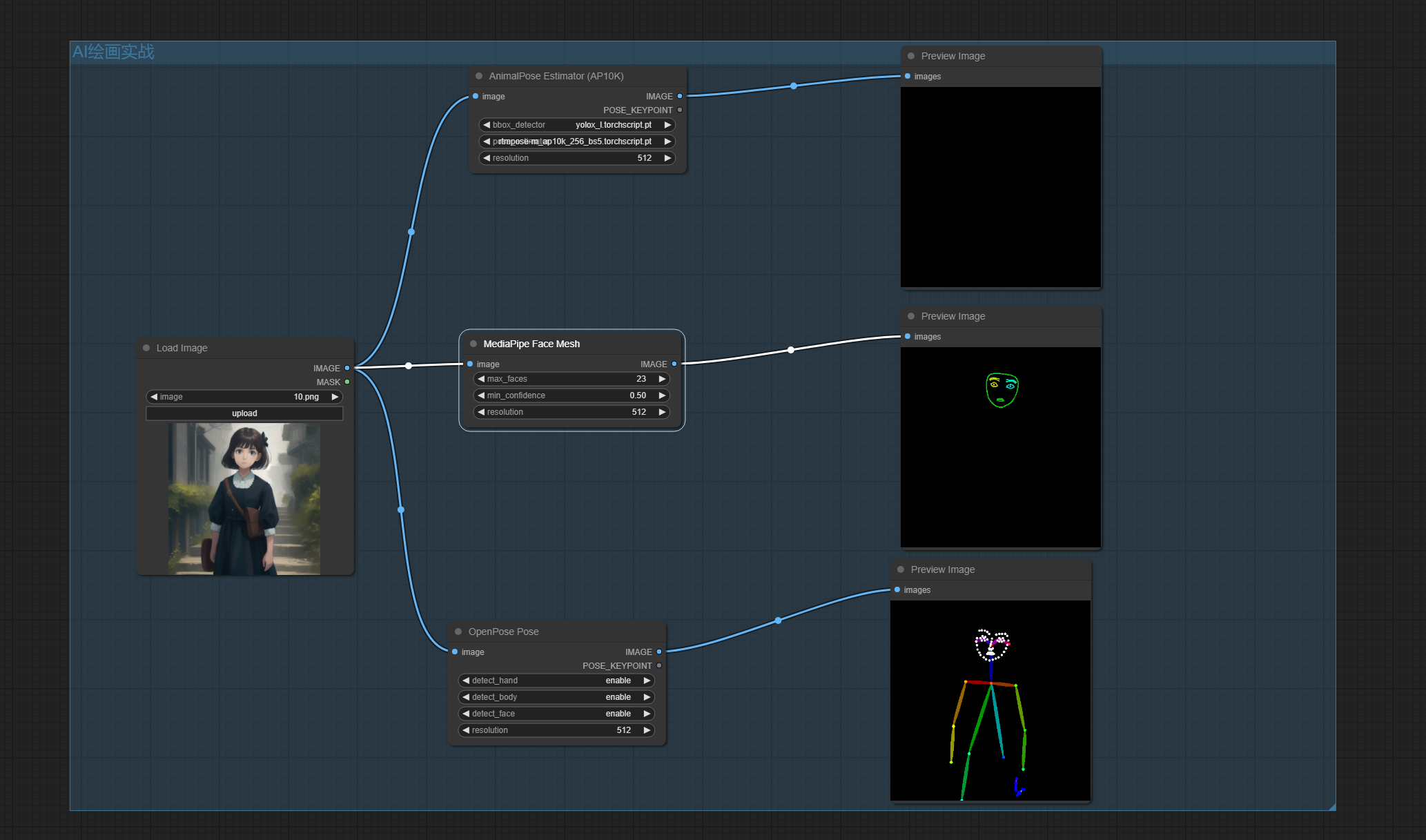
输入:
image → 接收一幅或多幅包含人体的图像作为输入
参数:
model → 选择进行检测的模型
bbox_detector → 加载探测框识别模型
pose_estimator → 加载姿势识别模型
max_faces → 参数用来指定一张图片最多出现人脸数量
min_confidence → 代表了模型对于检测到的人脸的最小置信度阈值。
注意:当模型检测人脸时会给出一个数值,当值低于min_confidence则认为不是人脸。
输出:
IMAGE → 输出检测后的图像
POSE_KEYPOINT → 参数可能包含姿势检测结果的坐标信息,通常以一个列表或数组的形式呈现。
通过使用 OpenPose 节点,用户可以在 ComfyUI 中轻松实现人体姿态估计,并将检测到的关节点和骨骼信息应用于各种计算机视觉任务和应用场景。
七、Depth节点
该节点是用于生成和处理图像的深度信息的工具。
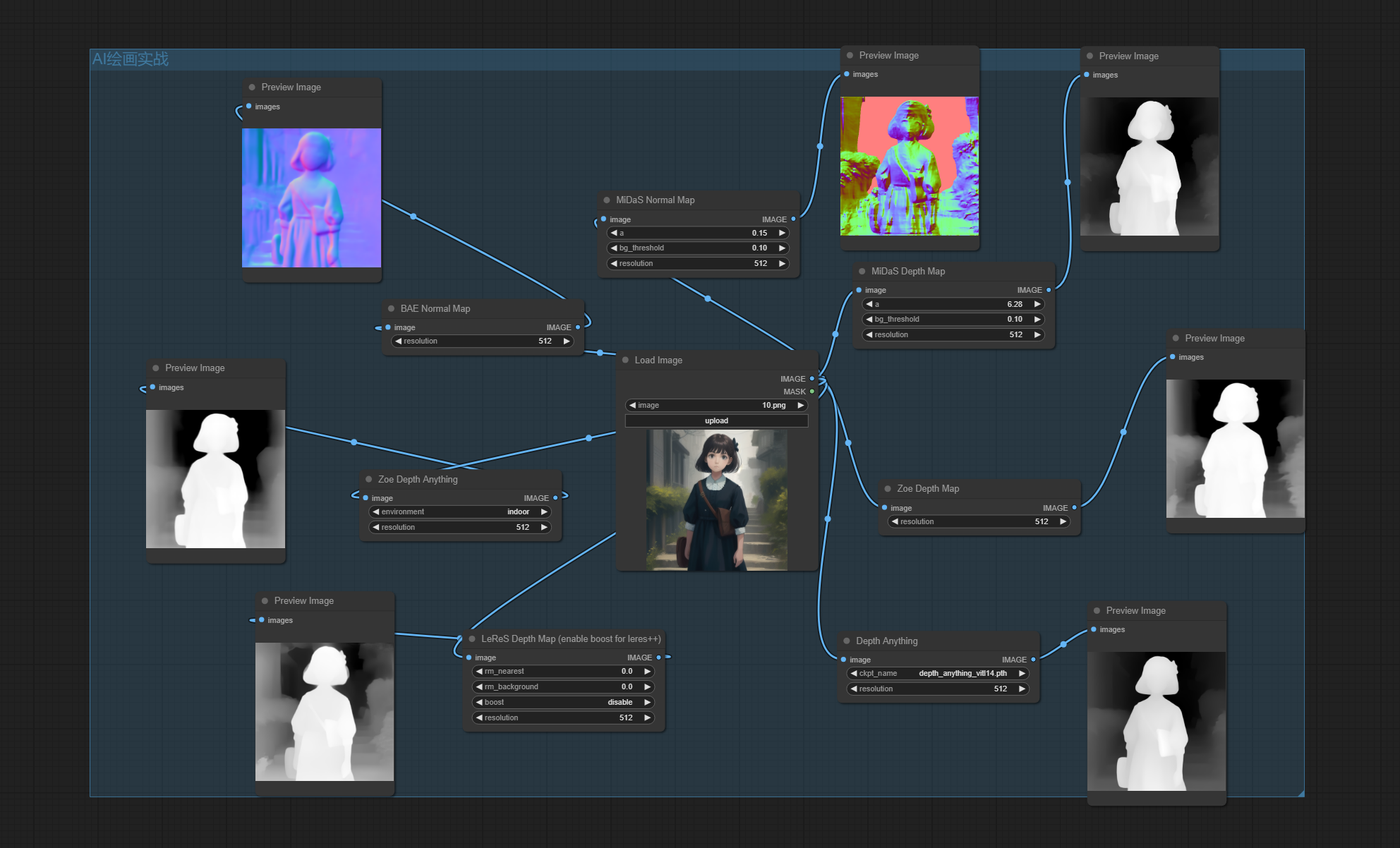
输入:
image → 输入原始图片
参数:
bg_threshold → 给出背景的阈值,以此值为基准进行背景分离
rm_nearest → 设置像素插值 该值主要针对主体
rm_background → 设置背景阈值 该值过大会使得背景无深度信息
boost → 是否开始深度图增强模式 开启,深度图会进行后处理,使深度信息更明显
resolusion → 输出图像的分辨率
输出:
IMAGE → 输出处理后的深度图像信息
通过使用 Depth 节点,用户可以在 ComfyUI 中轻松生成和处理图像的深度信息,深度图常配合depth的ControlNet使用,如下图所示的工作流,使用原图获得深度图信息,通过ControlNet指导模型进行扩散,最终生成与深度图吻合的图像。
八、MeshGraphormer Hand Refiner节点
该节点是一种用于精细化手部姿态估计的工具。它利用 MeshGraphormer 模型的强大能力,从图像中提取手部的精细3D结构信息。
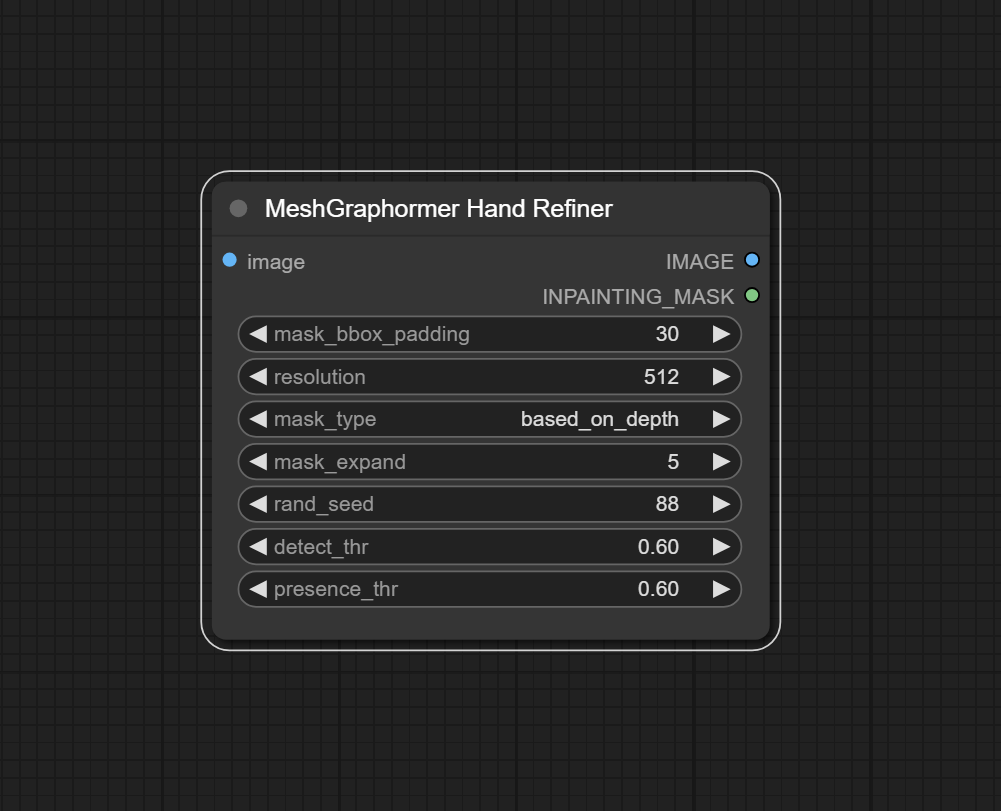
输入:
images → 接收输入的图像 需要包含手部信息
参数:
mask_bbox_padding → 输出的蒙版大小 该值只有在mask_type=original时起作用
resolution → 输出图像的分辨率
mask_type → 选择输出蒙版的类型
mask_expand → 蒙版区域扩大范围
rand_seed → 给出种子用来生成输出结果
输出:
IMAGE → 输出供ControlNet参考的预处理图像
INPAINTING_MASK → 输出对应手部的蒙版
通过使用 MeshGraphormer Hand Refiner 节点,用户可以在 ComfyUI 中实现高精度的手部姿态估计和精细化处理,为各种应用场景提供准确和详细的手部姿态数据。使用该节点生成对应的深度图信息和手部的蒙版,将深度图信息传入ControlNet用来引导模型扩散出指定的形状。
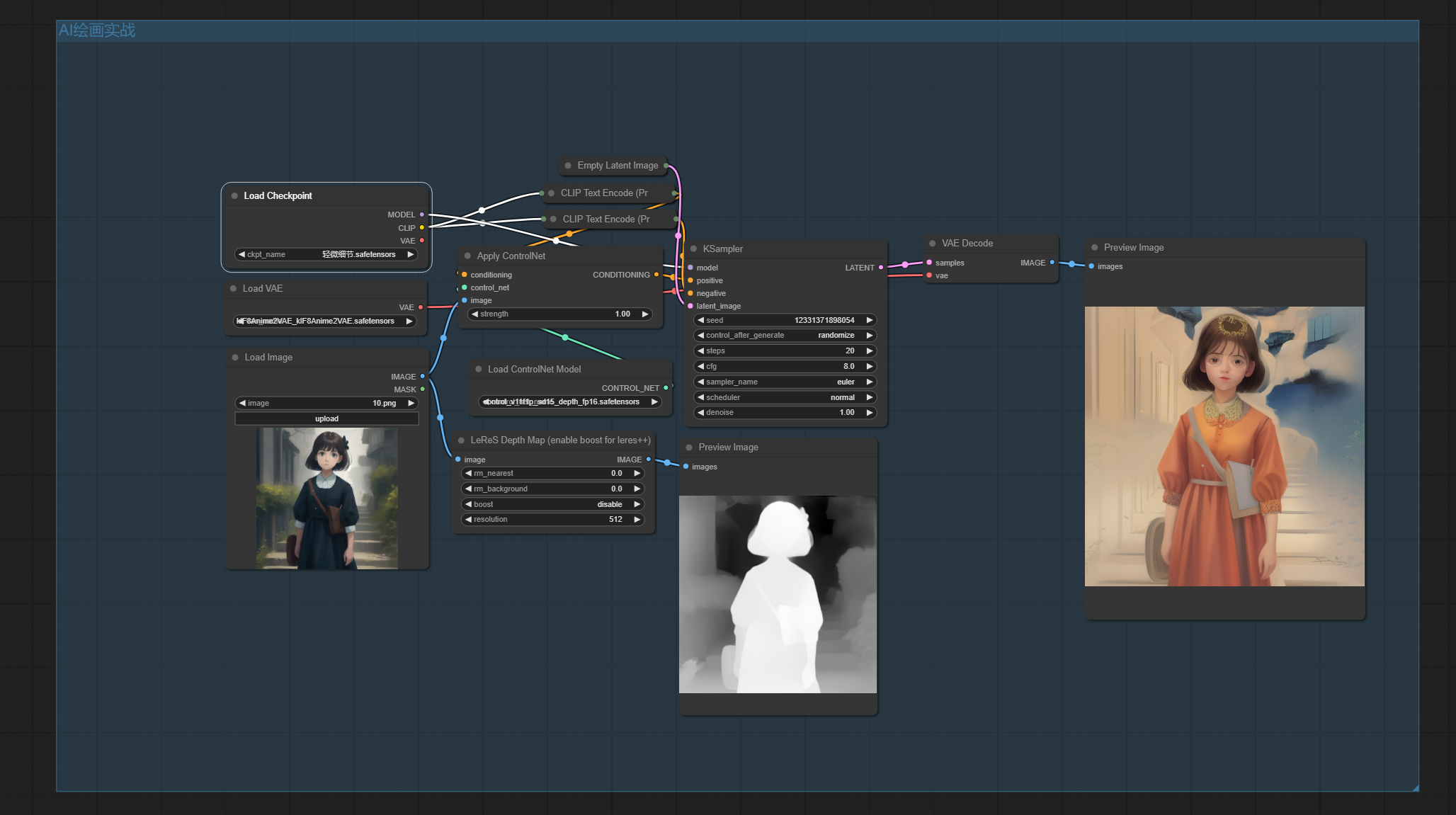
九、ControlNet示例工作流
熟练使用以上节点,你就可以搭建有关ControlNet的工作流了。
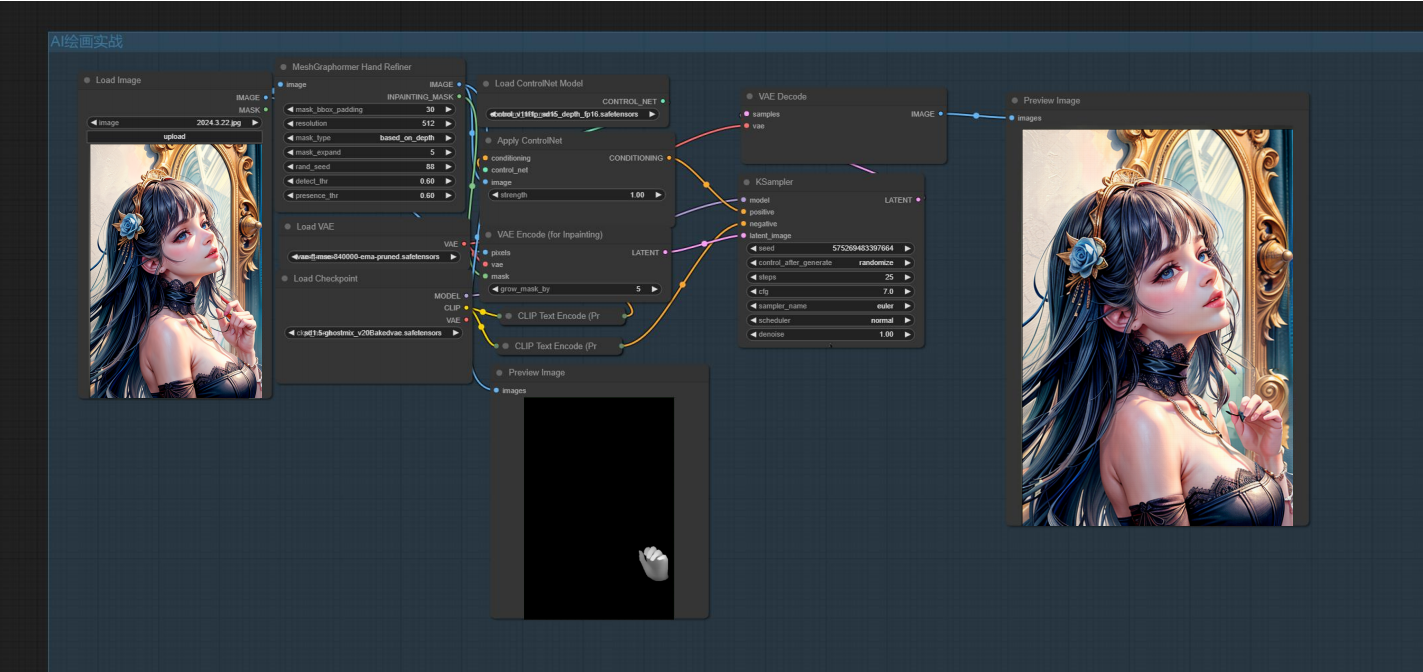
在这里,我们使用SD1.5的大模型,通过手部修复节点生成原图中人物手部的蒙版和修复所需的深度图。接下来,将深度图传入ControlNet以指导模型扩散,并使用Clipinterrogator节点对原始图像进行语义反推,从而修复人物的手部。最终,得到原图和修复后的图像。


孜孜以求,方能超越自我。坚持不懈,乃是成功关键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号